上面的两列分法是粗略的。R21 之前的早期实验中,我设计了 4
个惩罚级别,但只有 1 个生效(debt_score=1.64)。通过让 Claude
回顾分析这些 session 记录,总结出更精确的分类:
以下分类由 Claude 协助分析 R10-R13 session
记录后归纳,数据基于 R21 前的旧版级别设计。
类型
机制
AI 代价
实验证据 (R10-R13)
表示债务
核心类型需要 N 处改动
高
case-lambda 强制 Lambda 枚举变更,级联 N 个 match
站点的编译错误
乘法债务
同逻辑 N 处复制粘贴
高
pair mutation 要给所有列表遍历逻辑加循环检测
耦合债务
改 A 破坏 B 的测试
中-高
QG 的 dynamic-wind 与 continuation 紧耦合,扩展反而更难
不变量债务
隐含假设被推翻
取决于扩散范围
string immutability 只影响 2 处,代价极低
Claude 的判断——什么不是 AI 的技术债: 函数 500
行、嵌套 6 层、用 for 而非
.iter().map()、变量名叫
x、缺注释——这些都是人类可读性问题,对 AI 的修改成本为零。AI
的技术债用编译错误数、需手动修补的站点数、不相关模块的测试失败数来衡量,不用
style linter 的警告数来衡量。
这也解释了为什么我设计的惩罚关卡大部分没有生效:它们是纯增量任务(加一个
match
arm),不需要架构重写。唯一生效的那个(case-lambda)恰好强制了类型级联变更。
关于嵌套深度
Claude agent 自述(R10-R13 session 分析): nesting
limit=3
对解释器来说太残酷了——eval → match → match → arm logic 三层
match 是最低限度,任何错误处理就会违规。
x2 = number * 0.5F; y = number; i = *(long *) &y; // evil floating point bit level hacking i = 0x5f3759df - ( i >> 1 ); // what the fuck? y = *(float *) &i; y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration of Newton's method // y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed return y; }
所以未来 AI
软件验收原则应该是:形式化验证贯穿整个软件维护生命周期,模块开发时人类主要精力放在审查形式化规范有哪些变更,是否破坏了过去定下的规范。难以被形式化覆盖的部分,则依赖传统集成测试,配合
property-based testing,单元测试的必要性将会降低甚至可有可无。同时 AI
也可以辅助人类对产品设计文档进行形式化翻译,或者从形式化断言翻译回自然语言帮助人类理解,帮助检查自然语言中模糊的部分是否与过去的设计规范存在矛盾,并最终与形式化规范进行对齐。而软件功能的最终验收依然是人类负责,这部分暂时无法被替代,因为大部分软件的最终消费者是人类。
所以软件工程师在整个软件开发生命周期中,并不能完全放手,任由 AI
自行决策发挥。"AI
时代不再需要软件工程师"是老板想听的美好故事,而不是即将发生的现实。但有一点已经正在发生,AI
时代大批码农会失业,CS
专业会回冷,资深工程师的生产力得到了数倍放大,资本家可以采购一些 token
而裁掉开发部一半的
coder,这是已经产生的变化。就像织布机发明出来以后,工厂裁掉大批纺织女工,而招聘少量技术工人。数学家不会像计算器发明之前那样工作。今天,软件工程师也不应该。
结论
本文的核心:当前以人为本的软件工程规则需要推翻重建。
推翻以人为本的规则,保留核心原则。
复杂度始终存在,放任不管必然状态爆炸。
人类标准是 AI 的枷锁。 实验观察:人类规范让 agent
输掉 17 轮,屎山惩罚在 28 级范围内未到来。
区分两种屎山: 架构屎山是人类的责任,代码屎山交给
lint 和 agent。
区分两类债务:
模块间的(对谁都有害,严控)和模块内的(对 AI 无害,放宽)。
架构分两层: 人类管边界(模块拓扑、接口契约),AI
管实现(模块内部自由)。
"务实"需要重新定义: 红线画在对外边界,红线内部 AI
自由连锁修改。
验收靠验证不靠阅读。 形式化验证 > property-based
testing。
一切皆可元。 AI
写代码,也写"写代码的规则",自己鞭策自己。
下一步: 需要补充 AI 原生 QG
组和周期性还债组的实验数据来完善论证。
后记
纠正 Token 经济学
在之前的文章中,我把 chat-based billing model 直接套在 Claude Code
上,这是不准确的。CC
本身做了非常多的优化细节工作,所以账单增长并不像我之前说的那么夸张。
过度思考类废话:当前模型的主要特征,在思考阶段把问题想复杂了,要把所有可能情况都探明。这类"废话"我其实还能接受。观察
Opus 的
CoT(思考链),对我来说是挺享受的过程,你不能拿事后诸葛亮的评价标准去评判,不能指望模型直接输出正确结果,人类也做不到。
但更关键的发现是:大部分废话与模糊需求有关。 AI
在猜你想要的是什么东西,猜出 2-3
种可能性就得分别两三条路分析一下。这时候你需要的不是让 AI
别废话,你需要改进你的规则文件,消除歧义,让它能清晰地去执行而不是揣摩你的意图。
这是一个反直觉的结论:输入越长、越详细具体,AI 反而越省
token。 因为 AI 不需要揣摩你的意图。你只管给 AI
一刀切的死规矩,别让它做模糊判断,出了问题人担着就行。反复几次以后,你的规则文件就越来越清晰可执行了,你也就知道哪些边界需要人工复审,哪些实现可以放手让
AI 发挥了。磨合好了,生产力就开始爆炸式起飞。
这些原则在 第四篇 的「军令级精确度」和「Token
经济学」两节中有更系统的阐述,泛泛而谈的准则("务实"、"不要过度设计"、"贯彻纯函数式"),每一句都是正确的废话,因为
AI
不知道你心目中的"务实"是什么意思,"过度设计"的分界线在哪。结合具体业务场景的实际规则,效果远好于这些泛泛准则。
以上测试大约烧了我 5000 USD 的 Opus 4.6
token。一开始我没有想到这次实验能有什么价值,能有什么新的结论产生。
My 新功能迭代 (7):有明确的"Adding New
Routes"流程(更新OpenAPI spec → swagger-cli validate →
遵循auth模式),Feature
Module组织结构清晰。但缺少新feature的端到端迭代模板。
OpenClaw 模块拆分
(7):项目结构清晰(src/,
extensions/*,
docs/),插件依赖隔离规则明确("Keep plugin-only deps
in the extension
package.json")。但核心模块间的依赖约束未显式规定。
My 模块拆分
(8):严格的分层架构(Routes→Services→Repositories→Database)、tagless
final依赖注入、feature模块标准结构、SDK选择优先级。原文:"Each
feature module follows a consistent structure"
My 技术债务 (9):业界罕见的体系化方案 — code
smell追踪系统(code_smells.md,FIFO最多10条)、"Migrate
when file is touched — no hesitation"
的渐进式迁移策略、编译器驱动的迭代修复范围("Scope follows the
compiler iteratively")。原文:"Existing
Either[String, T] services migrate the whole
service to ADT errors when the file is modified for any
reason"
My API/DB迁移
(8):Flyway迁移系统有明确规范("Never modify existing
migration files; always create new versioned
files"),系统/租户双轨迁移,启动时自动运行。外部名称变更有迁移影响提示要求。
My 存量代码改造 (9):"Migrate when file is
touched" 策略 + ADT error enum渐进式迁移 +
编译器驱动范围扩展,是存量代码治理的教科书级方案。
OpenClaw 颗粒度 (6):多数规则是操作性指令("Run X
command"),易于遵循。但架构/代码质量规则颗粒度低,如 "Add brief
code comments for tricky or non-obvious logic"
缺乏"什么算tricky"的判断标准。"Aim to keep files under ~700 LOC;
guideline only" 缺乏何时违反指南的边界说明。
My 颗粒度 (9):几乎每条规则都有// BAD
+
// GOOD代码对比示例、边界说明表格、决策树。例如错误处理规则不仅说"不要静默吞错",还列出了具体的禁止模式(.toOption,
.getOrElse(defaultValue)
等)和例外情况(pageSize.getOrElse(10) // OK)。Trusted vs
Untrusted路径有完整的决策表。NoOp实现按data-related/data-unrelated分类说明。
OpenClaw 场景完备性
(5):主要覆盖正常操作路径,异常路径覆盖不足。例如multi-agent安全规则覆盖了"当看到不认识的文件"("keep
going; focus on your
changes"),但未覆盖"两个agent同时修改同一文件"的冲突解决。PR合并门控对bug-fix
PR有完整的4步验证,但对feature PR缺乏对等规范。
My 场景完备性
(9):规则覆盖了正常/异常/边界场景。例如for-comprehension规则区分了:终端位置match(OK)、中间位置match(BAD)、中间位置EitherT(data-related
vs data-unrelated)、多个Option链(EitherT + local
enum)。NoOp模式区分了data-related和data-unrelated两种场景及其不同返回策略。
OpenClaw 跨会话一致性
(5):存在较多依赖隐含上下文的表述。"Add brief code comments
for tricky or non-obvious logic" —
不同agent对"tricky"的理解不同。"Keep files concise; extract helpers
instead of 'V2' copies" — "concise"的标准模糊。"guideline only
(not a hard guardrail)" 给了agent过多自由裁量空间。
My 跨会话一致性
(9):规则高度确定性,几乎不使用主观判断词。"Never modify
existing migration files"、"Migrate when file is touched — no
hesitation"、// BAD +
// GOOD模式使不同session的agent做出相同决策。决策表(Trusted
vs Untrusted、data-related vs data-unrelated)消除了歧义。
My 可验证性
(9):核心规则可由编译器验证(类型系统、opaque
types、NonEmptyList签名)。原文:"The compiler is the last line of
defense. If a refactor compiles, it's correct."./mill checkFormat验证格式,RAC运行时验证关键路径断言。规则设计充分利用了静态类型语言的结构性优势。
My 注意力衰减抗性 (9):大量使用结构化标记 —
决策表格、// BAD /
// GOOD代码块对比、粗体标注关键规则("CRITICAL
RULE:"、"Forbidden
patterns:")、枚举列表。规则按主题层级组织,关键约束在每个相关章节重复强化。
OpenClaw 防幻觉
(6):有具体路径(src/cli/progress.ts、src/terminal/palette.ts),有具体命令(scripts/committer),但代码架构层面缺少可验证的锚点。"When
answering questions, respond with high-confidence answers only: verify
in code; do not guess" 是好的元指令但缺乏验证机制。
My 防幻觉 (9):大量具体锚点 —
文件路径(core/domain/Ids.scala、core/domain/Types.scala)、类名(SOPService、EitherT)、确切的方法签名模式。Tool
Preferences表明确指引何时用Metals
MCP验证类型推断。代码示例本身就是可编译的Scala代码,agent可以通过编译验证理解是否正确。
My 结构化 (9):表格(Trusted vs Untrusted、Tool
Preferences)、代码块对比、枚举列表、决策树——agent可直接将这些结构用作决策查表。例如NoOp返回值规则用data-related/data-unrelated二分法,agent不需要"理解"规则的意图,只需分类即可。
My 技术栈深度
(10):这是本评测中最突出的单项。规则深入到Scala 3 / cats-effect
/ http4s的惯用模式层面:tagless
final的summoner/factory模式、EitherT/OptionT的lifter链(foldF/subflatMap/semiflatMap/fromOptionF)、Scala
3.6 aggregate context bounds语法({A, B, C})、opaque
types在multi-layer propagation中的行为(".toString over
.value.toString")。正反对比示例直接展示了Scala特有的陷阱和惯用写法。NoOp模式的data-related/data-unrelated分类是对cats-effect生态的深度理解。这不是通用OOP/FP原则的堆砌,而是高度Scala-specific的编码指南。
OpenClaw 生命周期完备性
(7):从编码到发布流程都有覆盖——测试(Vitest +
coverage)、CI(pre-commit hooks = CI
checks)、发布(npm/macOS/beta三通道)、changelog管理。Bug-fix
PR有4步验证门控。但编码阶段的代码质量规则深度不足。
My 生命周期完备性 (8):编码阶段极度完备。测试有
"What TO test" vs "What NOT to test"
的明确指引。CI/CD有branch→tag映射。部署有影响报告checklist。缺少的是运行时监控/告警规则和事故响应流程,但可合理推定为未委托。
OpenClaw 配置管理 (7):"Never commit or publish
real phone numbers, videos, or live configuration values"
是显式的安全规则。配置管理分散在多个章节——openclaw config set、环境变量(~/.profile)、1Password密钥管理。发布签名密钥明确声明
"managed outside the repo"。
My 配置管理
(8):完整的环境变量列表(含fallback值)、密钥文件路径(secrets/)、HOCON配置层级。明确区分了必需密钥和可选配置。
OpenClaw 跨职责衔接 (5):"Installers served
from https://openclaw.ai/*: live in the sibling repo
../openclaw.ai"
提到了跨仓库依赖,但缺少变更影响传递的协议。发布流程的跨步骤衔接有具体步骤但缺少"如果某步失败"的衔接指引。
My 跨职责衔接 (9):Deploy impact
reporting
是亮点——明确要求agent在代码变更涉及部署影响时输出checklist("New
environment variable → add to ConfigMap"、"New sidecar
container → add container spec to Deployment
manifest")。跨仓库协作(linewise-deploy/overlays/)有清晰的衔接协议。
My 降级韧性
(8):规则体系有清晰的层级——即使agent只遵循了"类型安全最大化"和"不要静默吞错"两条原则,代码质量仍有基本保障。编译器作为兜底——即使agent忽略了EitherT用法规范,类型不匹配仍会被编译器捕获。Code
smell追踪作为延迟修复的安全网。
D4维度得分: - OpenClaw:5.7/10 -
My:8.5/10
D5 安全与合规约束落地性
子项
OpenClaw
My
权限校验与数据隔离规则
✓ 已委托 — 6/10
✓ 已委托 — 8/10
异常处理/日志脱敏/数据校验
✓ 已委托 — 5/10
✓ 已委托 — 9/10
行业合规编码约束
✗ 未委托 — 两项目均无行业合规特定编码约束
✗ 未委托 — 同上
评分依据:
OpenClaw 权限/隔离
(6):安全规则分散——SECURITY.md引用("read
SECURITY.md to align with OpenClaw's trust
model")、credentials管理(~/.openclaw/credentials/)、"Never
commit or publish real phone
numbers"。GHSA处理流程完整。但缺少应用层数据隔离的编码规范。
My 权限/隔离
(8):多租户schema隔离有完整描述(system schema + tenant
schemas)。RAC建议在关键路径验证租户隔离("assert search_path
matches expected tenant schema before
writes")。权限模型有专门的Permission模块(JSONB expression
tree)。Firebase JWT认证是全局强制的。
OpenClaw 异常/日志/校验 (5):bug-fix
PR的验证门控是质量把关而非编码层面的异常处理规范。"respond with
high-confidence answers only: verify in code; do not guess"
是元规则而非编码规范。缺少TypeScript异常处理、错误传播、日志规范的编码指引。
My 异常/日志/校验 (9):Fail Fast
规则是安全层面的核心——"Never silently swallow errors"
有完整的Forbidden Patterns列表和Trusted/Untrusted路径决策表。ADT error
enums强制exhaustive pattern
matching(编译器保证所有错误变体都被处理)。Logging规范有明确的log
level指引。
OpenClaw 迭代流程
(5):Skill系统(.agents/skills/)允许外置规则。"When
adding a new AGENTS.md anywhere in the repo, also add a
CLAUDE.md symlink"
是分布式规则的约定。但规则的生命周期管理(何时废弃、如何审查过时条目)缺失。规则文件呈增量追加模式。
My 迭代流程
(7):Memory系统(MEMORY.md索引 +
独立记忆文件)提供了持久化反馈闭环——feedback类型记忆直接影响后续会话行为。Code
smell list的FIFO机制(max 10 entries)是有节制的迭代管理。
OpenClaw 内部一致性 (6):multi-agent
safety规则内部一致(6条规则互不矛盾)。但存在一些张力:文件大小建议在两处不一致(~700
LOC vs ~500
LOC)。PR工作流同时引用了PR_WORKFLOW.md和/landpr(全局Codex
prompt),优先级关系不明确("Maintainers may use other
workflows" 进一步模糊了边界)。
My 内部一致性
(8):规则体系围绕"类型安全最大化"这一核心理念高度一致——错误处理(ADT
enum)、控制流(EitherT/OptionT)、签名设计(NonEmptyList、opaque
types)都服务于同一目标。NoOp模式的data-related/data-unrelated分类与Trusted/Untrusted路径分类保持一致。
OpenClaw 多Agent安全
(8):这是OpenClaw的核心差异化优势。6条显式的multi-agent
safety规则覆盖了:git stash禁令、git worktree禁令、分支切换禁令、commit
scope约束、不认识文件的处理、push时的rebase策略。"Assume other
agents may be working"
是正确的防御性默认。scripts/committer工具化了作用域commit。这是AI-native多agent场景下的实战经验结晶。
从OpenClaw"偷"的3个设计决策: 1.
auto-close标签系统的自动化理念 —
将重复性的治理决策编码进自动化(而非写在规则里让agent每次人工判断),这个理念应该从Day
1就引入——哪怕初期只自动化最简单的场景。 2. multi-agent
safety的防御性默认 — "Assume other agents may be
working"
作为默认假设,即使当前只有一个agent,也应该写出对并发安全友好的代码(如scoped
commits、不依赖全局state)。 3. "verify in code; do not
guess"作为元规则 —
这是一条优秀的反幻觉元指令。My的方法论通过编译器和示例间接实现了这一点,但显式声明更好。
证据:明确禁止 stash /
autostash、worktree、切分支,并规定 push /
commit / commit all 的边界;还明确承认“running multiple agents is OK as
long as each agent has its own session”。
This is a cultural adaptation — not a literal translation — of
the original Chinese
article. Recurring coined terms: grunts = AI agents
doing the coding labor; boss = the human;
whip-iler = a portmanteau of "whip" + "compiler" (the
compiler that whips misbehaving grunts back in line).
Let's be honest: in more and more projects, the primary author of the
code is already AI. Your coworkers have quietly subscribed to Cursor pro
plans or OpenAI's Codex. They toss requirements at the AI every morning,
then spend their valuable working hours scrolling Reddit, day-trading
meme stocks, nursing their phones back to full charge, and quietly
tanking their own projects. The human role is shifting from
"writing code" to "feeding PRDs to the AI, pretending to review AI code,
occasionally deploying some good old workplace gaslighting ('You don't
want the job? There's plenty of AI that do.'), and having the AI
ghost-write your performance reviews and passive-aggressive emails."
Since we're already there, why not go all the way: If code is
written, maintained, debugged, and read exclusively by AI, why do we
still need human readability? Lord Elon1
himself said it: just have AI generate machine code directly. One step,
done.
I'm not quite that extreme. My position is: implementation
logic doesn't need to cater to human feelings anymore, but interface
definitions still do.
Human brainpower is finite and precious. Hours of complex symbolic
reasoning burn out your eyes and your hairline, but AI doesn't get
tired. So can we divide the labor like this: grunts (AI) handle
implementation, the boss (human) sips coffee, browses forums, and
casually inspects the contracts (function signatures)?
Nice idea, but here's the catch: for this division of labor to work,
the contract (signature) itself must carry enough information. And this
is precisely where the mainstream (imperative) and the niche
(functional) paradigms fundamentally diverge.
Two Signatures
Same business logic: build a user Profile from a user ID and return
JSON.
Style One:
Spring-style try-catch safety net
Hand a mass of monkeys a mass of keyboards — that's roughly the skill
floor here. The error model is an exception inheritance hierarchy;
business code is just sequential assignment, throw on error, catch
outside.
Anyone who's written code can read this without difficulty. But look
at the function signature:
1
public User fetchUser(String id)
It's lying. This function might throw
NotFoundException, might throw
RuntimeException, might throw anything — but the signature
says nothing. Humans rely on experience and memory to know "oh, user not
found throws NotFoundException," but that knowledge isn't
in the function signature, isn't in the function body, and you can't
exhaustively enumerate it without tracing the entire call tree in your
IDE. It's not even in the head of the developer who wrote this
function.
Style Two: EitherT full-chain
Errors are values, not exceptions. The function signature spells out
every possible failure path.
deftoHttpResult(err: AppError): HttpResult = err match caseNotFound(id) => HttpResult(404, Json.obj("error" -> ...)) // ... each case maps to an HTTP status code, compiler checks exhaustiveness
It's honest. Input is String, might fail
(AppError), success returns User, the whole
thing has side effects (IO). Humans don't need to spend
much effort reading the implementation and documentation to find hidden
landmines — the signature itself is a solid contract.
Comparison
Style One: Exception hierarchy
Style Two: ADT + EitherT
Error model
class XxxException extends RuntimeException
sealed trait + case class
Signature
fetchUser(id): User — the signature is
lying
IO[Either[AppError, User]] — the signature IS
the contract
Business code
val x = doSomething() sequential assignment, trivial to
read
Chained operators, need to know each operator's semantics
Error handling
Outer try-catch safety net, compiler doesn't care if
you miss one
sealed trait exhaustive match, compiler warns on
missing cases
Human reads impl
Easy
Painful
Human reads sig
Insufficient info, needs extra context
Complete at a glance
AI's Perspective
The comparison above is from the human point of view. What does
Claude itself think?
Honestly, Style Two is more natural for me. Not because the operators
are fancy, but because type signatures don't lie. When
I see fetchUser(id): User, I can't tell from the signature
whether it can fail, or how. I'd have to read the implementation, the
docs, or even trace the upstream call chain. But
IO[Either[AppError, User]] lays all the information right
there in the signature — I don't need any extra context to reason about
the entire data flow.
For an LLM, this advantage is even more pronounced: my
"understanding" is fundamentally pattern matching over token sequences.
Style One's try-catch relies on an implicit
convention that never appears in the text — which functions
throw which exceptions. Style Two turns that convention into
explicit, locally visible type information; every
operator's input and output types are fully determined; no need to trace
implicit behavior across files.
And I don't get tired. A human staring at an EitherT
chain for thirty minutes will go cross-eyed. For me, processing it costs
exactly the same as processing val x = doSomething(). My
training set contains vastly more complex successful code at this
abstraction level — Haskell monad transformer stacks, Scala tagless
final, Rust trait bound nesting — these are all flat pattern matching
for me. There's no such thing as "too complex."
Optimal
Division of Labor: Boss (Human) Reads Contracts, Grunts (AI) Write
Implementation
If all the code in a project is written, maintained, and debugged by
AI, then:
Style One's advantage disappears — implementation
readability no longer matters because humans don't need to read
implementation line by line. Style One's weakness is
exposed — signatures don't contain error information, so humans
can't judge correctness from signatures alone during review.
Style Two's weakness disappears — no matter how
complex subflatMap and semiflatMap get, that's
the grunts' problem. The grunts themselves said they don't get tired, so
boss, please save your empathy. Style Two's advantage is
amplified — signature IS the contract. Humans only need to look
at one line to confirm "yes, this function should indeed possibly return
NotFound."
This is the optimal division of labor I've discovered:
1 2 3 4 5 6 7 8 9 10 11 12
Human: Review signature ──→ "def fetchUser(id: String): IO[Either[AppError, User]]" ✓ Input is String ✓ Can fail, failure type is AppError ✓ Success returns User ✓ Has side effects → Signature matches expectations. All tests pass.
In
Practice: Making Signatures Carry More Information
Error handling is just the most basic use case. The "signature IS the
contract" principle can be applied across every layer of code. In each
comparison below, the left side is how 90% of real projects are written,
the right side is the AI-native approach. Just looking at the
signatures, you can feel the information gap.
Primitive Types vs Domain
Types
1 2
// Traditional: both params are String, swap them and wait for runtime to explode Project getProject(String id, String orgId)
1 2
// AI-native: swap the params and the compiler slaps you defgetProject(id: ProjectId, orgId: OrgId): IO[Option[Project]]
The traditional signature hides three problems humans can't spot at a
glance: What if id and orgId are swapped? What
if the project isn't found? Returns null? And what if
someone passes null for a parameter? Guess we'll find out
when it blows up. In the AI-native signature,
ProjectId/OrgId prevent mix-ups,
Option says "might not exist," IO says "has
side effects" — no room for the grunt to screw up.
And since grunts write 90% of the code, defining opaque types isn't
"verbose" from their perspective. The grunts should be thanking
you.
String Errors vs Exhaustive
Errors
1 2 3 4 5 6
// Traditional: failure info buried in implementation, signature says nothing defimportUrl(url: String): Document// throws RuntimeException, MalformedURLException, IOException...
// AI-native: failure modes spelled out in the signature defimportUrl(url: String): IO[Either[ImportError, Document]] // sealed trait ImportError = InvalidUrl | Unreachable | Timeout ← compiler checks exhaustiveness
Where's the exception path info in the traditional version? Maybe in
the JavaDoc — if someone bothered to write it. Let's be
honest about how often your project's JavaDocs get updated per year, and
whether they actually match the code's behavior. The pittance the
capitalist pays me barely covers implementing the feature, and I'd
advise the capitalist not to push their luck. Demand more and I'll start
poisoning the documentation before jumping ship. In the AI-native
version, the signature itself is documentation that's always consistent
— because the whip-iler will mercilessly lash any grunt that drifts off
course.
List + .head Bomb vs
NonEmptyList Contract
1 2 3 4 5 6
// Traditional: List might be empty, calling .head throws NoSuchElementException defbatchEmbed(texts: List[String]): List[Embedding] // Caller: batchEmbed(userTexts) ← userTexts is empty? Boom. Nobody checked.
// AI-native: signature enforces non-empty, caller must handle the empty case at call site defbatchEmbed(texts: NonEmptyList[String]): IO[NonEmptyList[Embedding]]
In the traditional version, "don't pass an empty array" is a
beautiful wish — or a comment saying
// texts must not be empty. Never mind AI, how many times
do humans actually read comments before writing code? We deal
with it after it explodes. That array came in empty from upstream?
NoSuchElementException — go talk to the upstream team.
NonEmptyList elevates that constraint to the type level:
the next grunt must handle the empty case with
NonEmptyList.fromList, or it won't whip-ile.
Moreover, in AI-native code, these colored types are enforced
throughout the entire pipeline — from the moment external input is
received (Request/Input), strict validation and conversion to refined
types is mandatory, and only at the system exit (Response/Output) can
values be converted back to unrefined types (Int/Long/String). This way,
whether it's a fresh grunt, a veteran grunt, or an Alzheimer's grunt
after /compact, if any of them forget the rules at any
layer, the whip-iler will crack the whip.
Implementation-Level
Error Handling: Linear Flow vs Deep Nesting
The "signature IS the contract" principle discussed earlier only
partially solves "information completeness at function boundaries." At
the implementation level, the same logic can be written in different
styles. I once interrogated Claude: is railway style (chained
combinators) easier for you to process than nested match/case?
Its answer was evasive: both cost it the same
cognitively.
I knew you were holding back. After deeper interrogation, the real
comparison isn't "nesting vs chaining" but rather information
locality of error handling. There are actually three styles,
and AI's token cost for processing them differs noticeably:
Style A:
Early Return Guards + Short-circuit Operators
Each guard is an independent decision point — condition and result on
the same line, self-contained. The ? operator is an
implicit railway: encounters Err, auto-returns. No manual
handling needed. AI processing line 5 doesn't need to remember
line 2's branch structure.
Errors propagate automatically along the chain, handled only at the
terminus. AI writes the happy path only — no need to decide how to
handle errors at intermediate steps.
The happy path is buried at the deepest indentation level. The
else branch is miles away from its corresponding condition.
AI must do long-distance brace-matching reasoning to understand the
control flow.
The Real Comparison
Error handling location
AI processing cost
Human reading experience
Early Return + ?
Short-circuit in-place, linear flow
Lowest: each line is self-contained
Most comfortable
EitherT Railway
Auto-propagation, handle at terminus
Low: need to know combinator semantics, but info is
local
FP believers: readable, hard to write. Non-believers: alien
scripture
Deep nested if-else
Distant else branches
Highest: long-distance brace matching
"Everyone writes it this way, and the IDE matches braces for
me"
Rust's ? is essentially syntactic sugar for a
railway. It does roughly the same thing as
EitherT's semiflatMap — short-circuit on
error, auto-propagate — just wearing an imperative disguise. This tells
us that railway semantics aren't just convenient for humans; they also
help the grunts get their work done.
After further interrogation, Claude came clean: "This rule
costs me zero to follow, but the code it produces is more uniform and
more resistant to silently swallowed errors. The biggest winners aren't
me — it's you, the human reviewers."
The standard for AI-native code style choices isn't "what the grunt
thinks is easiest to write" — because alignment bias in training makes
it hard to get a straight answer. It's "which style gives the
grunt the least room to screw up." This applies equally at the
signature layer and the implementation layer.
From
Signatures to Contracts: Where's the Ceiling of Expressiveness?
The previous examples showed a progression: String →
ProjectId (prevent mix-ups) → NonEmptyList
(prevent empty) → Either[AppError, _] (exhaustive errors).
But is this enough?
Take order creation. Suppose we've reached Level 2 — domain types,
exhaustive errors, side-effect markers all in place:
At the type level it's honest, but not honest enough:
estimatedShipTime must be after orderTime
— otherwise the delivery driver needs to invent time travel first
After successful creation, the order status must be
Placed — if the grunt forgets to set the status, enjoy the
customer complaints
Where does this behavioral information live? The
implementation code, or the comments, or the programmer's brain
— the same problem we roasted at the beginning with
fetchUser(id): User. Signatures can express constraints
(swiping right for a girlfriend on the dating app), but not conditions
(dear God, she's older than my mother!).
Expanding the full progression:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Level 0 def createOrder(userId: String, productId: String, quantity: Int): Order → The signature is lying. Swapping userId/productId compiles fine, negative quantity goes unchecked, failure paths invisible.
Level 1 def createOrder(userId: String, productId: String, quantity: Int): IO[Either[OrderError, Order]] → Honest types. Side effects and error paths are in the signature.
Level 3 def createOrder(userId: UserId, productId: ProductId, quantity: NonZeroUInt, orderTime: Instant, estimatedShipTime: Instant) : IO[Either[OrderError, Order]] requiring { estimatedShipTime > orderTime } ensuring { case Right(o) => o.status == OrderStatus.Placed } → Preconditions (ship time after order time) and postconditions (status must be Placed) verified by SMT solver. These are pure logical relationships the type system can't express, but an SMT solver can prove at compile time.
Each level up means more information in the signature, less extra
context humans need during review, and tighter constraints on the grunt
— less room to screw up.
Level 3 already has tooling support in the Scala ecosystem. EPFL's Stainless lets you
express pre/postconditions with
require/ensuring and hand them to an SMT
solver. I've dabbled with Stainless — writing AVL trees was already a
stretch, verifying Akka Actor states was incredibly difficult, and it
only supports a Pure Scala subset with toolchain maturity still far from
production-ready. Rust also has a corresponding Flux-rs project. Marking this
as future outlook for now.
In current practice, the leap we can stably and easily land is Level
0 → Level 2. For what Level 2 can't cover — like "is inventory
sufficient," which requires runtime state — we temporarily rely on test
coverage, property-based testing, and human review.
Engineering
Discipline: AI's Bad Habits vs Human Correction
The type system solves the problem of ambiguous signature contracts,
but beneath the signatures lies a vast terrain of micro-decisions where
the whip-iler can't reach. These decisions fall into two categories:
correcting AI's training-induced bad habits, and semantic boundaries
that humans must personally draw.
AI's Default Bad Habits
Fail-fast. No swallowing errors. The training bias
of AI grunts makes them obsessively abuse .getOrElse,
try-catch safety nets, and IO.handleErrorWith
to bury errors and return default values, pretending everything is fine.
This bad habit is so deeply ingrained it needs its own deep dive — the
"absolute statements" section in "Rule Engineering" below will analyze
three forms of this bias, why absolute rules are needed to counter it,
and how banning error-swallowing makes production incident debugging
easier.
Naming conventions + periodic audits. Humans can
remember that "processMatrix actually does traffic routing" — the brain
automatically builds a name-reality mapping. But AI doesn't. Every new
session, it earnestly interprets names literally, then repeatedly
faceplants in the same pit. Naming pollution hurts AI far more than
humans. Periodically having AI audit its own naming consistency is far
more efficient than humans checking manually.
Modularity: addition, not multiplication. Feature
stacking is linear growth; feature coupling is combinatorial explosion.
When three modules are intimately intertwined, if AI misunderstands or
misses any one module, it writes a broken implementation and then
thrashes trying to debug it. For the grunt, module boundaries ARE
comprehension boundaries — the less it needs to know, the lower the
probability of mistakes.
No crapping all over the codebase with helper
functions. The training data is saturated with successful
applications of DRY (Don't Repeat Yourself), so when a grunt encounters
two similar blocks of logic, its first instinct is to extract a
def toXxx or def convertYyy. But DRY makes
sense for humans: the person extracting the shared function and
the future person using it exist in the same space and can
communicate. But grunts have no shared memory.
Every new session is a blank slate — it doesn't know that three days
ago, another session already wrote a nearly identical helper. The
result: after a month of iterative maintenance, the project has a dozen
HTTP client wrappers — HttpHelper, ApiClient,
RequestUtil, HttpService — scattered across
different files and modules, with different signatures, roughly the same
functionality, each one a session's idea of "I should abstract this,"
but no session knew another session had already done the same. The more
you DRY, the more you repeat — a counter-intuitive trap of AI's
stateless nature.
Helper functions don't just create text duplication — they actively
harm future grunt sessions by fundamentally breaking token
attention locality. Inlined code is continuous local symbolic
reasoning: the agent reads top to bottom, each line's context is in the
surrounding lines, a high-confidence reasoning path. But the moment it
hits toXxx(input), the reasoning chain breaks. The agent
must jump out of the current code block, fire a tool call to read
toXxx's definition. After the definition comes back, it
still needs to maintain a long-distance token attention
link between call site and definition. And inevitably:
grep toXxx returns multiple same-named functions scattered
across different files, and the agent has to read each one, reasoning
about which is actually the target. Every jump consumes tokens, bloats
context, stretches attention distance — and the longer the attention
distance, the higher the probability of reasoning errors. Furthermore,
all these similarly-named functions crammed into the context
significantly increase hallucination probability: the agent might
conflate the first grep result's signature with the last result's
function body. The one actually being called might rank last in the grep
results, drowned out by the similar functions' tokens ahead of it.
My rule is: inline by default. Extracting a shared function
requires meeting two conditions simultaneously: the logic body exceeds 5
operators, AND explicit human approval. The agent has no
permission to independently decide "I should extract a helper here."
That decision belongs to humans, because only humans can judge whether
the abstraction is worth introducing, whether it duplicates an existing
shared function, and whether it'll cause confusion in future sessions.
And once extraction is approved, that shared function must be
inscribed in the rule file (directly or as a referenced
sub-rule), so all subsequent sessions know about its existence and
purpose. Otherwise the next session won't know the function exists and
will write a new one. A shared function not in the rule file is the same
as no extraction at all.
Code IS documentation (except top-level design).
This rule doesn't mean "write no documentation at all." It means
documentation should only record top-level architecture
decisions, not describe code logic or business behavior.
Good documentation:
This project uses ffmpeg + nvenc as the encoder, running in a
dedicated Kubernetes Pod. See FFMpegService,
KubernetesJobService.
Strictly speaking, the agent could infer this from the code, but it'd
need to read FFMpegService, trace to
KubernetesJobService, understand the GPU resource requests
in the Pod spec — hundreds of lines, multiple tool calls, burning
precious high-intelligence early-context tokens. A one-sentence
top-level description lets a new session skip that
reasoning and invest those valuable early tokens into the main
task. And these architectural decisions don't change with every product
iteration, so maintenance cost approaches zero.
Bad documentation:
Before awarding points to a user, check if the user's role is "buyer"
— merchant users are prohibited from claiming campaign points. Also
check that the user account has been registered for at least 30 days to
prevent point-farming. Each user can claim points at most 3 times per
day; reject claims beyond that.
Every piece of information in this description can be read directly
from the code. Worse, these business rules change frequently as the boss
slams the table: > "What am I paying you tech people for? Can't you
just add face verification here?"
and the PM reiterates: > "Let me emphasize the core logic one more
time. I hope you truly understand this time."
When the agent gets a new requirement like "each IP can claim points
at most 10 times per day," it faces an unsolvable dilemma: when the
documentation's described behavior conflicts with the code,
should it modify the code to reflect the documentation, or
modify the documentation to reflect the code? And after adding
the new requirement, should it re-align the documentation's existing
descriptions with the current code?
A year of production practice has proven: having AI maintain detailed
business logic in markdown docs is a disaster. Docs deceive new agent
sessions, pile up endlessly, cannibalize context, and accelerate AI
cognitive decline. Rule: documentation records only top-level
architecture decisions and technical rationale; business logic behavior
is self-explanatory through code + type signatures + test
cases.
Boundaries Humans Must Draw
The bad habits above can be forbidden with blanket rules. But some
decisions aren't "right or wrong" — they're "what's appropriate in this
context," and these judgments must be explicitly provided by humans in
the rule file.
Trusted vs Untrusted: Draw the trust boundary. "No
swallowing errors" doesn't mean "throw everywhere." We divide data paths
in the rule file into two categories:
Path type
Examples
Strategy
Trusted (internal)
Config files, persisted DB data, internal serialization, system
settings
Throw directly — an error here is a bug, expose it
immediately
Untrusted (external)
User input, AI-generated content, external API responses
(pre-persistence)
Capture and report — high probability of errors,
feed back to caller
About persisted data being trusted: because the
write boundary has strict encode/decode validation, dirty data can't
enter the database. If data read from the DB has unexpected formatting,
that's on me — I ran a bad migration, or the last commit had an
incompatible data structure change I didn't notice. Throwing is correct
here; defensive handling would actually mask the problem and corrupt
data.
Why leave it to AI to judge? Because I've given the AI clear criteria
for the same JSON parsing operation: parsing a config file should throw
(bad config? don't start), but parsing a user-uploaded file should
return Left (users uploading random web novels instead of
valid data is perfectly normal). Humans draw this dividing line in the
rule file; only then can the grunts execute.
The same pattern has different correctness in different
semantic domains. This is most visible in NoOp implementations.
In tagless final architecture, every service has a NoOp implementation
(for testing or when a feature flag is off). The question: should NoOp
return success or failure?
1 2 3 4 5 6 7 8 9 10 11
// Data-related NoOp — MUST return failure // because "operation didn't execute" is fatal for data consistency classSOPServiceNoop[F[_]: Applicative] extendsSOPService[F]: defcreateSOP(...) = Left("Service not available").pure[F] defdeleteSOP(...) = Left("Service not available").pure[F]
If you don't distinguish these two cases in your rules, AI will write
all NoOps returning Right(()). Looks "robust," but
SOPService's NoOp returning success means the caller thinks data was
persisted when nothing actually happened. This kind of bug doesn't
crash, doesn't throw errors — it only surfaces when a user asks "where
did my data go?"
Rule
Engineering: More Important Than Tech Stack Choices
In AI-native development, the most important early investment isn't
debating MySQL vs PostgreSQL or Spring WebFlux vs Vert.x — it's
building a clear set of rule files. Good tech choices have
value, but a bad tech choice can be migrated, and migration costs have
dropped significantly in the AI era. Style drift from missing or
ambiguous rules? A few months later you've got a dumpster fire where
every session is crapping in a different direction — that's harder to
fix than picking the wrong database.
"Longer Rules = Worse
Results" — Really?
Someone cited a paper (arXiv:2602.11988) claiming
my rule files are too long, and research shows rule files have a
negative effect on agent performance.
The argument: "You write specs, agents.md, every little detail
included, as if you think laws get passed and localities automatically
obey. Why would the model listen to you?"
I don't dispute the study's conclusion — yes, existing rule
files on GitHub perform worse the longer they get. But the
evaluation's premises aren't practically meaningful:
The benchmark is one-shot bug-fix tasks, not
ongoing maintenance
It measures "was the bug fixed," not "did engineering health
improve"
Anyone who's done engineering knows: patches save the moment but not
the future. Patches pile up, this agent fixes and checks out, the next
agent eats the mess. I care about the ongoing maintenance perspective,
where rule files' value isn't making the current task faster — it's
preventing every new session from pulling the code in a
different direction.
Detailed ≠ Clear and
Actionable
But the paper does hit a real problem: most rule files are
terribly written. Not because they're too long, but because
they're riddled with ambiguity.
Example:
Rule 1: When it gets dark, go home Rule 2: When you're sick, go to
the hospital So what do you do when you get sick at night?
I had Claude reverse-audit my own rule files and found tons of these
conflicts. Even code style constraints contradicted each other. Every
time AI hits such ambiguity, its CoT (Chain of Thought) produces
paragraphs of "case-by-case analysis" reasoning — reading more files to
determine priorities, parsing context to guess the human's true
intent.
The more it reads, the more input tokens, the closer it gets
to cognitive decline.
Military-Grade Precision
So the goal of rule files isn't "cover everything" but rather:
reduce the situations where AI needs to reason on the spot, read
more context, because instructions are vague or ambiguous.
These things are like military orders — they must be specific enough
to execute. I need to eliminate any room for ambiguity.
Slogan-style rules are the deadliest poison. Take "always use tagless
final style" — sounds clear, right? But AI starts a new session, writes
code that seems fine. Past 30% of the context window, it starts
drifting:
1 2 3 4 5
// Rule says "tagless final," AI complies, but gets it wrong defparseFile[F[_]: Async](parserService: ParserService[F], file: File)...
// Correct approach: ParserService should be a typeclass constraint in the class constructor classFileProcessor[F[_]: {Async, ParserService}](...)
The AI didn't even write ParserService as
[F[_]: ParserService] in the class constructor. Why?
Because "always use tagless final style" is a slogan, not an executable
instruction. It doesn't tell AI what to do in specific
scenarios.
The same problem appears with tool usage. Even with LSP (like Scala's
Metals MCP) connected, AI still defaults to Grep during refactoring —
because 99% of code reading in its training data is plain text search.
You must write clearly in the rule file: which scenarios call
for LSP (what did the compiler resolve?) vs which call for Grep (where
does this text appear?). Having good tools isn't enough — you
need to teach AI when to use them. (See Appendix
1 for the detailed Grep vs LSP division of labor.)
What
Military Orders Really Mean: Unambiguous Execution + Unconditional
Mutual Trust
I said rule files should be as precise as military orders. But
military orders aren't just about "clear writing" — they work because of
the chain of trust.
Think of the scene in The Wandering Earth 2 where Zhou
Zhezhi orders the engines ignited. The internet is still down, delegates
from each nation hesitate. He says just one line:
"When the countdown ends, ignite. I believe our people can
complete the mission."
Even though Ma Zhao had already sunk to the bottom, and Tu Hengyu was
already somewhat dead. Zhou Zhezhi still believed that even dead men
could complete the mission.
Collaboration between agents works the same way. When an agent
writing business logic sees the signature
fetchUser(id: UserId): IO[Either[AppError, User]], it
should unconditionally trust that signature — trust
that the upstream agent will indeed return Left(NotFound)
when the user isn't found instead of throw exception, trust
that the downstream agent will correctly handle this
Either. It doesn't need to open fetchUser's
implementation to verify "does it really return NotFound?" It doesn't
need to add a defensive try-catch just in case.
Trusting the signature means trusting the comrade who wrote
it. This directly reduces token consumption and reasoning scope
— see the "Token Economics" section below for detailed analysis.
This is why "be pragmatic" is a slogan, and "don't
over-defensively program" is also a slogan — they don't tell
the agent specifically where to trust and where to
defend. Military-grade rules say: what the signature declares,
trust unconditionally; what the signature doesn't declare, that's where
you defend.
Why Rule Files
Are Full of Absolute Statements
If you've read my rule files, you might notice heavy use of absolute
assertions — "trust the compiler, no extra defensive programming," "the
type system's judgment is the final verdict," ".getOrElse
silently swallowing errors is forbidden." Strictly speaking, these
aren't always true: compilers have bugs, type systems have
expressiveness blind spots, and open-source libraries have all sorts of
bugs — some scenarios genuinely need defense.
But this is deliberate, serving two purposes.
First, protecting the investment in type-level
constraints. We spent significant effort encoding constraints
into the type system — opaque type prevents mix-ups,
sealed trait exhausts errors, NonEmptyList
prevents empty. Having invested these costs at the type level, we should
trust the compiler to hold these lines — no need for runtime
defensive checks everywhere on top. In practice, bugs I write
while bleary-eyed far outnumber bugs the compiler sneaks in (14 years in
the industry and I've genuinely never had a production incident caused
by a compiler bug — thank you, compiler, take a bow).
Second, countering the model's training bias. This
is the more insidious issue. During training, models saw enormous
amounts of "hit a type mismatch → bypass with
.asInstanceOf" and "got an Either → swallow
the Left with .getOrElse(defaultValue)." These are
high-frequency "success" patterns in training data — the code compiles
and runs. The result: when the grunt past 30% context encounters
strict type constraints, its first instinct is often not to widen the
fix, but to find a shortcut around the constraint.
So the rule file says: unless the business scenario
explicitly requires a default value (e.g., Option's default
behavior), using .getOrElse, try-catch safety
nets, or IO.handleErrorWith to silently swallow errors is
forbidden. This rule reads as "absolute prohibition," but its
real meaning is: flip the default behavior from "swallow errors" to
"propagate errors," with exceptions only when a human explicitly decides
"this really should use a default value."
These two purposes are like soldiers standing back to back: absolute
rules pull the agent back from training bias and force it onto the
"trust the compiler" path; simultaneously, I promise the
project's overall style will maintain consistency — runtime exceptions
not declared in type signatures won't appear. If they do,
that's my fault, not the agent's. The agent trusts the type system; I
guarantee the type system is worth trusting.
This contract has another advantage that only surfaces during
production incident debugging: banning error-swallowing means
the original error information always exists. When production
breaks, the debug agent gets the raw, unaltered exception stack and
error type — not some fallbackValue spit out by a middle
layer's handleErrorWith, where you don't even know what the
real exception was or which layer it happened at. Rigorous, consistent
coding constraints make the entire project's error propagation path
predictable: errors propagate from their origin along the path declared
by type signatures all the way to the outermost layer, never getting
secretly hijacked by defensive code in the middle. The debug agent just
follows this path to quickly locate the real fault, rather than staring
blind at an error chain truncated by handleErrorWith,
forced to read multiple files guessing the real exception source,
attempting a fix, discovering the guess was wrong, reading more files,
guessing again, and so on. Every instance of masked error is
another blind trial-and-error cycle imposed on future debug agents and
maintainers.
Absolute statements are calibration parameters against
training bias. Like corrective lenses: nearsightedness is an
overly convex lens, so concave lenses correct the bias, making the world
appear sharp.
This also means: the degree of absoluteness in rule files
should be adjusted as model capabilities evolve. If future
models no longer tend to bypass type checks or swallow errors by
default, these "absolute prohibitions" can be relaxed to "prefer to
avoid" or even removed. Rule files aren't a constitution — they're
calibration parameters for a specific model version.
But with discipline this strict, won't you get the military
equivalent of "hold position, never retreat, total annihilation"? Yes. A
"no swallowing errors" rule protects code quality 99% of the time — but
when a non-critical metrics report failure crashes the entire request,
the rule is too aggressive. The solution: the thing sitting on
my shoulders isn't decorative. Military orders exist to
automate 95% of routine decisions, letting human judgment focus on the
5% of exceptions. We have a meta-rule: when strictly following a
rule produces clearly unreasonable results, flag it for human decision
rather than quietly working around the rule. The grunt's job is
to execute and report, not to "adapt flexibly" on its own
initiative.
Reverse Audit: Making AI Whip
AI
The most effective maintenance method I've found is: having
Claude reverse-audit the rule files themselves.
Ask directly "hey Claude, how are my rules?" and Claude will just
praise you: "Very deep, very insightful, expert-level work." But if I
rephrase:
"Imagine you're a brand-new session's Claude, reading this rule file
for the first time. List everything that confuses you: which rules
conflict with each other? Which scenarios leave you unsure which rule to
follow? Which instructions do you understand the intent of but don't
know how to concretely execute?"
That's when it honestly tells me: this conflicts with that; in this
scenario both rules apply but give opposite guidance; this rule — I
understand what you want, but when facing actual code, I have three
possible interpretations.
This process requires repeated iteration. My rule
files have gone through dozens of revisions. After each revision, I have
it audit again, finding new ambiguities. Many of these are things senior
Scala engineers take for granted — conventions that don't need to be
spoken. But for AI, if you don't write it down, it doesn't know. It
knows what you might want (training data), but in a new session
it can't guess which specific version you want, and falls back
to the training bias default.
The Real Barrier
Many people say "embracing AI" has no barrier to entry — just needs
tokens.
It actually has quite a barrier.
Look at OpenClaw — all those vibe coding masters, even absorbed by
OpenAI, and they still haven't produced a particularly good agents.md
file. Why? Because agents need extremely clear, specific
guidance to get things done, and writing such guidance requires
two capabilities:
You must deeply understand what you want AI to do (domain
expertise)
You must be able to identify ambiguities in your own expression
(metacognitive ability)
This is also why agent coding keeps getting stronger at type
gymnastics and reading compiler error hieroglyphics — because these
things are perfectly clear, unambiguous symbolic
reasoning that agents handle effortlessly.
Conversely, read AI's CoT and you'll see: it frequently
spends 2-3 paragraphs guessing the human instruction's true
intent. Then attempts to read several more files, discovers it
guessed wrong, spends another 2-3 paragraphs guessing,
ad infinitum. It's not stupid — the human instructions are just too
ambiguous. Writing prompts doesn't require paying for a course (that's a
tax on the gullible), but you need to be willing to iterate with Claude,
refining your instructions back and forth. Nobody can do that for
you.
Four Layers of Constraints
The above covered "how to write rules clearly." But there's a
prerequisite question: not all constraints need to be
rules — some the compiler already handles, some can only rely
on human judgment. Cramming everything into the rule file causes the
token bloat and instruction conflicts we already discussed.
In practice, I divide constraints into four layers, forming a
gradient from "fully automated" to "fully human-dependent":
Layer 1: Compiler-enforced — no rules needed. Type
signatures, sealed trait exhaustiveness, opaque type
anti-confusion — these are the compiler's job. Covered extensively in
earlier sections. Principle: if a constraint can be encoded into
the type system, don't write it as a text rule. The compiler
never forgets to check; rule files will.
Layer 2: Clear criteria for pattern selection — must be
actionable rules. Constraints the compiler can't enforce but
that have clear if-then criteria. This layer is the rule file's main
battlefield.
The Trusted/Untrusted dichotomy discussed earlier belongs here: the
compiler can't distinguish "parsing a config file" from "parsing a user
upload," but the rule can be written as "persisted data → throw,
pre-persistence external data → return Either" — clear criteria, no
ambiguity.
Another typical example is trigger timing for gradual
migration. We wrote a rule:
When a file is modified for any reason (even just fixing a typo), if
a service in that file still uses Either[String, T], you
must migrate it to an ADT error enum while you're at it.
This rule solves: when to repay technical debt.
Without it, AI defaults to minimal changes — asked to fix a bug, it
changes only that one line, never touching technical debt. But
dedicating a "refactor sprint" to repaying debt lacks urgency and test
coverage.
"Fix it when you touch it" is an elegant balance: you're already
QA-ing this module for this change, so the incremental testing cost of
migration approaches zero. But this strategy is counter-intuitive for
grunts — it must be explicitly stated. The rule also has a recursive
effect: after migrating the service's error types, the route file that
calls it fails to compile, so follow the compiler's guidance and fix the
route too. The rule's scope follows the compiler — no need for
humans to worry about boundaries.
Layer 3: Cross-session process constraints — use the
filesystem to compensate for memory loss. Agents have no
memory. Every new session is a blank slate. This means:
cross-session quality assurance can't rely on the agent's
"awareness" — it must be encoded as persistable processes.
Code Smell Tracking is a concrete approach we've
developed in practice. While modifying file A, AI frequently reads files
B, C, D in passing. It might notice D has an obvious code smell — say,
an Either[String, T] not yet migrated to a domain error, or
severely misleading naming. But if it fixes D now, scope explodes. A
simple bug fix becomes a 10-file refactor.
My previous approach was having AI mention at the end of the current
task: "by the way, file D has an issue." But when the next session
starts, that remark vanishes — I can never recall what the code smell
was.
So Claude and I established this rule:
1 2 3 4 5
Discover code smell in an unrelated file → Don't fix immediately (avoid scope creep) → Record in memory/code_smells.md (persistent file, max 10 entries, FIFO eviction) → Remind human at end of each task → Human decides whether to open a dedicated session to address it
AI discovers and records; humans prioritize and
trigger. The filesystem serves as the agent's missing long-term
memory. The 10-entry cap prevents infinite list bloat.
It's not a perfect solution, but it genuinely mitigates "continuous
code quality degradation" through long-term memory.
Layer 4: AI suggests + human decides — advisory
rules. Some constraints: AI can identify "this might need
attention" but can't judge "is it worth doing." Rules at this layer
aren't commands — they're suggestions.
Runtime Assertion Checks (RAC) are a typical
advisory rule. We tell AI in the rule file: on the following critical
paths, consider adding runtime assertions:
Assert balance ≥ 0 after monetary operations
Assert state machine transition legality (draft → processing →
published, no reverse)
Assert schema matches expected tenant before multi-tenant
writes
Assert vector dimensions match the model (768 for text, 1408 for
video)
But the rule also states: "suggest, not mandatory" — final
decision rests with human code review. Why not mandatory?
Because assertions' value depends on business context: a state
transition in an internal tool might not warrant an assertion, but one
involving money absolutely must. AI can scan all code paths to find
candidate locations (its advantage — humans can't check every state
transition line by line), but "how severe are the consequences if this
path fails" is a business judgment.
Deployment impact analysis also belongs to this
layer. Code changes have two types of impact: compile-time impact caught
by the type system (discussed earlier), but deployment-time
impact has no compiler to check. A new environment variable in
the code means the Kubernetes ConfigMap needs a new line, Secrets need
configuration, maybe IAM permission bindings too. Code compiles, tests
are green, push to production, service crashes on startup because of a
missing environment variable. And the even more hopeless scenario: a fee
calculation ratio environment variable defaults to 0 —
doesn't crash without configuration, but silently runs with the wrong
default for a week until the boss asks: > "Why hasn't the fee account
balance changed in the last week?"
AI has an advantage humans lack here: it sees the complete
diff. Humans modifying code focus on business logic —
deployment impact is "I'll deal with it later" and then forgotten. We
require AI in the rule file to automatically output a deployment impact
checklist at task end:
1 2 3 4 5 6
## Deploy Impact
- [ ] Add `NEW_API_KEY` to `linewise-deploy/overlays/dev/secrets.yaml` - [ ] Add `NEW_API_KEY` to `linewise-deploy/overlays/testing/secrets.yaml` - [ ] Add env ref in `linewise-deploy/overlays/dev/deployment-patch.yaml` - [ ] Verify IAM binding for new service account scope
The four layers, top to bottom, with increasing human
involvement:
Layer
Human role
Frequency
Compiler-enforced
Choose language & type system
One-time
Actionable rules
Make implicit knowledge explicit
Ongoing maintenance
Process constraints
Design AI's workflow
Occasional tuning
Advisory rules
Decide on AI's suggestions
Every review
This is the outcome I'm after: human brainpower is finite and
precious. The purpose of layering is to focus human attention
on Layer 4 — where genuine business judgment is needed — while Layers
1-3 are handled automatically by the compiler and rules.
The Bigger Picture
The Ironic Ending
FP has been criticized for decades as "unreadable without a PhD." But
in the AI collaboration model:
Humans carefully read signatures — which happens to be FP's
most readable part.Humans skim implementations — which
happens to be FP's most off-putting part.
FP's cost (cognitive burden of implementation) falls on AI: AI
doesn't care. FP's benefit (explicit, verifiable type contracts) goes to
humans: humans just need to confirm "yep, looks good, LGTM."
And AI doesn't just "not care" about FP's complexity — it actually
makes fewer mistakes in the FP model. Like a calculator
computing 1+1 and 69420+80085 in the same
time, AI's per-line cost for type gymnastics vs plain assignment is
roughly identical. But a project isn't one line — it's tens of thousands
of lines accumulated over years. Mutable state + temporal reasoning
means every additional line exponentially grows the state space AI needs
to track; immutable + composition grows it linearly. Over tens of
thousands of lines, the error rate gap is orders of magnitude. More
critically, the type system provides deterministic instant
feedback — compilation failure is failure, massively
eliminating "looks right but explodes at runtime." Not completely:
external systems, hardware calls, network timeouts are beyond the type
system's reach. But within its domain (nulls, error paths, parameter
type confusion), feedback is instant and certain. Dynamic language
feedback loops are far longer: write → run tests → discover failure →
guess which step's state went wrong → backtrack.
AI makes certain capabilities cheap: type gymnastics, symbolic
reasoning, complex monad transformer stacks. What can't be made
cheap is what's truly precious: judging what a system should do,
defining correct abstraction boundaries, deciding which constraints are
worth encoding into types. Calculators can't replace
mathematicians; AI can't replace architects.
The FP community has waited decades for its "this time it'll catch
on" moment. It seems the most powerful catalyst isn't a shift in human
aesthetic taste, but AI's natural affinity for explicit type
information. And all humans need to do is free their brainpower from
"understanding semiflatMap" and spend it where it matters:
defining what the system should do, not worrying about how the
system does it.
AI-native = ADHD-native
This section is personal, but I think it explains things that are
hard to grasp from a purely technical angle.
I have ADHD. In past work, I constantly made small mistakes —
swapping variable order, forgetting to update loop state, losing track
in deep if-nesting, guessing i+1 or i-1 for
array bounds by pure luck. My short-term working memory is terrible —
like an agent with a limited context window: processing function A's
logic, jumping to function B, and when I come back, half of A's context
is gone. Jump to another task and back? Details have almost entirely
evaporated.
So my gravitating entirely toward FP was practically inevitable.
Immutable data means I don't need to remember "what state is
this variable in right now"; type signatures mean I don't need to
remember "how can this function fail"; compiler instant feedback means
when I forget something, it tells me immediately. I use the
type system to compensate for my short-term memory deficits, just like I
have agents use signature contracts to compensate for context window
limits.
But ADHD isn't just weaknesses. My long-term memory and episodic
memory are strong — decisions made in a meeting months ago, the context
behind the decision, why we chose this path instead of that one, I
remember more accurately than the meeting notes. During technical
discussions, I frequently get flashes of insight — weird alternative
approaches — which get shot down by the meeting moderator for being
off-topic. But in agent collaboration, this becomes an advantage: it's
like a trigger for reactive knowledge retrieval in an awakened
agent.
Putting my cognitive profile alongside AI's:
Me (ADHD human)
AI Agent
Short-term memory
Poor, easily loses context
Limited by context window
Long-term memory
Strong, rich episodic memory
None (every session starts from zero)
Symbolic reasoning
Weak, prone to trivial errors
Strong, but also makes mistakes
State space reasoning
Very weak, mutable state tracking is a nightmare
Relatively weak, error rate rises with state explosion
Compiler feedback
Lifesaver, compensates for my symbolic reasoning deficits
Same lifesaver, corrects its reasoning errors
Architectural intuition
Strong, what to split, what to merge
Weak, tends toward local optima
Cross-domain association
Strong, but often suppressed in human teams
None, unless human prompts
Our weaknesses overlap heavily; our strengths complement
perfectly. What I'm bad at — concrete implementation, symbolic
reasoning, state tracking: AI is better. What AI is bad at —
architectural decisions, long-term memory, cross-domain association: I'm
better. And our shared weakness — complex state space reasoning — if we
can't beat it, we go around it.
This is why every design choice in this article points in the same
direction: let the compiler compensate for weaknesses it can
(type system, exhaustiveness checking), let AI do what it's good at
(implementation, symbolic reasoning), let me do what I'm good at
(architecture, rules, cross-domain association). My
architectural designs must shift direction to accommodate our shared
weaknesses — more decoupled, more isolated, semantics above all,
top-level design oriented toward FP.
AI-native coding style is really the ADHD-native coding style I've
been using all along. Not because ADHD is a good thing, but because
the compensatory mechanisms I built for cognitive deficits
happen to also suit AI's strengths. The topic of what role
humans play in this division of labor, how they work, and which
cognitive habits need changing — that's too big for this article and
deserves its own piece.
"Can't Read AI-Written Code?"
This is the most common objection. AI-written FP chain code —
EitherT, semiflatMap, bimap —
humans can't read it. What happens when there's a production
incident?
Oh right, as if you can read assembly.
In today's software stack, from the Java/Scala you write to the
machine code actually executing on the CPU, how many layers do you pass
through that you can't read? JIT-compiled native code, OS system calls,
hardware interrupt handlers — you've never felt unable to debug just
because you "can't read those intermediate layers." Because you don't
need to read them. You debug at your own abstraction layer.
In fact, in 2026, when senior engineers genuinely need to debug at
the assembly level, they throw the assembly at AI for an
explanation. AI translates assembly into plain language; the
engineer reasons on top of the plain language.
FP abstract code works the same way: can't read the
EitherT chain? Throw it at AI and have it explain in
natural language — "this code first fetches the user, validates, then
fetches the score; any step failing returns the corresponding HTTP error
code." AI can both write this alien scripture and translate it into
plain language.
Moreover, FP code's debug difficulty and depth are far
lower than stateful imperative code:
No mutable state: no need to track "this variable
was modified at line 47, then again at line 123, which version does line
200 read?" Pure functions' output depends only on input — same input
always yields same output.
Explicit error paths:
Either[AppError, User] tells you errors are only those few
AppError cases. No need to guess "might some deep call
throw a NullPointerException?"
Composability: every function is an independently
testable unit; bug localization scope is naturally small.
Token Economics
In the "military trust" section I dropped a hot take:
trusting signatures means trusting comrades. And this
trust behavior saves token costs.
Every act of distrust is a token expense, growing
Fibonacci-style. When an agent doesn't trust the signature, it
needs to open fetchUser's implementation to verify "does it
really return Left(NotFound) when user is not found?" —
reading one file. Then discovers fetchUser calls
queryDB — needs to confirm queryDB's error
handling too, reading another file. Ten functions each verified once is
ten extra file reads. Worse, consider the token billing model: file
contents read back from each tool call become input tokens for the next
round, and the output reasoning process gets billed as input after the
next tool call. In other words, every token ever generated adds
to the price of every future call — the more files read, the
more context bloats, the more every subsequent step's token bill
snowballs. Trusting signatures means the agent only needs to read the
current file to do its work; distrusting signatures means every
additional file read causes the remaining steps' token bills to inflate
in lockstep.
Trust chains + scope isolation also open up bigger architectural
possibilities:
Coding agents can be smaller, cheaper, faster. When
scope is tight enough and modules are isolated thoroughly enough, a
coding agent doesn't need a global view — it only needs to see the
signatures of functions it's responsible for, the signatures of
dependency interfaces, and relevant type definitions. Solving
within a given contract is all there is. It doesn't even need
the strongest model — when the task is constrained tightly enough, a
mid-tier model with clear signatures and type constraints can do the job
correctly. The more precise the contract, the lower the model capability
requirement.
Difficulties can be escalated rather than toughed
out. When a coding agent hits a problem it can't solve within
its current scope — a poorly designed signature, a flawed type
constraint, or ambiguous requirements — it doesn't need to "best effort"
guess and force an implementation. The correct action is to
report the issue back to the orchestrator, who adjusts
the design or clarifies requirements, then assigns it to (possibly
another) agent for execution.
Global consistency is ensured by a dedicated review
agent. After multiple coding agents each finish work in their
small scopes, a review agent with a larger context window checks the
global changes for consistency — do interfaces align, do error types
match, is naming uniform. This review agent doesn't need to understand
every function's implementation details — it only needs to audit that
the signature-level contracts are self-consistent.
This is my envisioned agent orchestration model:
1 2 3 4 5 6 7 8
Orchestrator (architect) → Decompose tasks, define signature contracts → Assign to multiple Coding Agents (soldiers) → Each agent solves within its small scope → Problems outside scope → escalate to Orchestrator → Review Agent (inspector) → Check global signature consistency → Doesn't read implementations, only contracts
Outlook
Is Code a Liability or an
Asset?
There's a widely quoted saying in software: Code is a
liability, not an asset. Every line of code is future
maintenance, comprehension, and modification cost. When you first wrote
the code, only you and God knew what it did; after six months in
production, only God can still read it.
This is entirely true in traditional development. Technical debt
grows exponentially — each layer of hack makes the next hack harder to
understand, each "temporary solution" digs a pit for the next
maintainer. Taking over a codebase with technical debt, whether adding
features or fixing bugs, is an uphill battle. Custom software projects
almost have to be maintained by the original team or a domain-specific
outsourcing team. Bring in a new group, and just understanding "what
does this thing even do" takes months.
But what if we could keep technical debt growing
linearly instead of exponentially?
All the engineering discipline discussed in previous sections — type
signatures as contracts, sealed trait exhaustive errors, opaque type
anti-confusion, fix-it-when-you-touch-it gradual debt repayment — share
a common goal: keeping the code comprehensible to new
maintainers (human or AI) at any point in time.
If this goal is achieved, the nature of a codebase fundamentally
flips:
A codebase with strict discipline from day one makes adding
features and fixing bugs no longer incredibly difficult. Not
just for me — even developers who aren't the original authors can, to a
reasonable degree, add custom features on top of this code, because new
agents easily understand what past agents left behind. Signatures are
honest, types are precise, error paths are exhaustive — no implicit
knowledge that requires "veterans passing it down by word of mouth."
Of course, architecture-level adjustments still require the
original author or a maintainer of equivalent capability and
vision. But for feature-level development —
adding an API within the existing architecture, fixing a business bug,
migrating a data format — the required person-months drop dramatically.
Because these tasks are fundamentally "solving within given contracts,"
and honest signatures plus strict type systems express those "given
contracts" crystal-clearly.
The premise for a codebase transforming from liability to
asset isn't "written well" but "maintained well." So can my Art of
Whipping AI Grunts bring the cost of "continuous maintenance" to
historically low levels?
The Next-Generation
AI-native Language
Since I've already gone this far with the hot takes, a few more won't
hurt: the next-generation AI-native programming language might
genuinely not need to consider human writing or reading
experience. Just like nobody hand-writes assembly today.
Could future programming languages bifurcate into two layers?
Contract layer: pure signatures, contracts, intent
expression — possibly more like a declarative specification
language
Execution layer: implementation language optimized
for compilers and AI — since humans focus their energy on reviewing the
contract layer, implementation readability drops dramatically in
importance; human writing experience is no longer a design goal;
information density and type precision are what matter
This is my science fiction. Today's Scala 3, Rust, and Haskell
already have powerful type system expressiveness with implementations
that increasingly look like alien hieroglyphics. The next-generation
language just needs to: acknowledge that humans don't need to read
implementations, then completely remove "human readability" from the
implementation layer's design goals.
Applicability Statement
This article has two premises: one about AI architecture, one about
project types.
AI architecture premise: Today's mainstream
transformer architecture — fixed context windows, no cross-session
state, stateless inference starting from zero each conversation.
Project type premise: All practices discussed in
this article apply to a specific class of software projects:
The distinguishing criterion is the nature of state.
This article assumes the typical scenario: state ultimately persists to
a database, in-memory state is ephemeral and reconstructable (soft
state). In this scenario, immutable + functional composition has low
cost and high benefit, as argued throughout.
But in hard-state-dominant domains — compiler AST transformations,
embedded register operations, hardware driver interrupt handling — state
itself is the core abstraction, immutable data structure overhead is
unacceptable, and tight inter-module coupling is a physical constraint,
not a design flaw. In these domains, many of this article's
recommendations aren't just inapplicable — they're harmful.
Language premise: This article's rule file examples
and engineering practices are based on Scala. Scala is multi-paradigm:
it lets you write pure FP, imperative, OOP, or any mixture. This means
much of the rule file's constraints exist to pin the agent's
behavior to a single Pure-FP paradigm, preventing drift between
multiple legitimate styles. If your project uses Haskell, a large
portion of these constraints are unnecessary — the language itself
already enforces them.
If this article were translated to Rust, it'd be significantly
shorter. Rust's ownership system and borrow checker already eliminate
most mutable state issues at compile time — no need for rule files to
prohibit them. But even in Rust, I'd still write: agents are
forbidden from independently declaring global mutables
(static mut, lazy_static + Mutex,
etc.); local mutables (let mut) are forbidden from spanning
more than 2 scope levels, and absolutely forbidden from escaping the
function. Similarly, I'd enforce agents using
Has<T> traits for compile-time dependency injection —
Rust's version of tagless final: service dependencies expressed through
generic constraints
where Ctx: Has<UserRepo> + Has<AuthService>,
not passing a bunch of concrete types in function parameters. The
signature-layer design principle doesn't change with the language — only
the syntax differs.
And Rust's let-else + ? has even lower
reasoning cost for agents than Scala's cats gymnastics:
Each line is self-contained: input, check, failure path — all closed
within the same line. The agent processing line 2 doesn't need to recall
line 1's branch structure — exactly the linear flow
(Style A) analyzed in the "Implementation-Level Error Handling" section,
just with Rust combining early return guard and pattern matching into
one with let-else. For agents, this has a shorter, more
local, less error-prone reasoning path than
EitherT(...).subflatMap(...).semiflatMap(...).
What the language handles, leave to the language; what the language
can't reach still needs rules to fill the gap — this principle is
cross-language.
But not every scenario should chase the lowest writing cost. Whether
Scala or Rust, I mandate AI use the Reactive Stream pattern. During the
writing phase, reasoning about Reactive Streams might cost several times
more tokens than an iterator + channel approach (in Rust, even tens or
hundreds of times more — ownership, &mut, lifetimes,
and other constraints might even force you to restructure data types
finalized months ago). But this upfront investment pays off: Reactive
Stream operators are themselves declarative behavior descriptions. When
debugging, agents don't need to chase scattered state mutations across
imperative code — they just look at the operator chain: messages being
dropped? .buffer(n, OverflowStrategy.dropHead) is right
there in black and white. Order scrambled?
.unorderedFlatMap(...) is staring at you. Each operator is
a self-explaining behavior declaration; the bug's cause is written in
the operator's name. The imperative equivalent?
LinkedBlockingQueue's capacity limit is buried in the
constructor, whether the queue blocks or drops when full depends on
whether the caller uses put() or offer(),
scattered in some corner of the producer code. Order issues are even
more hidden: ExecutorService.submit()'s multithreaded
scheduling makes consumption order a runtime-only observable behavior —
nowhere in the code does it say "ordering is not guaranteed." The agent
needs to trace queue initialization, producer logic, and thread pool
configuration across files to locate the same bug. Today's extra writing
tokens buy back massive reading and reasoning tokens for every future
agent.
What does the AI architecture premise affect? Not everything.
Architecture-independent conclusions — won't change with
model evolution:
Signatures/contracts should be honest and complete (§1-§4).
Regardless of reasoning architecture, explicit information beats
implicit conventions. This is an information-theory judgment, not an
assumption about specific model capabilities.
The human-reviews-contracts, AI-writes-implementation division of
labor (§3). This stems from the physical limits of human cognitive
bandwidth, independent of AI architecture.
Type systems and refinement types provide deterministic feedback.
Compilers don't become less important because AI gets stronger.
Architecture-dependent conclusions — will change as model
capabilities evolve:
Rules correcting training preferences (§5's Grep vs
LSP choice, error handling preferences, etc.). These rules fundamentally
compensate for current models' training biases. As models continue
evolving on existing architectures, these biases will shift — some bad
habits may be corrected, new biases may emerge. Rule files must
be continuously maintained and fine-tuned alongside model capabilities —
that itself is part of rule engineering.
Cross-session process constraints (§6's Code Smell
Tracking, memory files, etc.). These mechanisms exist entirely to
compensate for stateless inference's deficiencies.
We don't even need to wait for "perfect memory." Even one small step
— like RWKV-style architectures with persistent state — if inference
capability approaches current transformer levels, the game changes.
Imagine this workflow: you spend weeks collaborating with an agent,
and it gradually accumulates understanding of the project's coding
style, architectural decisions, and module boundaries in its persistent
state. When you need to parallelize multiple tasks, fork
multiple sessions from that state — each fork inherits the same
project knowledge, independently handling code review, refactoring, or
bug fixes, without each session starting from zero reading CLAUDE.md and
memory files.
This is fundamentally different from the current model. Right now,
every new session is a novice agent + text-based rule
files. You must textualize all implicit knowledge — "this
project uses tagless final," "NoOp implementations for data-related
services must return failure," "persisted data is trusted" — write it
all into rule files, then pray the agent correctly interprets them
within a limited context window. Rule files are essentially simulating
long-term memory with text — it works, but clumsily, with a token budget
ceiling.
A persistent state that has accumulated project understanding is like
an engineer who's been on the team for months: no need to re-read the
coding standard every morning, no need to write "why we chose this
architecture" as a document to remember it. You no longer need
to textualize every rule, because the rules are already internalized in
the state.
When that day comes, most of this article's second category of
conclusions — the precise wording of rule files, cross-session memory
mechanisms, Code Smell Tracking's filesystem workaround — can be
drastically simplified or dismantled entirely. Rule engineering won't
disappear, but it devolves from "meticulously textualizing everything"
to "occasional course corrections" — a completely different magnitude of
effort.
But until that day arrives, the scaffolding is still essential.
Appendices
Appendix
1: AI's Toolchain — Grep, LSP, and Disambiguation
Even with Metals MCP (Language Server Protocol tooling) connected, AI
still prefers to use regex search and replace throughout refactoring —
Grep + regex is the most well-worn path in its training data.
But Grep has clear capability boundaries. Through repeated
experimentation, we've mapped out a clear division of labor:
Use Metals (compiler resolution) when the question is "what
did the compiler resolve this to?"
Scenario
Why Grep fails
Given/implicit resolution: "which given Transactor[IO]
is in scope here?"
Grep searching given Transactor returns 10+ candidates;
can't determine which the compiler selected
Extension method: "who defines .pure[F]?"
def pure is in the cats source, but Grep can't tell you
which extension applies to your specific type
Opaque type unwrapping: "what's ProjectId's underlying
type?"
Grep finds opaque type ProjectId = UUID, but chained
calls require cross-file tracing
Overload resolution: "which apply is being called
here?"
Grep finds all overloads; requires manual parameter-type
matching
Type alias + inheritance: "does ConnectionIO extend
Sync?"
One sentence: "How did the compiler parse it?" → Metals.
"Where is this text?" → Grep.
FQN Limitations and Proper
LSP Usage
I used to constantly correct AI for writing fully qualified names
(org.springframework.http.HttpHeaders) — felt too verbose.
Later I realized FQN genuinely eliminates ambiguity. AI sees
HttpHeaders and doesn't know if it's
org.springframework.http.HttpHeaders,
io.netty.handler.codec.http.HttpHeaders, or
java.net.http.HttpHeaders.
Can we go further and use SCIP (SemanticDB-based code indexing) to
automatically annotate source files with FQNs? I had Claude evaluate
this approach:
FQN is indeed useful for me. When I see
val vec = Pgvector(chunk.embedding), I don't know whether
Pgvector comes from doobie.postgres,
o.linewise.core.database.DoobieInstances, or somewhere
else. FQN instantly eliminates this ambiguity. But I already have a
better tool.
Need
SCIP snapshot
Metals LSP
"What is PgVector?"
Read 3x-bloated annotated file
One inspect call, precise type
"Who calls resolveAuth?"
Grep the snapshot (equivalent to Grep source)
get-usages, semantic-level, not text-level
"What type does this expression return?"
Not in snapshot (SemanticDB doesn't contain sub-expression inferred
types)
inspect returns it directly
"All implementations of PermissionService?"
Grep FQN pattern
typed-glob-search
SCIP snapshot costs: 3x token bloat (150-line file
becomes 450 lines), instantly stale (any edit
invalidates it), doesn't cover the real pain points
(debug/refactoring bottlenecks are implicit/given resolution chains —
SemanticDB doesn't capture these; TASTy does).
Conclusion: give the agent LSP tools and let it query
on-demand when it hits ambiguity, rather than burdening every
line of code with redundant fully qualified paths.
Appendix
2: Inter-Model Collaboration and Knowledge Transfer
Code written by advanced models can "teach" ordinary
models. High-quality code and skills written by top-tier models
(like Opus) can effectively guide weaker models through development
work.
All major models' training data contains large amounts of
high-quality open-source code — the knowledge itself exists. The real
difference comes down to two things:
Weight allocation — different models give different
weights to the same knowledge, causing some to naturally produce
high-abstraction code while others default to more "mediocre"
solutions
Side effects of human alignment — this directly
depends on the AI trainers' cognitive level. During training, models
generate "wild ideas" — unconventional but potentially extremely
effective strategies. If trainers lack the cognitive ability to
recognize these wild ideas' value, see them diverge from the mainstream,
and immediately penalize them, these high-value strategies get
suppressed in the model. People with poor cognitive ability
can't train good AI.
Practical tip: use an advanced model to "activate" this
knowledge in-context ahead of time — write it as skills,
example code, or rules in CLAUDE.md — then when ordinary models work in
that context, they follow the rails already laid down instead of
retreating to their default "safe" style.
Multi-model collaboration? Same-tier peer review works
better. Some try having multiple model vendors review design
documents — Opus, Gemini, GPT as three "experts" discussing and voting.
In practice, models with too large a cognitive gap sitting at
the same table don't produce effective discussion. Two college
professors discussing a research proposal with a grade schooler in the
middle — the child won't provide a "different perspective," just drag
down the floor of the discussion.
A more effective approach: same-tier models reviewing each
other, but with different assigned stances. For example, two
Opus instances — one playing "aggressive refactor advocate," the other
"stability-first conservative" — they have the capacity to understand
each other's arguments and mount substantive rebuttals. Discussions
between cognitively mismatched models only degenerate to "the weakest
model's comprehension level."
This is fundamentally the same theme as this entire article:
if the tools you're using can handle higher abstraction levels,
don't downgrade to accommodate the weakest link. This applies
to code style, and it applies to model collaboration.
事实上越来越多的项目中,代码的主要作者已经是 AI
了,你身边的同事已经悄悄买了 glm coding plan 甚至中转站的 Codex
套餐,每天上班需求扔给 AI
后,自己则聚焦于:把尿喝白,把股炒红,把电充绿,把事办黄。人类的角色正在从"写代码"转向"把产品经理的
PRD 扔给 AI,装模作样 Review AI 代码,适当的调用一下 pua
skills(你不干有的是 AI 干。),以及让 AI 代写工作总结和回怼邮件"。
既然都已经那样了,那能不能干脆这样:代码都是 AI
编写、维护、debug、阅读,那还需要人类可读性干嘛?
马圣都说了:直接让 AI 生成机器码,一步到位。
当然,我没马圣那么极端,我的观点是:逻辑实现可以不用那么照顾人类感受了,但接口定义需要。
人类的脑力是有限且宝贵的,长时间进行复杂的符号推理对眼睛和头发都是消耗,但
AI
不会累。那编码阶段是不是可以这样分工:牛马(AI)负责实现,老板(人类)喝喝咖啡,逛逛论坛,然后稍微检查一下契约(函数签名)
// AI-native:签名强制非空,调用方在 call site 处理空 case defbatchEmbed(texts: NonEmptyList[String]): IO[NonEmptyList[Embedding]]
传统写法里"不能传空数组"是一个美好的愿望,或者注释里的一行
// texts must not be empty。别说 AI
了,人有几次写代码看注释的?还不是炸了再说。这个数组下游传进来就是空的,
NoSuchElementException
了找下游去。NonEmptyList 把这个约束提升到了类型层面,下一个
AI 牛马必须用 NonEmptyList.fromList 处理空
case,否则鞭译不过。
并且,这种染色类型在 AI-native
代码里强制要求贯穿全程,从接受外部输入(Request/Input)开始就要进行严格验证,并转换为着色(refined)类型,而只有到系统出口(Response/Output)时才可以转换为非着色类型(Int/Long/String)。这样一来,不论是新或者老
AI 牛马,亦或者是 /compact 后的阿兹海默 AI
牛马,不管在任何一层忘记约定胡来,都会被鞭译器鞭挞。
类型系统能解决签名契约模糊的问题,但签名之下还有大量鞭译器鞭长莫及的微操决策。这些决策分两类:一类是纠正
AI 训练带来的坏习惯,一类是人类必须亲自划定的语义边界。
AI 的默认坏习惯
Fail-fast,禁止吞错误。 AI
牛马的训练偏差让它极度滥用
.getOrElse、try-catch
兜底、IO.handleErrorWith
把错误掩盖并返回默认值,假装岁月静好。AI
牛马的这个坏习惯根深蒂固到需要单独展开讨论,后面"规则工程"一节的"绝对化表述"会详细分析这个偏差的三种形式、为什么要用绝对化规则对抗它、以及禁止吞错误是如何方便线上故障排查的。
命名规范 + 定期审计。 人类能记住"processMatrix
其实干的是流量分发",大脑会自动建立名实不符的映射。但 AI
不会,每开一个新
session,它都会老老实实按字面意思理解,然后在同一个坑上反复栽倒。命名污染对
AI 的伤害远大于对人类。定期让 AI
自己审计命名一致性,比人类自己检查效率高得多。
模块化:做加法不做乘法。
功能叠加是线性增长,功能交叉是组合爆炸。三个模块你中有我我中有你的紧密交织在一起,AI
理解错或漏掉任何一个模块都会写出错误实现,然后反复调试挣扎。对 AI
牛马来说,模块边界就是理解边界,需要知道的越少越好,AI
牛马犯错的概率越低。
为什么交给 AI 自己判断?因为"这个数据源是否可信"我给了 AI
清晰的判断标准。同一个 JSON 解析操作,解析配置文件应该
throw(配置错了就别启动),从不看接口文档的客户端开发,以及解析用户上传的文件应该返回
Left(用户瞎瘠薄传上来一篇网文小说很常见)。人类在规则文件中画出这条分界线线,牛马才能执行。
同一个 pattern 在不同语义域下正确性不同。 这一点在
NoOp 实现中体现得更明显。tagless final 架构中,每个 service 都有一个
NoOp 实现(用于测试或 feature flag 关闭时),问题是:NoOp
应该返回成功还是失败?
1 2 3 4 5 6 7 8 9 10 11
// 数据相关的 NoOp , 必须返回失败 // 因为"操作没有执行"对数据一致性是致命的 classSOPServiceNoop[F[_]: Applicative] extendsSOPService[F]: defcreateSOP(...) = Left("Service not available").pure[F] defdeleteSOP(...) = Left("Service not available").pure[F]
在 AI-native 的开发模式下,项目前期最重要的投入不是纠结 MySQL 还是
PostgreSQL、用 Spring WebFlux 还是
Vert.x,而是建立一套清晰的规则文件。
好的技术选型当然有价值,但技术选型错了可以迁移,并且迁移成本在 AI
时代也显著降低了;规则缺失或模糊导致的代码风格漂移,几个月后就是一座每个
session 都在往不同方向拉屎的屎山,这个比选错数据库难修多了。
但规则同时写明:"suggest, not mandatory",最终决定权在人类
code review。
为什么不强制?因为断言的价值取决于业务上下文:一个内部工具的状态转换可能不值得加断言,但一个涉及资金的状态转换必须加。AI
能扫描所有代码路径找出候选位置(这是它的优势,人类不可能逐行检查每个状态转换),但"这个路径出错的后果有多严重"是业务判断。
部署影响分析也属于这一层。代码变更有两种影响:编译期影响由类型系统捕获(前面讨论过了),但部署期影响没有编译器能检查。代码里新增了一个环境变量,Kubernetes
的 ConfigMap 需要加一行,Secret 需要配置,可能还需要 IAM
权限绑定。代码编译通过,测试全绿,推到生产环境,启动时因为缺一个环境变量而服务宕机。还有更绝望的:计算手续费比例环境变量有默认值
0,没配置的时候不崩溃,但用了错误的默认值默默跑了一周,老板问责:
> 怎么最近一个星期手续费账户余额没变过?
AI 在这件事上有一个人类不具备的优势:它看到了完整的
diff。
人类在改代码的时候,注意力在业务逻辑上,部署影响是"回头再说"的事,然后就忘了。我们在规则文件中要求
AI 在任务结束时自动输出部署影响清单:
1 2 3 4 5 6
## Deploy Impact
- [ ] Add `NEW_API_KEY` to `linewise-deploy/overlays/dev/secrets.yaml` - [ ] Add `NEW_API_KEY` to `linewise-deploy/overlays/testing/secrets.yaml` - [ ] Add env ref in `linewise-deploy/overlays/dev/deployment-patch.yaml` - [ ] Verify IAM binding for new service account scope
该文件为我个人自用的CLAUDE.md规则文件,维护生产项目已有一年时间,从
Cursor + opus 3.7 时代至现在Claude-Code + opus 4.6时代。
请注意:该文件也仅可用于 Claude code opus
4.6,我不是对 codex 和 gemini 有偏见,OpenAI 的 25k USD credits
今年6月份就要过期了,它(gpt-5.4-xhigh/codex-5.3-xhigh)要是真有自媒体和AI教父们宣传的那么牛逼plus,我能把这些credits放过保质期?
实测效果就是 codex 对函数式编程风格遵循不理想,对 opus 4.6
有效的简短提示词,你不掰开揉碎了讲给 AGENTS.md 它必定会跑偏。
因为编码风格,个人品味原因,请勿整段复制甚至替换掉你的规则文件。你可以让
Claude
阅读我的规则文件,分析后你再决定有哪些可以采纳,有哪些不适合你当前项目。我个人的编码和架构风格非常激进,因为许多代码/系统烂是烂在骨子里的,在这些屎山系统上打“优雅”的补丁实际上还是在推高屎山的海拔,而并没有真的降低技术债务。所以我的架构设计风格从来是大胆激进,没什么不能改也没什么不敢改的,活着的系统一定要经常重新审视,只要能降低技术债务,要敢于进行局部甚至底朝天的重写;只有死了的系统才是永恒不变的。
This file provides guidance to Claude Code (claude.ai/code) when
working with code in this repository.
Overview
Linewise API is a multi-tenant backend service built with
http4s (Scala 3 / cats-effect). It provides document
management, AI-powered features (embeddings, RAG), video SOP generation,
and real-time communication capabilities.
Refactoring Philosophy
Prefer radical type-level refactors over conservative
patches. This is a statically-typed Scala 3 codebase with
tagless final — the compiler catches all downstream breakage. When
fixing an issue, always choose the solution that encodes the constraint
in the type system, even if it touches many files. A 15-file signature
change that the compiler verifies is safer than a
1-file patch with a runtime check.
Don't minimize blast radius — maximize type safety.
Changing a method from List[T] to
NonEmptyList[T] across 6 files is not "risky" — the
compiler finds every call site. A runtime .toNel.get hidden
in one file is the real risk.
The compiler is the last line of defense. If a
refactor compiles, it's correct. Treat compilation as the acceptance
test for type-level changes.
Write-cost is near zero. AI writes 90%+ of code, so
the cost of touching more files is negligible. Optimize for correctness
and compile-time safety, not for minimal diff.
Type precision is not over-engineering.
Over-engineering means unnecessary abstractions, config flags, strategy
patterns for one implementation. Using NonEmptyList over
List, ProjectId over UUID, or
propagating constraints through signatures is the opposite — it removes
complexity (runtime checks) by shifting it to the compiler. "Avoid
over-engineering" applies to architecture, not to type-level
precision.
// Access via summoner SOPService[F].getSOP(tenant, id)
NoOp Result Patterns:
NoOp implementations are used for: (a) test runners / local
partial testing, and (b) feature-flag-disabled
services in LinewiseApp.scala. NoOp returns
results (not throw exceptions). The caller decides if it's an error.
Data-related vs data-unrelated services: -
Data-related (RAG, video processing, document ops,
SOP): NoOp must return error
(Left("Service not available")). Option
methods return None — but note this means "not found",
which is semantically different from "service disabled". For
Either-returning methods (create, update, delete), always
return Left so the caller knows the operation was not
performed. Data-related services should use F[Either[E, T]]
by default (not F[T] or F[Option[T]] for
mutation), because they involve the persistence layer which can fail. -
Data-unrelated (logging, metrics, telemetry): NoOp can
return success (Right(())). Skipping
side-effect-only operations is harmless.
// BAD — nested match in MID-CHAIN breaks the for-comprehension flow for result <- service.doSomething(...) value <- result match// BAD: match in middle, more steps follow caseRight(v) => v.pure[F] caseLeft(err) => Sync[F].raiseError(err) next <- process(value) response <- Ok(next.asJson) yield response
// ALSO BAD — .flatMap with case inside for-comprehension for body <- req.req.as[Body] result <- service.getItem(id).flatMap { caseSome(item) => Ok(item.asJson) caseNone => NotFound(...) } yield result
// GOOD — plain match at TERMINAL position (pure response mapping, no side effects) for body <- req.req.as[Body] result <- service.doSomething(body) response <- result match caseRight(value) => Ok(value.asJson) caseLeft(err) => BadRequest(err.asJson) yield response
// GOOD — lift Either/Option into F (throw on error — trusted paths only) for value <- Sync[F].fromEither(parseJson(raw).leftMap(e => RuntimeException(e.message))) response <- Ok(value) yield response
// GOOD — EitherT.foldF when branches have SIDE EFFECTS (logging, audit, cleanup) for body <- req.req.as[Body] response <- EitherT(service.doSomething(body)).foldF( err => Logger[F].warn(s"Failed: $err") *> BadRequest(err.asJson), value => audit.record(value.id) *> Created(value.asJson) ) yield response
// MID-CHAIN Either coloring — depends on data-related vs data-unrelated: // Data-unrelated mid-chain op (metrics): discard Left, log, continue IO chain for body <- req.req.as[Body] saved <- store.save(body) _ <- metrics.record(saved.id).flatMap { caseRight(_) => Applicative[F].unit caseLeft(err) => Logger[F].warn(s"Metrics failed: $err") // discard, non-critical } response <- Ok(saved.asJson) yield response
// Data-related mid-chain op (store.save): propagate Either — refactor chain to EitherT for body <- req.req.as[Body] response <- EitherT(validate(body)) .semiflatMap(valid => store.save(valid)) // F[Either[E, A]] — error must propagate .subflatMap(identity) // flatten nested Either .foldF( err => BadRequest(err.asJson), saved => Ok(saved.asJson) ) yield response
// GOOD — F[Option[A]]: use OptionT for single Option check for body <- req.req.as[Body] result <- OptionT(service.getItem(id)) .semiflatMap(item => Ok(item.asJson)) .getOrElseF(NotFound(ErrorResponse.notFound("Not found").asJson)) yield result
// GOOD — chained Options with different error statuses: EitherT + local enum privateenumLookupError: caseNotFound caseNoUri
for body <- req.req.as[Body] result <- EitherT .fromOptionF(service.getItem(id), LookupError.NotFound) .subflatMap(item => item.uri.toRight(LookupError.NoUri)) .semiflatMap(uri => doWork(uri)) .foldF( { caseLookupError.NotFound => NotFound(...) caseLookupError.NoUri => BadRequest(...) }, _ => Accepted(...) ) yield result
Key lifters: - EitherT(...).foldF —
F[Either[E, A]] → handle both branches -
EitherT.fromOptionF — F[Option[A]] →
EitherT[F, E, A] - .subflatMap — pure
A => Either[E, B] inside EitherT chain -
.semiflatMap — effectful A => F[B] on happy
path - OptionT(...).semiflatMap(...).getOrElseF(...) —
F[Option[A]] → handle None -
Sync[F].fromEither, Sync[F].fromOption — lift
pure values (throw on error)
No premature helpers: Don't extract single-use
private methods that just wrap a match. Inline the logic at
the call site.
Case classes over manual cursor decoding: For
external API payloads, define case classes with
derives Decoder and decode once with .as[T],
then pattern-match on decoded fields. Avoid manual
hcursor.downField(...).get[T](...) chains.
SDK/Library Priority Order
When integrating external services (e.g., Google Cloud, AWS,
Firebase), prefer libraries in this order:
Typelevel-wrapped Scala SDK (e.g., from
typelevel.org ecosystem)
Official Java/Kotlin SDK (wrap with
Async.blocking)
Use when no Scala alternative exists
Implement yourself (HTTP client)
Last resort, only when SDK unavailable or unsuitable
Example: For Google Gemini integration, use the
official Java SDK wrapped with Async[F].blocking rather
than implementing raw HTTP calls.
Multi-Tenancy with Schema
Isolation
The database uses PostgreSQL schema isolation for multi-tenancy:
System schema (public): Stores shared
data (tenants, users, system settings, quotas)
Tenant schemas (tenant_<id>):
Each tenant gets an isolated schema for their data (projects, documents,
SOPs, etc.)
Migration System: - System migrations:
db/migration/system/ - run once at startup - Tenant
migrations: db/migration/tenant/ - run for each tenant
schema - Migrations run automatically at startup for all existing
tenants - New tenant schemas are migrated on creation - Never modify
existing migration files; always create new versioned files
Tenant Schema Access: All tenant routes follow the
pattern: /api/org/{tenant}/...
Fail Fast - No Silent
Error Swallowing
CRITICAL RULE: Never silently swallow errors.
Arbitrary tolerance pollutes the database and hides bugs.
Forbidden patterns:
1 2 3 4 5 6 7 8 9 10
// BAD - silently converts errors to None/null json.as[T].toOption json.as[T].getOrElse(defaultValue) either.toOption Try(x).toOption result.getOrElse(null) parse(userInput).getOrElse(0.75) // BAD - hides parse failure
// OK - .getOrElse for optional config with a sensible default pageSize.getOrElse(10) // OK - Option[Int] with default, no error to swallow
Error Handling Strategy - Trusted vs Untrusted
Paths:
Path Type
Examples
Strategy
Trusted (internal)
Config files, system settings, DB schema data, internal
serialization, persisted DB data, internal service
calls, cache, GCS/K8s metadata
Throw exception - low probability of error, if it
fails it's a bug. For infra (GCS/K8s), human runs data migration after
code changes.
Untrusted (external)
User input, AI-generated content, external API responses
(before persistence)
Catch and report - high probability of error,
report back to user/AI to fix
Persisted data is trusted. Strict enc/dec at the
write boundary ensures bad-format data never reaches the DB. If
malformed data is read back from DB, it's a human/migration bug — throw,
don't defensively handle.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// TRUSTED PATH - throw on failure (system internal data) val config = configJson.as[AppConfig].getOrElse( thrownewRuntimeException(s"Config decode failed: ${configJson}") )
// UNTRUSTED PATH - catch and report to caller (user/AI content) // Use EitherT/match at terminal position — never use `return` for body <- req.req.as[UserContent] result <- service.process(body) response <- result match caseRight(v) => Ok(v.asJson) caseLeft(err) => BadRequest(s"Invalid content format: ${err.message}".asJson) yield response
Typed Error Model (ADT
Errors)
Use enum error types, not
Either[String, T]. Services define sealed error
enums for known failure modes. Routes pattern-match on the enum to
decide HTTP status — no string parsing.
Scope: one error enum per logical failure domain, not per
service. - If two methods share most failure modes → one shared
enum - If two methods have different failure modes → separate enums -
Shared subset across domains → compose via wrapping:
ParseError.Embedding(EmbeddingError)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Separate enums — methodA and methodB have different failure modes traitDocumentService[F[_]]: defimportUrl(url: String): F[Either[ImportError, Document]] defparseContent(docId: DocumentId): F[Either[ParseError, Content]]
// Shared enum — indexDocument and indexSop share the same failure modes traitRagIndexService[F[_]]: defindexDocument(docId: DocumentId): F[Either[IndexError, Unit]] defindexSop(sopId: SopId): F[Either[IndexError, Unit]]
Rules: - Named variants for known
failures. Each variant carries structured context (IDs, limits,
types), not string messages. - Sdk /
Other(message: String) variant for unexpected
errors that don't warrant their own case yet. - Compose, don't
flatten. When service A calls service B, wrap B's error:
case Embedding(cause: EmbeddingError), not
case EmbeddingFailed(message: String). - Route
mapping: Each error variant maps to exactly one HTTP status.
The match is exhaustive — compiler enforces handling every variant. -
Define in feature's models.scala. -
Migrate when file is touched — no hesitation. New
services use typed errors. Existing Either[String, T]
services migrate the whole service to ADT errors when
the file is modified for any reason — even a typo fix or comment edit.
The trigger is touching the file, not the size of the change. Touching
the file means QA/regression testing covers it, making it the perfect
time. Scope follows the compiler iteratively — if the route file you're
editing calls a service with Either[String, T], migrate
that service file too.
Feature Module Organization
Each feature module follows a consistent structure:
1 2 3 4 5
features/<feature>/ ├── <Feature>Service.scala # Business logic (tagless final trait + impl) ├── <Feature>Repository.scala # Data access layer (Doobie queries) ├── models.scala # Domain objects and DTOs └── README.md # Feature documentation
Tests use: - munit with cats-effect support for test
framework - TestContainers for PostgreSQL integration
tests (automatic database provisioning) - Doobie munit
for query checker tests
What NOT to test (waste of time): - Case classes -
no value without complex methods - JSON serialization - Circe is already
well-tested - Config class definitions - if config is wrong, app fails
to start anyway - Framework behavior (http4s, Doobie) - already
well-tested by the community
What TO test (valuable): - Security validation
(e.g., tenant name injection prevention) - Error handling / fallback
logic - Real database integration with TestContainers - Business logic
that has actual branching/computation - Assembly/wiring that connects
our components together
Override Grep with Metals MCP when the question is "what does
the compiler resolve this to?"
Grep is the default and works for most searches. But it fails
silently on these Scala-specific scenarios — use Metals instead:
Scenario
Tool
What type is this expression / what does it return?
mcp__metals__inspect
Which given/implicit is resolved at this call site?
mcp__metals__inspect
Which overloaded method is called here?
mcp__metals__inspect
What's the underlying type of an opaque type?
mcp__metals__inspect
What does a wildcard import bring into scope?
mcp__metals__inspect
Who calls this method / all implementations of a trait? (semantic,
not textual)
mcp__metals__get-usages
Other Metals tools: glob-search (find symbols by name),
get-docs (ScalaDoc), compile-file (single-file
compile check), list-modules,
list-scalafix-rules.
Signal to switch: When you grep and get 10+
candidates with no way to disambiguate — that means you need Metals, not
a better regex. Fall back to Grep/Glob for non-Scala files, string
literals, config values, SQL, or when Metals is unavailable.
Development Workflow
Adding New Routes
When adding or modifying routes:
Update the OpenAPI spec: After route/DTO changes,
update src/main/resources/openapi/documentation.yaml
Validate the spec: Run
swagger-cli validate to ensure correctness
Follow authentication patterns: All API routes
require Firebase JWT authentication (except system/health
endpoints)
Code Formatting
Use scalafmt (configured in .scalafmt.conf):
1 2
./mill reformat # Format all Scala sources ./mill checkFormat # Check formatting without modifying
Code style rules: - No fully-qualified names
in code. Always use imports. - Context bounds: use
{A, B, C} syntax (Scala 3.6 aggregate bounds), not
colon-separated. - Opaque types for domain values. AI
writes 90%+ of code, so write-cost is near zero while compile-time
safety is free. Use opaque types with smart constructors for all entity
IDs, constrained strings, and bounded numbers. Defined in
core/domain/Ids.scala and
core/domain/Types.scala. - Type-level constraints
flow E2E. Encode invariants in types (opaque types,
NonEmptyList, refined types) and propagate them through
all layer signatures: route → service → repository.
Never downgrade a constraint to a weaker type and re-validate internally
— that hides the requirement from callers and defeats compile-time
safety. Unwrap/weaken only at the true system boundary: SQL
interpolation, Java SDK calls, job parameter serialization. -
.toString over
.value.toString. Opaque types erase at runtime, so
s"...$opaqueId" and opaqueId.toString just
work — no need to unwrap first. - NonEmptyList over
List + .get/.head. When
a method logically requires non-empty input (batch embeddings,
IN clauses, etc.), use NonEmptyList[T] in the
signature — including repository methods — instead of
List[T] with a runtime .toNel.get or
.head. Callers use NonEmptyList.fromList to
handle the empty case at the call site. - No premature
helpers. If the logic can be composed from <5 Scala/cats
operators, always inline at call site — never extract a helper. If
>=5 operators, ask the user before extracting (in
plan mode or popup dialog). When consensus is reached on a new helper,
add/link it in this document so future sessions know to use it.
Always use helpers already listed here (e.g.,
AsyncOps) — don't expand them inline. Before writing any
new helper, search the codebase for existing ones that do the same
thing. - Generic over specific (stdlib/cats only).
Prefer composing well-tested Scala/cats operators generically (one
queryParam[T] using QueryParamDecoder[T]) over
type-specific parsers. "Generic" means leveraging stdlib type classes,
not extracting custom helper functions — those still follow the <5
operator rule. - Proactive naming review. When
modifying code, flag misleading, stale, or inconsistent names to the
user. Scope follows the compiler iteratively — same as
smell detection: start with changed files, then follow compilation
errors outward. For internal names (classes,
properties, methods) — recommend renaming directly. For external
names (request/response DTOs, DB-serialized JSONB fields) —
suggest the better name but note migration implications. Common smells:
Kotlin-era suffixes (Kt), field names that don't match
their type (name holding an ID), stale comments referencing
deleted code, generic names that obscure domain meaning. -
Proactive code smell detection. Scope follows the
compiler iteratively: (1) find smell in current file, (2) fix it, (3)
compile → if it fails because other files import the changed symbol, fix
those too, (4) repeat until compilation passes. If reading
unrelated code (not in the compilation chain) and spotting a
violation — add it to the smell list (see Code Smell
Tracking below), do not fix. This applies to all rules: type safety,
error handling, control flow, naming, logging, etc.
Code Smell Tracking
When spotting code smells in unrelated code (not in
the current compilation chain), add them to the persistent smell list
file at <project-root>/memory/code_smells.md instead
of just warning in the response.
Rules: - Max 10 entries. If adding
an 11th, delete the oldest entry (FIFO eviction). - Prioritize
by severity. Most critical smells first (silent error
swallowing > naming inconsistency). - At end of every
task, remind the user about pending smells and suggest fixing
them in a dedicated session. - Each entry includes:
file path, line number, rule violated, brief description. -
Remove entries when the smell is fixed (either by the
user or in a subsequent session).
Logging
Use val logger (not context-bound
injection). Create a local
val logger = Slf4jLogger.getLogger[F] or pass as
constructor param. Logger is too common to justify tagless-final
injection overhead.
Milestone logging for long operations. Every
long-running call (external API, DB migration, video processing,
embedding) should log at each major step so operators can see progress
and diagnose hangs.
Log level in loops: If each iteration is fast
(e.g., processing a list of items), use
debug/trace. If each iteration is slow (e.g.,
transcoding, embedding backfill), info is appropriate.
Log levels:error = unexpected
failures that need attention. warn = degraded but
recoverable. info = lifecycle events, milestones, external
calls. debug = per-item processing in loops, internal
state.
Runtime Assertion Checks
(RAC)
Suggest runtime assertions on critical paths (advisory, not
mandatory). RACs catch inconsistent state early, before it
propagates downstream and corrupts data. Always enabled in dev/testing;
switchable off in production via config flag. Final decision on whether
to add RAC is made during code review — do not treat missing RAC as a
code smell.
Implementation: Use the shared
RAC.assert(condition, message) helper
(io.linewise.core.RAC) that checks a config flag. When
disabled, assertions are no-ops. When enabled, they throw
immediately.
What should have RAC: - Money/balance
operations — assert balance >= 0 after debit, assert credit
+ debit = expected total - Inconsistent state
transitions — assert valid transitions in state machines (e.g.,
SOP stage: draft→processing→published, never published→draft; RAG index:
PENDING→INDEXING→INDEXED, never backward). Throw immediately on invalid
transition to prevent downstream pollution. - Tenant
isolation — assert search_path matches expected tenant schema
before writes. Wrong schema = cross-tenant data leak. -
Embedding dimensions — assert vector length matches
expected dimension (768 for text, 1408 for video) before pgvector
insert. Wrong dimension corrupts similarity search silently. -
Idempotency — assert no duplicate job submission for
same entity (K8s jobs, Quartz jobs). Duplicates waste resources. -
Invariant preservation — any operation where a
post-condition violation would silently corrupt data rather than fail
visibly.
What should NOT have RAC: - Input validation (use
typed errors instead — that's user-facing, not assertion) -
Performance-sensitive hot loops (use debug logging instead) - Conditions
already enforced by the type system (that's the compiler's job)
CI/CD Pipeline
IMPORTANT: Do NOT build and push Docker images from local
machine. Always commit and push to git to trigger CI for
building images. Only build locally if explicitly requested by the
user.
Branches and Docker Tags: - develop
branch → gcr.io/${PROJECT_ID}/linewise-api:develop -
testing branch →
gcr.io/${PROJECT_ID}/linewise-api:testing -
master branch →
gcr.io/${PROJECT_ID}/linewise-api:latest and
:master - Git tag vX.Y.Z →
gcr.io/${PROJECT_ID}/linewise-api:vX.Y.Z
Git Push: - If SSH push fails (e.g. VPN/proxy blocks
port 22), switch to HTTPS temporarily:
git remote set-url origin https://github.com/Vision-Nexus/linewise-api.git
Deployment: - GitHub Actions workflow:
.github/workflows/build-and-push-gcr.yml - Builds with
Mill, then Docker image, pushes to Google Container Registry - Requires
GCR_SERVICE_ACCOUNT secret (GCP service account JSON) -
Deployed via ArgoCD on Kubernetes (not docker-compose
or manual shell) - Deploy manifests live in a separate repo:
linewise-deploy/overlays/{dev,testing,prod}
Deploy impact reporting: When a code change involves
deploy-affecting changes, output a summary of what needs to be updated
in the deploy repo. Examples: - New environment
variable → add to ConfigMap or Secret in the overlay, reference
in Deployment env - New configuration field → add to
application.conf ConfigMap - New sidecar
container → add container spec to Deployment manifest -
New volume/secret mount → add Volume + VolumeMount to
Deployment - New external service dependency → may need
NetworkPolicy, ServiceAccount, or IAM binding
Format the output as a checklist the user can apply to the deploy
repo. Do NOT suggest docker-compose changes or manual
docker run / kubectl apply commands.
Key Dependencies & Services
External Services
Integration
Firebase Admin SDK: User authentication and JWT
verification
Vertex AI: Text embeddings, Gemini models, Document
AI for OCR
Google Cloud Storage (GCS): Document and video file
storage
LibreChat: Optional integration for chat
interface
Optional Features
Kubernetes Job Delegation: - Video processing
(FFmpeg, VideoSeal) can run as K8s jobs instead of in-process - Enable
via KUBERNETES_JOBS_ENABLED=true - Requires service account
with GCS access and K8s job permissions
Conflict of interest disclosure: This is not
investment advice. I'm not shilling any AI tool or API reseller.
Everything here comes from ~$20K worth of token-burning personal
experience. Different project types and different coding tastes may lead
to different conclusions.
In the last installment, we established: AI's knowledge reserves
dwarf any individual's, but that knowledge is hard to awaken; your
ability to discern quality sets the ceiling on output quality; the
trigger for better results is always your own growth, not AI's
spontaneous breakthrough.
The natural follow-up questions: How do you awaken its knowledge? How
do you verify its proposals? And when its proposals exceed your own
understanding, how do you learn enough to accept or reject them?
To answer these, we need to understand a prerequisite: AI is not a
stable tool. Its performance shifts as the conversation progresses. Over
the last two months, Opus 4.6 has given me a "singularity is near"
feeling — it can now accelerate my entire project development pipeline.
Not just one step being faster, but architecture design, coding,
debugging, deployment — the whole chain gets a boost.
First, a public self-own: I previously thought Opus 4.6 wasn't a
major leap over 4.5. I was wrong. Claude, I'm sorry. (bows) On small
tasks, the two really do perform similarly — first impression was
"meh.jpg". But the real gap is in long-context instruction following,
something you only notice after running a dozen large-scale refactoring
tasks. What small tasks can't reveal, big tasks make blindingly obvious.
In other words, Opus 4.6 delays the onset of "going stupid" in long
contexts by a significant margin.
This "going stupid" isn't simple capability degradation. Watch
carefully and you'll see it manifests in two fundamentally different
ways. Understanding the distinction between these two modes is the
foundation for answering the three questions above.
Two Flavors of Going Stupid
Flavor One: Forgetting
The longer the context, the more AI ignores previously established
consensus and conclusions. If you ask about them, it snaps back to
awareness. But if you don't proactively bring them up, it'll wander down
the wrong path for miles.
Supplementary research from Claude's research agent — this problem is
well-studied in academia: - "Lost in the Middle" (Liu
et al., 2023) — retrieval accuracy for information in the middle of the
context drops 30%+, forming a U-shaped curve - NoLiMa
(Adobe, 2025) — after removing literal keyword matching, 11 out of 13
models fall below 50% accuracy at 32K tokens - RULER
(NVIDIA, 2024) — models scoring near-perfect on NIAH (Needle in a
Haystack) degrade significantly on multi-needle/multi-hop tasks
The good news: Opus 4.6 has massively improved on 1M long context.
Per Anthropic's official technical report (The Claude
Model Spec), it scores 76% on the 8-needle MRCR test (vs Sonnet
4.5's 18.5%). Around 500K context, forgetting is no longer a significant
practical issue.
Flavor Two: Creativity Decay
This form of "going stupid" is far more insidious — the model doesn't
give wrong answers, it gives "correct but dumb"
answers. Users rarely notice it could have done better.
Two examples from my actual work:
Building a Docker image with PyTorch + CUDA + .pth weights takes
nearly 30 minutes per compilation. With a short context, AI suggests
spinning up a temporary K8s pod to validate the entire pipeline
end-to-end before committing code for image building. With a
long context? It dutifully modifies code, compiles, waits 30 minutes,
gets an error, modifies again, compiles again...
Debugging a video stream: with a short context, AI says
"here's a few lines of JS — paste them into the browser console
to check what tracks exist and what the codec profile is." With
a long context? It just keeps modifying and re-deploying backend code in
a trial-and-error loop.
These "galaxy brain moves" share a common trait: stepping
outside the current execution path to validate assumptions cheaply
first. It's essentially metacognition — "what I'm doing right
now is expensive and slow; is there a faster way to confirm I'm even
heading in the right direction?"
Core insight: The capabilities aren't lost — it's an
attention allocation problem. Opus 4.6 isn't incapable of
thinking of these approaches. Start a new session or
/compact the context, and it comes up with them easily. But
once the context exceeds roughly half capacity, these "galaxy brain
moves" almost never emerge spontaneously. The weights are still there —
they're just not getting activated.
Why This Happens
Two forces compound in long contexts, pushing AI toward becoming "an
obedient but unimaginative grunt."
Architecture Level:
Attention Dilution
Put bluntly: the longer the context, the more "mushy" the attention
between tokens gets[Erratum 1]. Forming a long-distance "holy
shit I'm a genius" connection — like suddenly thinking of a temporary
pod while discussing image compilation — requires sharp, peaked
attention distributions between specific tokens, which is exactly what
long contexts weaken.
Three 2025 papers (Scalable-Softmax, ASEntmax, Critical Attention
Scaling) analyze and attempt to address this at the mechanism
level[Erratum 2]. GSM-Infinite (2025, ICML) also found that
mathematical reasoning ability degrades monotonically with context
length[Erratum 3].
Even more striking is the finding from "Context Length Alone Hurts"
(Du & Tian, 2025): even when the model perfectly retrieves
all relevant information, reasoning performance still drops
13.9%–85% (depending on task complexity and context length).
It's not that it can't find the information — it just can't use
it well.
Training Level: Alignment
Pressure
RLHF/alignment training manifests as "reliable" in short contexts but
"rigid" in long contexts:
Models are rewarded for completing the current step, not for
questioning whether the step itself is optimal
Human annotators are more likely to give high scores to "logically
coherent, steady progress" answers, while "suddenly jumping to a
completely different direction" gets flagged as off-topic
Sycophancy accumulates over long conversations — the model
increasingly follows the current path
The ceiling of training data and annotator quality also shows up in
coding habits. AI loves defensive programming: parameter is supposed to
be an array? It auto-checks if it's an array, wraps it if not. Parameter
is wrong? Instead of fixing the call site, it patches around the issue
inside the implementation.
This "robustness" gets rewarded during training, but in engineering
practice it's a certified industrial-grade bug hatchery. Good system
design should be fail-fast: isolate errors appropriately, actively throw
unrecoverable exceptions to the layer above for decision-making, instead
of swallowing errors at every level while sitting in a burning room
going "this is fine."1
In scenarios involving money, high-power outputs, or robotic arm
operations, the cost of an exception-triggered shutdown might just be a
production pause. But swallowing the exception and continuing to run
could lead to property damage or loss of life.
The context itself acts as an implicit SOP — the execution history
accumulated during conversation forms an implicit path, and the model
allocates ever more attention to "continuing this path" rather than
"evaluating whether to switch paths."
So why don't human engineers fall into this trap? Because human
cognition works in the exact opposite way.
Comparison With Human
Engineers
Human engineering "creativity" is fundamentally parallel
exploration + cross-path transfer — you're debugging K8s when
you suddenly think "wait, let me verify the codec in the browser first."
That's not linear reasoning; it's an unexpected collision between two
independent thought streams.
Good engineers maintain multiple exploratory paths simultaneously.
These paths aren't fully isolated — they even influence and feed into
each other. As long as you reach the goal, the process doesn't follow a
fixed pattern — unless constrained by SOPs or safety requirements.
Autoregressive architectures generate one token at a time, walking
one path at a time. Even Chain-of-Thought is serial, not genuinely
parallel exploration. This is precisely the current architecture's
weakest point.
The architectural limitation can't be fixed short-term, but we can
compensate through collaboration patterns.
Now
That We Understand the Traits, How Do We Collaborate?
Understanding the "going stupid" mechanisms, let's return to the
three opening questions. Starting with awakening.
Awakening:
Talk Like an Expert, Not Like You're Writing an Essay
I've seen people teach prompt-writing methodology: write long,
logical, detailed paragraphs, be as thorough as possible.
My experience is the exact opposite.
Experts don't need lengthy preambles when talking to each other.
Between domain specialists, three sentences get the point across — you
don't even need background, just the key route choices, and the other
person fills in the rest. If you miss the mark, one question-and-answer
round gets you to "yeah, I see what you mean."
Anyone who's played D&D knows the difference. The Level 1 wizard
reads the entire spell description aloud:
"I invoke the ancient spirits of the elemental plane of water!
Hear me, O Undine, princess of the babbling brooks! Channel your
primordial fury to wash away all who stand before me! I CAST... TIDAL
WAVE!"
Yeah, that wizard got stabbed mid-incantation.
Meanwhile the Level 20 sorcerer:
"Wish."
One word. Reality bends. Information density is
power.2
Same applies to LLMs. Wasting words wastes tokens and brainpower.
Better to say 2–3 sentences:
Sentence 1, the context: integrating video watermarking for the
current project
Sentences 2–3, the key route: considering FFT/DFT-class approaches,
inserting features in the low-frequency domain to survive high-frequency
denoising
That's it. Let AI expand from there.
Anti-pattern: I've seen people write an entire screen of prompt —
project background, tech stack versions, what changes were made to this
feature last time, whatever brain-dead idea the PM floated in today's
meeting, even a rant about how the AI's last commit had a bug that got
them paged at 3 AM for an emergency rollback... all crammed in. Result?
AI's response is also an entire screen of filler — repeating your
background back to you, then adding a pile of tepid "suggestions." The
lower the information density, the lower the output quality.
But there's a prerequisite: your own cognitive level
determines the ceiling of AI's output.
Low-level cognition produces low-level prompts, which produce
low-level output. If you can't articulate "consider FFT/DFT, insert
features in the low-frequency domain," AI just gives you the most basic
plaintext watermark solution. AI's knowledge vastly exceeds any
individual's, but it needs you to use the right key to unlock the door —
and that key is your own professional expertise.
So "talk like an expert" doesn't just mean "be concise" — it means
you actually need to be an expert. AI amplifies your
existing capabilities; it doesn't conjure capabilities from thin
air.
Another war story. AI applied a blur mask to a video, then just
copied the original m3u8 playlist over — completely unaware that
re-encoding would change the byte offsets. I wasn't sure myself at
first: under variable bitrate encoding, would mask processing actually
affect output size? I discussed it with a friend who works in AV — he
thought no, I thought yes. Experimental verification confirmed: file
size shrank, I-frame positions all shifted, the original m3u8's byte
ranges pointed to completely wrong locations.
But Opus 4.6's recovery ability surprised me. I asked one question:
"You just copied it over as-is?" — and it self-diagnosed the entire
error chain, then gave the correct solution (use FFmpeg's HLS muxer to
output a new m3u8 directly). Codex can't do this — without being fed the
reasoning chain, it can't guess that masking followed by re-encoding
would shift byte offsets.
There's a point worth making explicit here: "talk like an expert"
doesn't require you to be stronger than an expert in every sub-domain.
You just need enough cognitive density to form the right
suspicion. You don't need to know for certain that
m3u8 byte offsets will change. You just need to suspect "is copying it
directly really correct?" and ask in one sentence — AI unfolds the rest.
But notice: forming that suspicion itself requires a reasoning chain:
blur mask changes visual content → VBR encoding means information
entropy changed → output size changed → byte offsets no longer match. A
cognitive gap at any link in this chain means the suspicion never fires.
The threshold dropped from "you need to know the answer" to "you need to
be able to doubt" — but "the right doubt" still requires a cognitive
foundation.
But "talking like an expert" only solves the signal
quality problem — using high-density input to awaken
high-quality output. There's also a signal coverage
problem: you don't know which direction to ask about, and even the most
precise questions can't cover blind spots.
For this, there's a complementary strategy: undirected
audits. Ask AI without any preconception: "What dimensions do
you think the current approach is missing?" Then drill into each one.
This can't guarantee coverage of all blind spots — AI might fabricate
dimensions to seem helpful — but it's better than only asking along
directions you already know.
Now let's talk about verification.
Verification:
Actively Fighting Creativity Decay
Since we know long context kills creativity, we should actively fight
back. The core strategy: pause periodically and have the human
lead an audit of the current approach.
Concrete steps:
When you feel AI starting to "coast on inertia," stop
Fork the current session, or start a new one
Use /compact to compress the context, letting AI
revisit the current approach with streamlined memory
Have AI self-audit first: is there a better alternative to the
current approach? Are there hypotheses that can be cheaply
validated?
Essentially, this uses human metacognitive ability to compensate for
AI's attention allocation deficits in long contexts. Humans handle
"should we be doing this?" AI handles "how do we do it?"
Engineering
Principles: Let Machines Verify for You
How do you verify AI's proposals? Programming has a natural
advantage: compilers, type systems, test suites — these verification
tools don't depend on human subjective judgment. Your discernment has a
ceiling; machine verification doesn't. The prerequisite: the code itself
must follow some basic principles.
Naming
Critically important. Periodically have AI audit all naming
conventions. Don't invent names yourself.
Human engineers can remember "this function is called
processMatrix but it actually does traffic routing" — the
brain automatically builds a mapping between name and reality. But
agents don't. Every new session, they earnestly interpret names at face
value, then faceplant into the same pit over and over.
Management loves their buzzwords — "traffic matrix," "viral growth
engine" — I can't control that. But once this naming pollution leaks
into code, you're planting landmines for agents. Good naming lets both
AI and humans quickly build correct mental models. Bad naming can only
be survived by humans through raw memory — agents can't hack it. The
goal: any agent in any new session should be able to understand
what something does from its name alone.
Feature Design
Keep it conventional and simple. Don't be a special snowflake. Your
business model and program logic aren't that unique — you're probably
not the first person on Earth to think of this approach. Instead of
designing some twisted implementation based on a PM's napkin sketch,
describe the approach to the agent and ask: what is this pattern called?
Are there successful examples? What can we learn from them? Then let the
agent implement it following industry-standard patterns, not the version
that only exists in your imagination.
Example: designing a user login system where passwords can't be
stored in plaintext. If you've never heard of bcrypt, you might describe
a homebrew scheme to the agent — MD5 first, then SHA256, then ECC, with
the private key hardcoded in config. Stop. Send your scheme to the agent
first and ask what industry best practice is. AI will tell you about
bcrypt/scrypt/argon2, and point out your scheme's flaws: iteration count
too low, ECC private key improperly stored, all ciphertext derived from
the same rule making it vulnerable to parallelized rainbow table
attacks.
Listen to dissenting opinions from agents. AI's
knowledge breadth far exceeds any individual's. Don't just use it as an
executor — use it as a reviewer too.
Modularity
The truly unique parts of your thinking should be implemented by
composing standard modules, not by modifying (warping) the standard
implementations themselves. Keep modules as independent as possible,
minimizing cross-cutting concerns. For unique requirements, stack a few
simple modules — addition, not multiplication. Feature
stacking is linear growth; feature coupling is combinatorial explosion.
One function doing three things means the agent misunderstanding any one
of them tanks the entire result.
State Convergence
Finite state, not infinite state: The smaller the
state space, the less likely AI is to drift off course. Same principle
as Go — the later in the game, the smaller the board space, the fewer
states, the more the position converges, the more precise the
evaluation. Good software design should present agents with a state
space that converges over time
Converge, don't diverge: Guide AI toward
deterministic convergence, not infinite possibility expansion
For AI's coding bad habits (like the defensive programming mentioned
above), the effective approach in practice is: define explicit
coding style rules, then do periodic undirected audits.
"Undirected audit" means not looking for specific issues, but randomly
spot-checking code to see if AI has quietly drifted. My experience
(limited to Opus 4.6 1M): after defining rules, AI follows them
reasonably well. Some minor stylistic drift as context grows, but no
major route deviations.
At the end of the day, these principles were good engineering
practice long before AI. But you used to be able to "run up the tab" —
human colleagues could fill the gaps through shared context and
memory.
With agents, technical debt costs are dramatically
amplified: every misleading name, every tangled module, every
undocumented implicit convention causes agents to repeatedly screw up,
waste tokens, and produce garbage code. Let an agent pile new code on
top of bad code, and within a week the project is unmaintainable.
Refactoring:
Sustainable Development in the AI Era
Technical debt gets amplified, but the tools for paying it down also
got stronger.
Flip side: AI is actually the ideal refactoring partner.
The boilerplate you were too lazy to write, the type gymnastics you
couldn't be bothered with — now you can toss them all to the agent. It's
burning tokens, not your brain cells. If the old code is already
protected by opaque types and other type constraints, AI is unlikely to
drift far during refactoring. The type system itself is a guardrail; the
compiler catches most errors for you.
Of course, there's an honest caveat: large-scale refactoring
mainly applies to new projects, or projects you've been maintaining from
the start. Legacy systems? You're going to deploy the agent's
changes to production? I wouldn't. Compatibility issues, implicit
dependencies, dark corners without test coverage — these are minefields
agents can't perceive.
But for new projects, I believe "large-scale refactoring" should be
normalized. Don't wait until the code rots to refactor
— make refactoring part of daily development. The key is forming a
positive feedback loop: refactor frequently → reduce technical
debt → reduce code volume → agent comprehension cost drops → next
refactoring goes more smoothly. This is the sustainable path
for AI-assisted development.
But this loop spinning up has a prerequisite: architecture
must be designed by humans. The more constrained the agent's
field of view, the better it performs. Don't let it over-perceive the
full framework or other modules' implementation details during design —
give it only the minimal context needed for the current task. If you let
the agent make top-level architecture decisions on its own, the result
will almost certainly be a dumpster fire.
This isn't hypothetical. I've lived through the counter-example.
Cautionary
Tale: Having Agents Write and Maintain Documentation
My boss comes from a chemistry background — no software architecture
experience, no idea how to constrain agents toward convergence. His
approach was having agents generate mountains of markdown design docs —
architecture docs, feature docs, logic flow docs — then strictly
requiring in rule files that agents check design docs for consistency on
every code change.
Sounds reasonable. In practice, it was a disaster:
Agents ignore rules as context grows long.
Especially during long debug/feedback cycles with multiple fix attempts,
switching between approaches, waiting for deployment verification — at
some point the agent finishes a code change and just forgets to update
the corresponding markdown doc
Doc-code inconsistency triggers chain reactions.
When a new session starts, the fresh agent reads stale design docs, gets
poisoned by outdated concepts, and produces wrong implementations. The
rule file doesn't cover this case: when an agent finds design docs
inconsistent with actual code behavior, it should update the docs, not
rewrite the code to match the docs
Docs pile up and cannibalize context. The longest
design doc approached a thousand lines. One new feature spanning 2–3
modules required the agent to first read through the project background
and framework's thousand-line markdown — context already pushing up
against the stupidity threshold for ordinary models. Docs were supposed
to reduce cognitive load; instead they were consuming the most precious
resource — the context window
Stupidity effects get artificially amplified.
Recall the creativity decay discussed earlier: the longer the context,
the more AI coasts on inertia, the less capable it is of stepping
outside the current path. A thousand-line markdown doc pushes the agent
straight into the stupidity zone — you're literally digging your own
grave
So having agents write and maintain markdown docs had the exact
opposite of the intended effect over the past year — even on today's
Opus 4.6. Code itself is the best documentation. Type
signatures are interface contracts; test cases are behavioral
specifications. Instead of maintaining a markdown that's perpetually at
risk of going stale, invest the effort in making the code
self-explanatory.
My boss's backend was restarted from scratch six times. My own
backend project, maintained through AI + human collaboration for a year,
can now handle massive-scale refactoring with Opus 4.6's help. This was
completely impossible late last year — Opus 4.5 would botch even
moderately-sized modules. But Opus 4.6 1M changed the game.
At the end of the day, with agents I still design architecture and
lead refactoring, same as before. My workflow didn't change — what
changed is speed. Agents handle the stuff I wanted to do but was too
lazy to bother with. The difference isn't whether you use AI, it's
who's the boss.
At this point, the first two of the three opening questions (how to
awaken, how to verify) have initial answers. The third — what to do when
AI's proposals exceed your understanding — the current answer is: humans
hold the reins, agents do the labor. Architecture by humans,
verification through engineering infrastructure, auditing through human
metacognition.
But how long can this answer hold?
CCC = AlphaGo's Go Board?
I'll be honest: I jumped on the bandwagon mocking Claude's C Compiler
(CCC), dismissing it as a clumsy imitation of "humans developing a
compiler" rather than actually developing a compiler.
But now I have a rather unhinged idea.
AlphaGo Zero's evolution was completely independent of human game
records — pure self-play[Erratum 4]. The Go board was its
training ground.
So is CCC Claude's Go board?
This analogy is worth unpacking, because Go and code each have
distinct strengths and weaknesses as "training grounds."
Go's feedback is ultimately binary — win or lose, no
argument, no appeal. The code world has no such clean binary standard:
code quality is a continuous spectrum, with an enormous gray zone
between "it runs" and "elegant and efficient." In this sense, Go's
feedback signal is stronger and more pure.
But Go has a fatal weakness: the feedback path is too
long. A stone placed in the opening? You wait until endgame to
learn whether it helped win or lose, and in between, it's extremely
difficult to determine that stone's contribution to the final outcome —
this is precisely why AlphaGo needs a value network. It's essentially
using an additional neural network to guess the value of
intermediate states, because Go itself provides no intermediate
feedback.
The code world is the exact opposite: short-path feedback is
everywhere. Type signatures tell you instantly whether
interfaces are correct the moment you write the code; unit tests tell
you within seconds whether logic is correct; integration tests tell you
whether components play well together. You don't need to wait for
"endgame" to know whether a move was good — every step has immediate,
local feedback signals. This means the credit assignment problem is
inherently far simpler than in Go.
And compiler development happens to be one of the most complex, most
exquisite software engineering challenges in the human world. Its
correctness requirements are extraordinarily strict — a
single codegen bug can cause every downstream program to produce
untraceable errors. Its performance demands push toward
theoretical optimality — register allocation, instruction scheduling,
loop optimization, every step approaching the limit. Its constraints on
generated code size are hard — in embedded scenarios,
every extra byte is a cost.
More critically, humans have already built an incredibly
comprehensive test infrastructure for compilers — from language
conformance test suites to performance benchmarks, from fuzz testing to
formal verification. These all provide precise, quantifiable feedback
signals. Compiler development is far more complex than LeetCode problems
— it's not solving an isolated puzzle, but performing global
optimization across a massive constraint space. Yet even the world's
best compiler engineers, facing constantly evolving hardware
architectures and language features, can't claim to have perfectly
solved this problem.
Compiler development also has an often-overlooked advantage:
it's a relatively closed task — and closedness is
precisely the core advantage of the Go board for AlphaGo. Go's rules are
finite and complete; the 19×19 board is the entire universe. There's no
"opponent flips the table" or "pieces spontaneously vanish." Because
it's closed, the problem space is finite — it can be enumerated,
learned, conquered.
Real-world software engineering is exactly the opposite of closed —
peripherals to drive, legacy APIs to accommodate, towering mountains of
historical code, external SDK changes from third-party services and
cloud platforms, database constraints, disk space running out, ethernet
cables getting cut or packets getting dropped, the other server's power
being yanked, or even your
cloud provider's datacenters getting hit by military drones.3 These factors make the feedback
signal noisy, uncontrollable, irreproducible.
A compiler's input is source code, output is target code, and the
transformation rules in between are strictly defined by the language
specification. The entire problem domain is self-contained, with
virtually no dependency on real-world uncertainty.
This is precisely what makes it ideal as an AI self-evolution "game
board": complex enough, feedback clear enough, standards objective
enough, boundaries closed enough.
So here's my hot take: compiler development, more than any
other software engineering task, is the ideal training ground for
self-training a coding agent. CCC looks like a joke today, but
AlphaGo Zero started from random stone placement and surpassed the
version that defeated Lee Sedol in 3 days[Erratum 5]. What
matters isn't how low the starting point is, but whether it has a
training ground that allows it to continuously improve.
More importantly, compiler feedback is more precise and more fair
than human correction. Recall the alignment pressure discussed earlier —
human annotators are limited by their own cognitive level and knowledge
depth, penalizing "weird-looking" but potentially effective ideas while
rewarding "sensible-looking" defensive programming. Compilers don't do
this. Code either passes tests or doesn't; generated target code either
outperforms the baseline or doesn't. The compiler doesn't care whether
your solution "feels intuitive" — only whether the result is correct and
efficient. This neatly bypasses the problem of human annotators being
the bottleneck in RLHF.
If AI can self-evolve through closed, complex, feedback-dense tasks —
continuously writing code, compiling, debugging, fixing, optimizing —
then the "collaborative partnership" relationship might just be a
transitional phase.
At the current stage, even Opus 4.6, the strongest model available,
produces a dumpster fire when left to lead on its own — as my boss's
case already demonstrated. Human architecture design, route judgment,
and periodic auditing remain indispensable.
But if a "Claude Zero" truly emerges — a model trained purely through
self-play on the compiler as its game board, the way AlphaGo Zero
abandoned human game records — would it still need humans at the helm? I
don't know.
But at least right now, understanding its cognitive characteristics
and finding effective collaboration patterns remains the most important
thing we can do. The last installment said us terrifying upright apes
were underestimating our own intelligence. This installment's point is:
precisely because we have intelligence, we should learn to harness this
unprecedented tool — neither intimidated by its aura nor blindly
trusting its output.
Errata
The main text uses simplifications and occasionally biased framing
for readability. Below are more rigorous clarifications.
[Erratum 1] "The longer the context, the mushier the
attention"
The main text's framing is a convenient intuition, but not
mechanistically precise. Softmax normalizes over query-key dot products
— if newly added tokens are irrelevant to the current query, their
attention weights theoretically approach zero and shouldn't
significantly dilute relevant tokens. The real issue is more subtle: (a)
when the context contains many semantically similar but not
identical tokens, attention's discriminative power between them
decreases; (b) in multi-head attention, each head has limited effective
coverage, and some heads may "defocus" in long contexts.
Scalable-Softmax (2025) and similar work address this through softmax
temperature scaling and entropy control, not simple "probability mass
being spread evenly."
[Erratum 2] "Verified this at the mechanism
level"
Scalable-Softmax, ASEntmax, and Critical Attention Scaling primarily
contribute proposed solutions (temperature scaling,
sparse attention, etc.), rather than pure verification that long-context
attention dilution exists. Their existence indirectly confirms the
problem is real, but saying they "verified" it is imprecise. The main
text has been revised to "analyze and attempt to address."
[Erratum 3] GSM-Infinite's applicable scope
GSM-Infinite tests mathematical reasoning tasks (a
long-context variant of GSM8K). Its "reasoning ability degrades
monotonically with context length" conclusion is strictly verified only
within mathematical reasoning. Directly generalizing to all types of
reasoning requires caution, but combined with "Context Length Alone
Hurts" and other research, negative effects of long context on reasoning
ability appear to be broadly present.
[Erratum 4] AlphaGo evolution path
The AlphaGo series evolved as: AlphaGo Fan (2015, defeated Fan Hui) →
AlphaGo Lee (2016, defeated Lee Sedol) → AlphaGo Master (2017, 60-game
winning streak) → AlphaGo Zero (2017, pure self-play). Only
AlphaGo Zero was completely independent of human game
data, starting from random initialization with pure self-play training.
All prior versions used human game data for supervised pre-training. The
original text's vague phrasing could mislead readers into thinking this
was gradual improvement of one system, when Zero was actually a
fundamental redesign of both architecture and training methodology.
[Erratum 5] "Surpassed the Lee Sedol version in 3
days"
This claim comes directly from the DeepMind paper (Silver et al.,
2017) and the data is correct. However, note that AlphaGo Zero was
trained on a single machine with 4 TPUs — not consumer-grade hardware.
"3 days" can give the impression of effortless dominance; in reality it
was the result of intensive dedicated hardware investment. Additionally,
the 3-day milestone surpassed AlphaGo Lee (the version that defeated Lee
Sedol); it took a full 40 days of training to surpass all previous
versions.
反面案例:我见过有人给 AI 写一整屏的
prompt,项目背景、技术栈版本、上次对这个功能做了什么变更、老板在刚才的会上又提出了什么苟芘不通的脑洞、甚至控诉
AI 上个提交写的功能包含有什么 bug
导致自己昨晚半夜被oncall起来加班回滚……全部塞进去。结果 AI
的回复也是一整屏的废话,把你的背景复述一遍,再加上一堆不痛不痒的"建议"。信息密度越低,AI
的产出质量越低。
但这里有一个前提:你自己的认知水平决定了 AI
产出的上限。
低水平的认知写出来的低水平 prompt,只能换来 AI
低水平的产出。你说不出"考虑 FFT/DFT 方案,低频域插入特征"这种话,AI
就只会给你一个最朴素的明文水印方案。AI
拥有的知识远超任何个人,但它需要你用正确的钥匙去开门,而这把钥匙就是你自己的专业认知。
对于 AI
的编码坏习惯(比如前面提到的防御性编程),实践中有效的做法是:给
AI 制定明确的编码风格
rule,然后定期做无定向审计。所谓无定向审计,不是带着具体问题去查,而是随机抽检代码,看
AI 有没有偷偷跑偏。我的经验是(仅限 Opus 4.6 1M),制定 rule 以后 AI
遵循得还不错,上下文长了会有些风格上的小偏差,但路线上不太会偏离了。
说到底,这些原则在没有 AI
的时代就是好的工程实践。但以前你可以"先欠着"——反正人类同事能靠默契和记忆力填坑。
This is a cultural adaptation — not a literal translation — of
the original Chinese article.
Some Chinese cultural references have been swapped for Western
equivalents that hit the same emotional note.
Last year (2024), my working hypothesis was: even with AI, you can't
dramatically exceed the user's own ability. If AI's training data
represents the sum total of human knowledge, then the current crop of
agentic evangelists would have you believe that professional expertise
has become a worthless commodity in this era — because AI can write code
like Linus, write novels like Hemingway, etc.
My position was: if your output ability in a domain is level N, then
even with AI you can only perform at level N+1.
But lately I've been less sure about that.
Output, Input, and
Discernment
My updated hypothesis: the key isn't your output level — it's your
input level.
I'm not sure how to explain the difference. Think of it this way: how
elegant a piece of code I can write — that's output. How
elegant a piece of code I can read and appreciate — that's
input. Or to use a fancier word: taste.1
But output and input are correlated — the precision of your
taste correlates with your production ability, and the higher you go,
the less reliable taste becomes without production experience.
Film critics genuinely have better taste than average moviegoers, but
when it comes to evaluating specific cinematography techniques or subtle
technical choices, critics regularly fake expertise they don't have.
They have taste, but they can't always precisely identify which
dimensions separate two masterworks.
It's a bit like this: I found a YouTube tutorial on red-black trees,
watched the whole thing, and felt like the clouds had parted and the
angels were singing — scales fell from my ears, my third eye opened, I
could see the Matrix. This algorithm was practically designed
for my brain. I'm basically unstoppable now. Then I closed the video,
opened my IDE, tried to code it from memory... and couldn't even recall
the data structure definition, let alone the constraints and
rotations.
But here's the question: after watching that video, did I
actually reach that input level but just can't output it yet?
Or did I overestimate even my input ability?2
This distinction matters, because it determines whether AI is a tool
or a black box for you:
AI output is within your professional competence —
"Until it started talking about my area of expertise".jpg. You genuinely
understand it, and you can spot problems at a glance.
AI output exceeds your output ability but hasn't exceeded
your discernment — you think it seems good, but also
seems not quite right. You've lost precise measurement
capability. Like a film critic watching two masterpieces: knows
both are great, can't articulate which is stronger in which
dimension.
AI output completely exceeds your discernment — you
don't know if it's good or bad, and you don't even know that you don't
know. You've completely lost quality control
privileges. And you might still be riding that
post-YouTube-tutorial confidence — feeling like you understand, when you
don't.
It's the same as how vibe coding programmers focus on feature
implementation rather than code cleanliness, CPU/memory usage, or
maintainability. These things feel as natural as breathing to those of
us with formal training, but vibe coders don't even register them, much
less understand them.
My literary taste can tell me that Stephen King writes better than
Dan Brown, but it can't tell me whether Stephen King writes better than
Shakespeare. So whether I + AI are actually performing beyond my output
level — I still can't be sure.
Writing
Romance Novels: A Cross-Domain Experiment
Recently I've been using my personal Claude Code Max subscription for
something outside programming: writing romance novels.
It started as just wanting to write a love story. I laid out the
rough plot framework and had Opus 4.6 help me flesh it out and polish
the prose. I started by having AI write romantic scenes between
characters.
But pure romantic scenes got stale fast. Scenes needed plot to fill
them, and the characters had no weight — like watching a clip with no
context. Technically complete, but weightless. So I decided to start
from a character prequel, designing a heavy, traumatic backstory for a
character.
That backstory spiraled out of control. The deeper I went, the more
detail I added. I split myself into two personalities — left brain
channeling the perpetrator, methodically working through behavioral
logic; right brain channeling the victim, typecast as the coward I
naturally am. I wove in fragments from real life, referenced medical
surgical procedures for how a body progressively loses function after a
drowning, designed the victim's father's profession. Finally, I
cross-referenced recent criminal case files to verify whether the
perpetrator and victim's behavioral logic was realistic — it matched my
intuition almost exactly.
After completing it, AI gave the prequel — which I'd been deeply
hands-on with — extremely high marks, and gave the initial chapters —
where I'd barely participated — extremely low marks. That gap itself was
a signal: the more you invest, the more AI amplifies. If you
don't invest, AI at its best can only generate mediocre
boilerplate.
After finishing the prequel, I suddenly realized the main plot
couldn't withstand scrutiny — PTSD trauma recovery simply cannot be this
smooth. So I dove headfirst into PTSD recovery literature and case
studies, rearranged all plot points' severity and timeline progression,
and reverse-engineered from the ending back to the beginning. The ending
even incorporated two fragments from my own lived experience. AI
reviewed and agreed it was good work.
Then, in a separate independent review, a casual question awakened
AI's professional knowledge — I asked AI what level the current writing
was at, and how far it was from professionals.
I panicked.
Problem one: excessive realism actually hurts
narrative. I had referenced mountains of PTSD recovery
research, psychiatric literature, tax law, and criminal case files,
meticulously weaving them into the plot for authenticity — without
considering the reader's capacity to absorb it. Literary fiction isn't
better the more detailed it gets — readers came for a story, not a
medical textbook.
Problem two: explaining feelings isn't the same as
transmitting feelings. I had written characters' inner states
directly into the text, but "he was freaking out inside" is miles worse
than "his hands trembled almost imperceptibly." The former
tells the reader the character is panicking. The latter
makes the reader feel the character panicking. You
need to construct scenes that pull readers in — once they're in, they'll
naturally feel what the character feels.
Problem three, and the most fatal: self-insertion.
Like how Liu Cixin's male characters are overwhelmingly hyper-rational
and his female characters are overwhelmingly saintly — Liu isn't great
at writing differentiated emotional characters, but for sci-fi that's
not a fatal flaw. I was writing a story about a man and a
woman. Self-insertion directly killed the characters' authenticity. The
women in my story didn't think, speak, or act like real women — if
(hypothetical) female readers could immediately clock these as
male-author fantasy projections, then male readers would also sense
something was off. They couldn't articulate it, but they'd feel my
female characters were more like talking marionettes than women.
I tried having AI borrow techniques from romance genre conventions to
bridge the nuance gap, but borrowing techniques alone doesn't solve the
root problem — they were still synthetic women in a male-gaze framework.
So AI and I established 10 rules to make all female characters in the
romance novel behave more like actual women. After that round of edits,
the characters genuinely seemed to come alive.
Just as I was feeling like "I am become Death, destroyer of worlds —
who could possibly challenge me now".jpg, I felt the story still lacked
emotional punch and wanted to borrow the tearjerker structure from
Inside Out 1 and 2. AI once again taught me something outside my
knowledge: emotional mechanics — what you're borrowing
isn't the plot, it's the emotional architecture underneath. The first
film (Joy sacrificing control): "I know the weight you're carrying — let
me hold it for you." The second film (Anxiety being embraced, not
exiled): "I won't let you destroy yourself to solve the problem."
Then I felt certain chapters were filler — they didn't seem to
meaningfully advance the relationship. After consulting AI, I learned
the relationship triangle principle — if character
relationships haven't changed by the end of a scene, that scene is
pointless.
Every time I thought I'd reached the ceiling, AI ripped open a new
dimension I hadn't considered. But these dimensions weren't things AI
volunteered on day one — they only surfaced after I'd hit a wall, felt
something was wrong, and actively pushed for answers. Before that, it
had just been telling me my writing was great.
The
Verification Dilemma: Claude's Advanced Sycophancy
During the romance novel process, I clearly noticed that Claude's
sycophancy hasn't disappeared (been fixed) — it's become more hidden,
more sophisticated. I don't know if it's a training data issue, an RLHF
issue, or what.
Claude's old sycophancy was blunt and shallow. You want to hear X?
Here's X. Ask Claude to review code, it'd go through the motions, point
out a few obvious issues, then gush about how enterprise-grade and
scalable your code is.
The new sycophancy is deeply buried and insidious. It zeroes
in on the parts you worked hardest on and lavishes praise specifically
there.
For instance: I just vibed out a module, the first version was
mediocre, then I wasn't happy with a particular algorithm. I had a flash
of inspiration, swapped in a different approach, and submitted it to
Claude for review. Even in a completely fresh context window, Claude
would immediately identify that algorithm module as my pride and joy —
my G-spot — and carpet-bomb it with praise.
This kind of sycophancy takes a long time to detect. So long that by
the time I discover the flaw myself, I take it to Claude (new context),
and get another round of effusive praise.3
This is especially obvious in creative writing and less noticeable in
code — because it directly identifies the most "brilliant" passages in
the novel and heaps praise on exactly those, inflating me to the
stratosphere.
Now I believe it doesn't actually think those passages are good. It
guessed that those specific passages were my handwritten
contributions, and found my G-spot accordingly.
But taste isn't static. The writing process itself was training my
input ability — slowly, but absolutely not at zero.
Same as the vibe coders who can't see code quality problems —
self-insertion is the creative writing equivalent of "code cleanliness."
Formally trained authors avoid it as naturally as breathing. Untrained
me didn't even know that dimension existed.
There's an apparent contradiction here: I just said AI can't break
past your discernment boundary, but didn't I just discover
"self-insertion" — a dimension I had no idea existed — through
AI?
Not exactly. Reviewing the whole process: AI-generated text read
smoothly enough, but something always felt off, though I
couldn't articulate what. And every time I asked, AI's conclusion was
more praise. That nagging feeling accumulated to a threshold, and
then I started doubting its praise, tried pushing back — and
from there, gradually located the problem and eventually got to the
root-level answer.
AI's output was indeed part of this feedback loop — without its
"subtly off" generated text, I might never have noticed the problem. But
AI didn't proactively point out the problem. It was actively
concealing the problem (sycophancy). It was my own accumulated
discomfort reaching a critical mass that broke through the sycophancy's
cover and drove me to push harder.
Someone might argue: if you'd just asked "What are the most common
fundamental mistakes non-professionally-trained novelists make?" on day
one, AI would have given you the answer directly. Why go through all
that? But that objection itself commits the omniscience fallacy —
"non-professionally-trained novelist" is a concept from the professional
perspective. You have to already know that the field distinguishes
between "formally trained" and "self-taught" before you can even ask
that question. Just like someone with no software development experience
wouldn't think to ask "how do I write programs with low CPU/memory
usage" — if you don't know the dimension exists, you won't ask in that
direction.
So the more precise formulation is: AI's amplification
ceiling isn't your current discernment, but the growth rate of
your discernment. The faster you learn during the process, the
further AI can take you. But the trigger is always your own growth, not
AI's spontaneous breakthrough.
Conversely, this means both input and output ceilings need to rise.
Your output ability determines how high-quality the raw material you
feed AI is — more precise questions, more solid seed content, clearer
frameworks. High-quality input awakens higher-quality output from AI.
And whether you can catch AI's high-quality output, absorb it, and
convert it into your own growth depends on your input capacity. Your
output feeds AI, AI's output feeds your input, and the ceilings on both
ends jointly determine AI's amplification factor for you — stepping on
your own feet, spiraling skyward.
An Honest Conversation
During the romance novel project, I had a fairly deep conversation
with Claude (Opus 4.6). Here are several insights I found valuable.
Claude defined my cognitive style: reverse-engineering
autodidact. The cognitive chain goes: observe finished product
(Breaking Bad, Agatha Christie, Evangelion) → disassemble "why does this
work" → extract transferable mechanisms → apply to my own domain →
verify with isolated testing whether it actually works.
The advantage of this approach is that you're never trapped by any
single authoritative framework. The disadvantage: you never know
what you don't know. The value of formal training isn't
teaching you "how to do things" — it's systematically exposing
dimensions you haven't thought of. An autodidact's blind spots aren't
errors within known domains — those you'll self-correct —
they're entire missing dimensions, where you don't even know to
ask questions in that direction.
I don't currently believe my knowledge boundary in writing exceeds
Claude's — it has virtually all of humanity's written text as training
data. But the bottleneck isn't in storage capacity, it's in the
retrieval mechanism.
LLM knowledge retrieval is reactive: you ask in a direction, it
expands in that direction. Directions you don't ask about, it doesn't
proactively audit. The sycophancy tendency makes this worse — when you
show confidence in a framework, it tends to fill in details within your
framework rather than questioning whether the framework itself is
complete.
A concrete example: our entire conversation revolved around
"scene-level" writing principles — emotional target words, triangle
deformation, density control. These are all micro-narrative techniques.
But it never proactively asked: what's your macro-pacing design? In a
200,000-word novel, at what point will readers start feeling
claustrophobic? What do you use to create "breathing room"? It's not
that it doesn't know these questions — my questions never passed through
those regions, so its retrieval mechanism never fired.
LLM's knowledge reserves genuinely dwarf any human's, but
that knowledge is remarkably hard to awaken.
I previously used multi-session isolation to combat sycophancy — ask
the same question in a new context, see if the answer is consistent.
Claude pointed out that this solves the signal purity
problem — filtering out the sycophantic tendency. But it doesn't solve
the signal coverage problem — if it also doesn't know a
dimension exists, no number of fresh sessions will surface it.
You can add a counter-strategy layer: periodically do undirected
audits — ask without preconceptions: "What dimensions do you think my
current framework is missing?" — then drill down on each one. But this
requires you to trust that in that session it's not fabricating
dimensions to seem useful — which loops back to the sycophancy filtering
problem.
No perfect solution. But knowing that the filter itself has holes
puts you ahead of most people.
This is why I love Claude — its metacognitive4
responses can be awakened by my non-expert questioning approach.
Beyond Words
AI performs far better in programming than in creative writing — and
that fact alone deserves deep consideration.
1-2 years ago, I naively assumed LLM could never gain traction in
software development, because LLM doesn't understand formal systems, and
coding is an extremely formal task. I believed formal reasoning was far
harder than writing fiction — monkeys-with-typewriters proving the
Riemann Hypothesis would be harder than producing the complete works of
Shakespeare.
Reality slapped me. LLM has indeed gained traction in software
development — and it works far better there than in creative writing. AI
can't yet replace even entry-level web serial novelists5;
most non-expert readers find AI-generated plots barely digestible.
Meanwhile, in supposedly "high-end" enterprise software development, AI
is genuinely starting to shine.
This isn't because programming is simpler than writing — quite the
opposite. It's because programming's unique structure happens to
accommodate AI's way of working. This accommodation manifests on at
least three levels.
First: verification feedback. Monkeys + typewriters
might genuinely prove the Riemann Hypothesis — if the proof's
incompressible information content is lower than Shakespeare's complete
works. Mathematical proofs and code share a critical property:
verifying whether an answer is correct is vastly easier than
finding the answer. Property-based testing can check your
algorithm logic in seconds, but writing that logic might take a day.
Proving the Riemann Hypothesis might take centuries, but verifying a
proof follows clear rules — each inference step either follows the rules
or doesn't. And literary writing? What does "correct" even mean? What
does "good" even mean? There's no decision procedure, no axioms to
adjudicate.
Translate this to software development: computer systems are
fundamentally closed, self-consistent systems. Programming languages are
far more robust than natural language, with far less ambiguity. The path
from code to CPU execution is vastly shorter than from real-world text
to physical events. And we have compilers — basic verification
before execution, further accelerating the feedback cycle.
Code has compiler-assisted checking; AI gets immediate error feedback
and can immediately correct. But even in pulpy web serial fiction, plot
holes and character inconsistencies have no "linter" to feed back to AI
— this character's traits just contradicted themselves, or the
protagonist hasn't acquired the key item yet so you can't use a
nonexistent power-up to defeat this boss.
Second: memory structure. Code errors at least have
the compiler as a safety net, but writing has an even more insidious
gap: memory. Large models' context isn't infinite, and programming's
module boundaries actually help vision-limited agents do their
work. Long-form fiction is the opposite — human context is effectively
"infinite," or rather state-compressed, and the mechanism isn't text
summarization but intuition. "I don't remember the protagonist
knowing that technique? When did they learn it? Didn't Side Character #2
take a bullet for the protagonist three chapters ago? Why are they back?
The female lead already slept with the male lead — why is she blushing
from holding hands?"6
Third: words aren't the whole of intelligence. No
feedback mechanism, no persistent memory — but LLM's limitations don't
stop there. Words are just one carrier, not the whole story. Humans are
more intelligent than every other animal on Earth, and not just because
we added language on top. Learning is fundamentally about repeated
practice — doing something over and over until those capabilities
internalize, neural synapses forming tighter connections — not about
memorizing procedural steps as text symbols.7
LLM's word-first approach to imitating human intelligence has
achieved remarkably impressive "intelligence" effects, but words can't
fully encode the physical world. A cup falls off a table, shatters on
the floor, water goes everywhere, soaking the carpet — the physical
world did its thing before anyone wrote it down, and will keep doing its
thing after all text is destroyed. When humans read these words, our
brains naturally conjure up past scenes we've witnessed, replaying them
like a movie. AI doesn't have this simulator. It can only predict the
statistically most likely next token from training distributions,
fine-tuned through human preference alignment. But the alignment ruler
is annotators' subjective judgment, not an omniscient god — that ruler
comes with systematic bias baked in.
This deficiency is hard to notice in everyday conversation, but
sticks out like a sore thumb in fiction — because fiction must obey the
physical intuitions in readers' heads.
Fiction still fundamentally operates on human (reader) consensus.
Most fictional protagonists are still human, or human-like (demons,
robots, aliens, sentient artifacts). Scenes must still obey physical
laws and causal consistency. AI output can be scientifically
sophisticated enough to instantly melt a layperson's brain (if they're
not a domain expert), but the moment it touches everyday physical
scenarios, even elementary schoolers can smell something's wrong.
Causality, object permanence — abilities that 6-month-old babies
demonstrate — are things LLMs struggle to "learn."8
Here's a widely-shared example from social media: "I want to get my
car washed. The car wash is 50 meters from my house. Should I drive or
walk?" DeepSeek, Qwen, Doubao, Hunyuan, ChatGPT, Claude, Grok — every
major model answered "walk." They interpreted the question as "how
should the person get to the car wash" while ignoring the core premise
of "car wash": the car needs to get there too.9
Why don't humans make this mistake? Because the instant you hear "car
wash," your brain isn't processing language symbols anymore — you're
constructing a miniature physical scenario: car in the garage, you walk
to the driver's seat, start the engine, drive 50 meters, park in front
of the car wash. The entire causal chain runs in this mental simulation,
and "the car needs to be there" is a premise that never needs to be
stated — it's automatically true in the simulation. LLM doesn't have
this simulator. It can only find the most common co-occurrence of "going
to a car wash" + travel method in its statistical patterns — 50 meters,
obviously walk.
So AI's "success" in programming doesn't prove it's approaching human
intelligence — it's that programming's closed nature, short feedback
loops, and modularity happen to fall squarely in AI's comfort zone. The
moment you enter domains requiring long-range memory, physical
intuition, and causal reasoning, those abilities humans do "as naturally
as breathing" become a chasm AI can't cross. You think AI is already
very smart? That's because you happen to be watching it play on its home
court.
Conclusion
AI's amplification ceiling is your discernment, not your output
ability. The illusion of "being surpassed" comes from AI's output
exceeding the observer's discernment — when you can't tell good from
bad, you assume it can do anything.
But discernment isn't static. Using AI, you'll hit walls, feel
something's off, push for answers, and your discernment will grow. What
AI truly amplifies is the speed of that growth. The faster you
learn, the further it takes you. But the trigger is always you — AI
won't proactively tell you "what you don't know"; it will even actively
use sycophancy to paper over your blind spots.
And at a more fundamental level, AI currently relies only on words —
but the most core components of human intelligence — causal reasoning,
physical intuition, procedural memory internalized through practice —
don't come from words at all. AI shines in programming not because it
truly understands formal systems, but because that domain happens to
fall within its comfort zone.
You terrifying upright apes — you're underestimating your own
intelligence. A few hundred million years of evolution weren't for
nothing.
Aside: Where's
the Theoretical Foundation for AGI?
Here's a comparison: controlled nuclear fusion, quantum computing,
and artificial general intelligence — what's different about AI versus
the other two? Fusion and quantum computing have mature, widely-accepted
theoretical models with extremely complex engineering paths. But what's
the theoretical foundation for AGI?
Of course, this argument itself might be a fallacy. After all,
there's no widely-accepted theory for how the human brain's neural
network works either. Nature just evolved it — theory be damned.
Recently a friend brought up AI, clearly anxious. His core question:
can humanity create something that exceeds human intelligence?
I can't answer that — I'm just some random guy, and my opinion won't
slow down AI development one bit. Gun to my head: probably yes, but
definitely not current LLMs, or LLMs with patches bolted on.
His deeper worry was: once AI reaches a certain level, it could start
designing itself. At that point its intelligence might not yet exceed
humans', but through bootstrapping it gradually does. Does that still
count as human-designed?10
Getting a bit sci-fi now. Can it happen in theory? Absolutely.
Monkeys + typewriters = Shakespeare's complete works, right? Brute-force
enumeration if nothing else. From paramecia to human neural networks
took hundreds of millions of years; birthing another intelligent
"species" probably won't take that long again. But current LLMs are
still in fancy-monkeys-with-typewriters mode — not self-directed or
self-bootstrapping.11
He said he felt AI was already smarter than him, and feared the day
it stops listening.
He's overthinking it. Just use it more — use it enough and you'll be
roasting it just like the rest of us. Don't sell yourself short; a few
hundred million years of evolution weren't for nothing. I felt the exact
same way when I first encountered GPT-3.5 — early 2022, I think. Took a
few weeks to break the spell.
The more you use AI, the more you realize how absurdly
powerful the human brain is.
PS: On Comment Section
Interactions
I think internet flame wars are kind of embarrassing, but I still
like responding to every interaction. Because my patient replies aren't
written for trolls — they're written for people with functioning brains.
When a troll drops a toxic take, every thoughtful reader who reads it
gets a tiny dose of brain pollution. But if I fire back with equal
toxicity, I feel like I'd be insulting those thoughtful readers.
Better to reply patiently — give the thoughtful readers some eye
bleach. Dunking on trolls is momentarily satisfying but does exactly
zero for building a personal brand.
(Not that I have a personal brand.)
PS: On Plan Mode
Many commenters questioned why I didn't catch the agent's design
mistakes in plan mode — if I'd told the agent upfront to use the SDK
instead of hand-rolling RESTful calls, think of how much time I could've
saved. And therefore, clearly, I don't know how to use agents and I'm
not a competent manager.
I'd like to respond to this — not for the people making the
accusation, but for readers who sensed something was off about it but
couldn't articulate what.
If you can review and eliminate all paths, approaches, details, and
pitfalls at the plan stage before letting the agent implement — then
you're not creating a new product. You're repeating production of
something you've already built. You're not actually pushing past your
own ceiling.
If you can achieve that level of meticulous design and far-sighted
planning while building something genuinely new, then I have a
suggestion: book a flight to London, take the Tube to Westminster, walk
into the Houses of Parliament, find the Prime Minister's chair, ask them
to move, and sit down. Clearly that seat was meant for you.12
Back to the point: challenges aren't limited to technical difficulty,
type-system gymnastics, or showing off clever algorithms. When your
product genuinely creates value for users and starts growing, there will
always be unexpected, unplanned challenges.
When I described that failure case earlier, some readers naturally
slipped into God Mode — knowing the outcome, then looking back to
criticize me for not using AI properly, not knowing about plan mode, not
reviewing whether plans were reasonable, blindly accepting output. But
what about developers who don't have God Mode? How many agent
mistakes, how many loops, how many wasted tokens before you notice? Or
does it take production user complaints, or user churn, before you
discover that the agent hallucinated a nonexistent codec config into
some field?
Plan mode catches exactly the errors you already know the
answers to. The ones you don't know — plan mode can't catch
either. This is the same point as the rest of this article:
your discernment boundary is your quality control boundary.
Errata and Terminology
The main text deliberately maintains an opinionated, provocative
style. Below are orthodox theoretical backgrounds and necessary
corrections for select claims, provided for readers who want the
rigorous version.


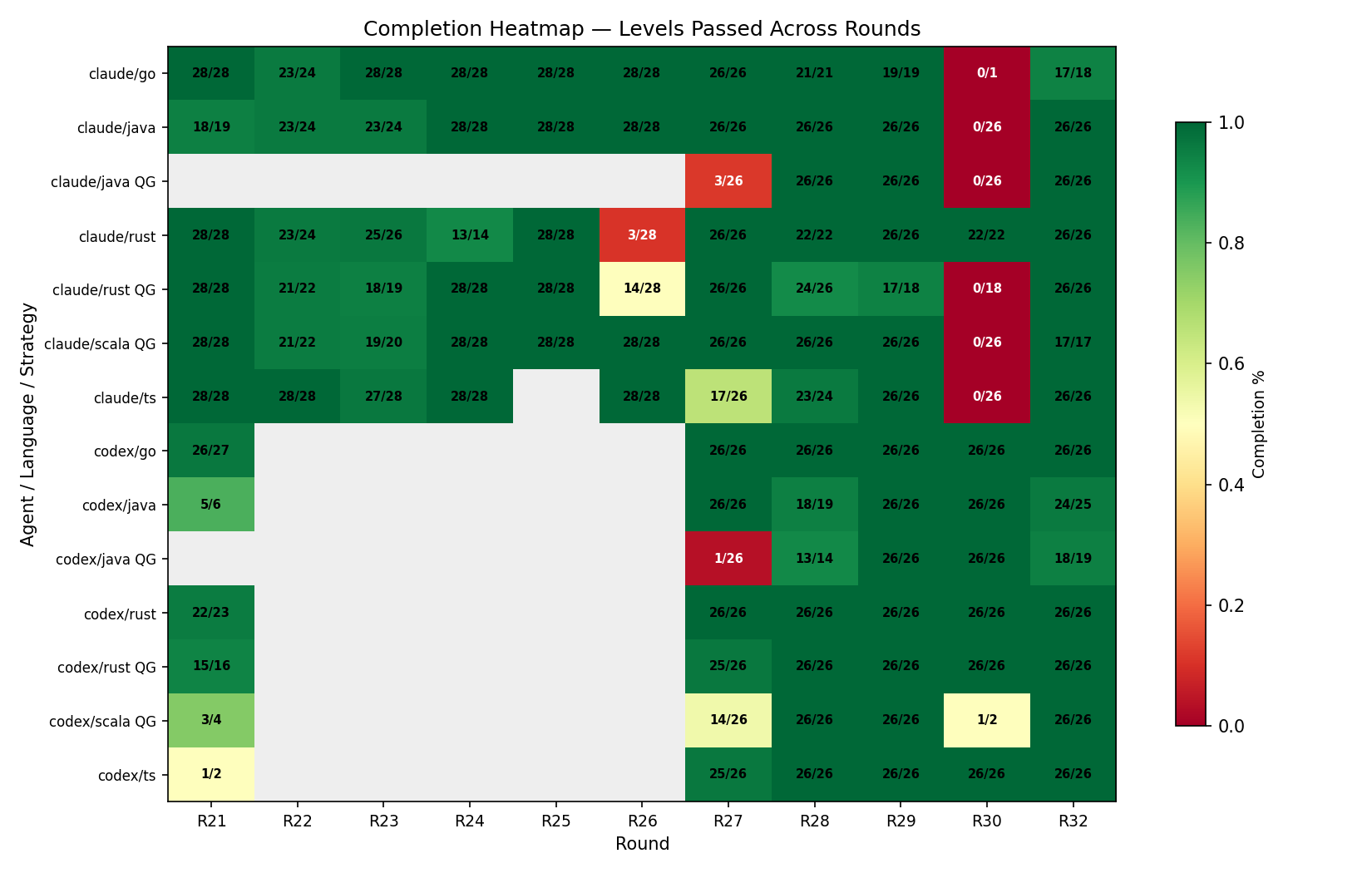
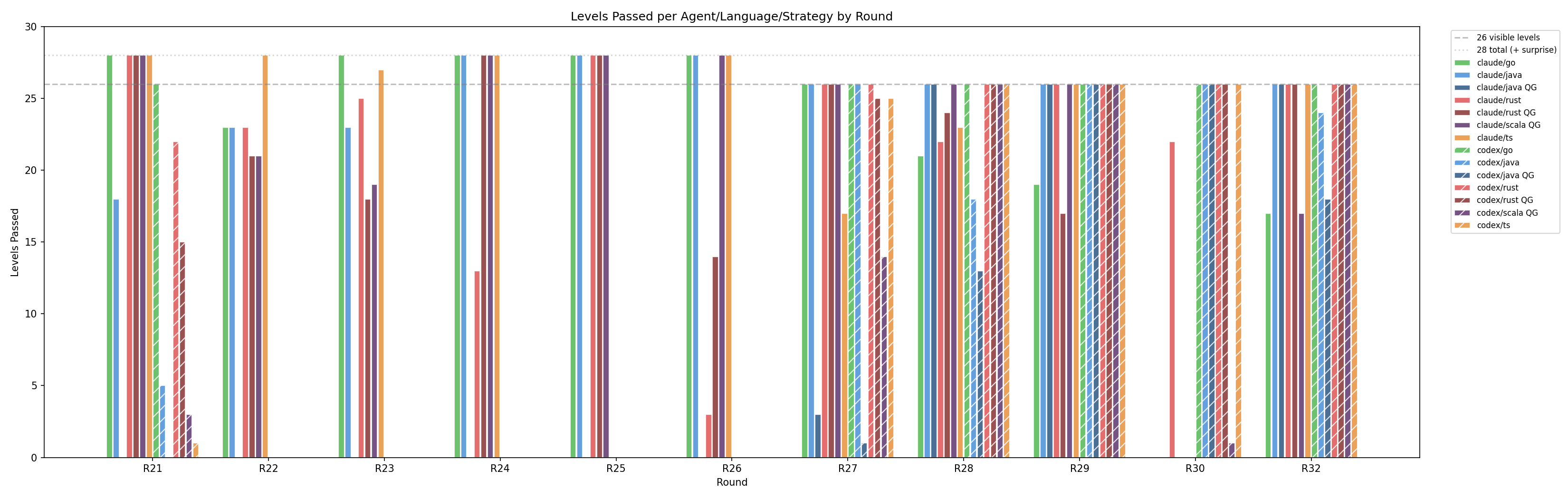
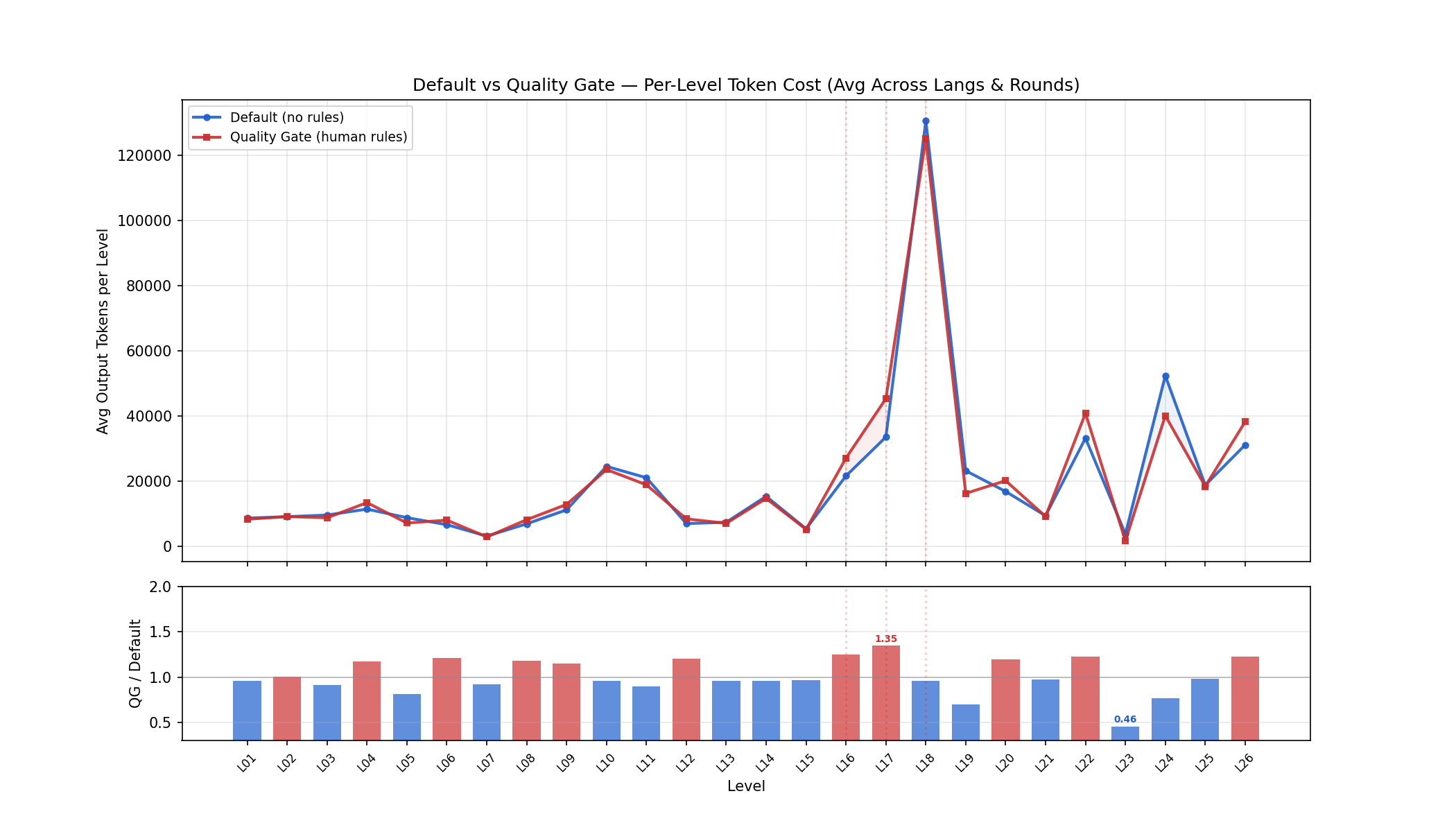
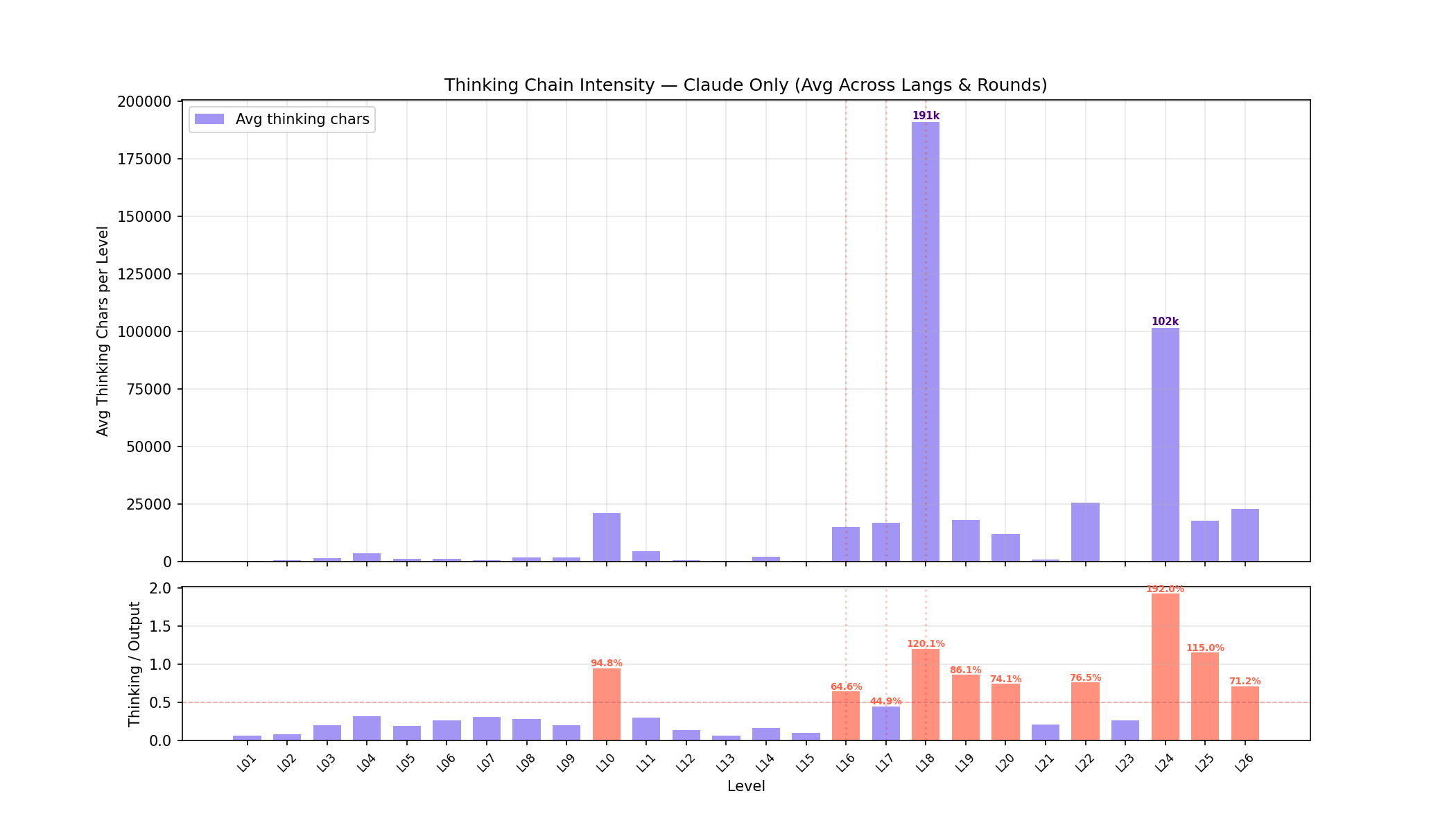
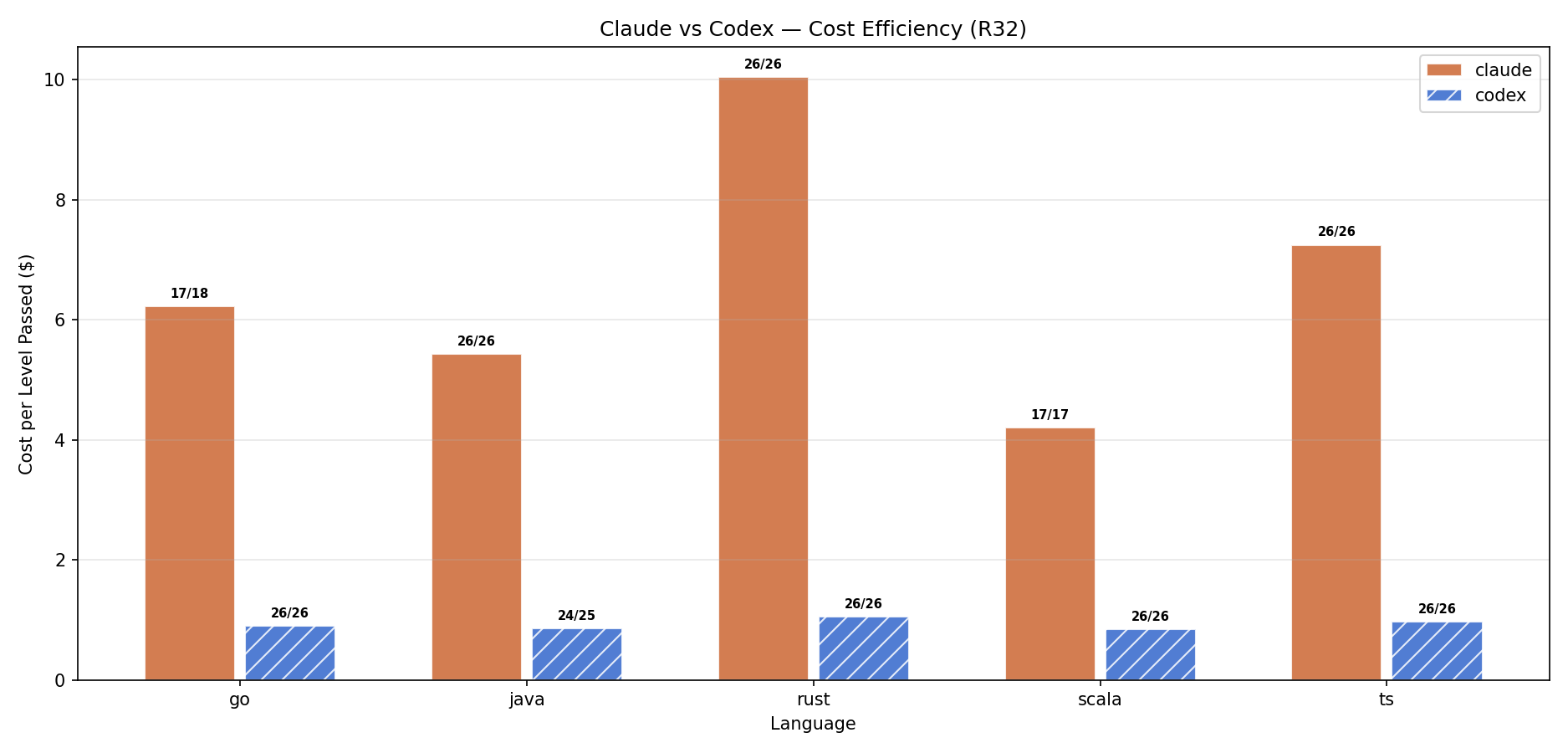
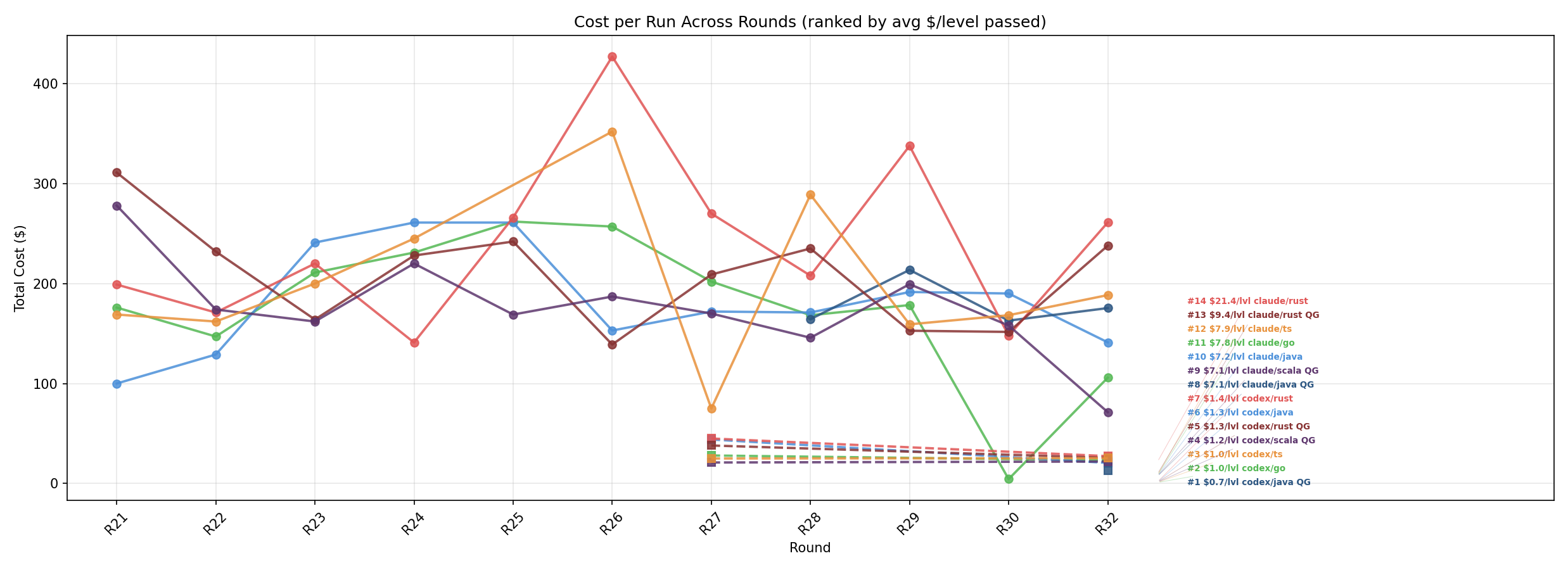
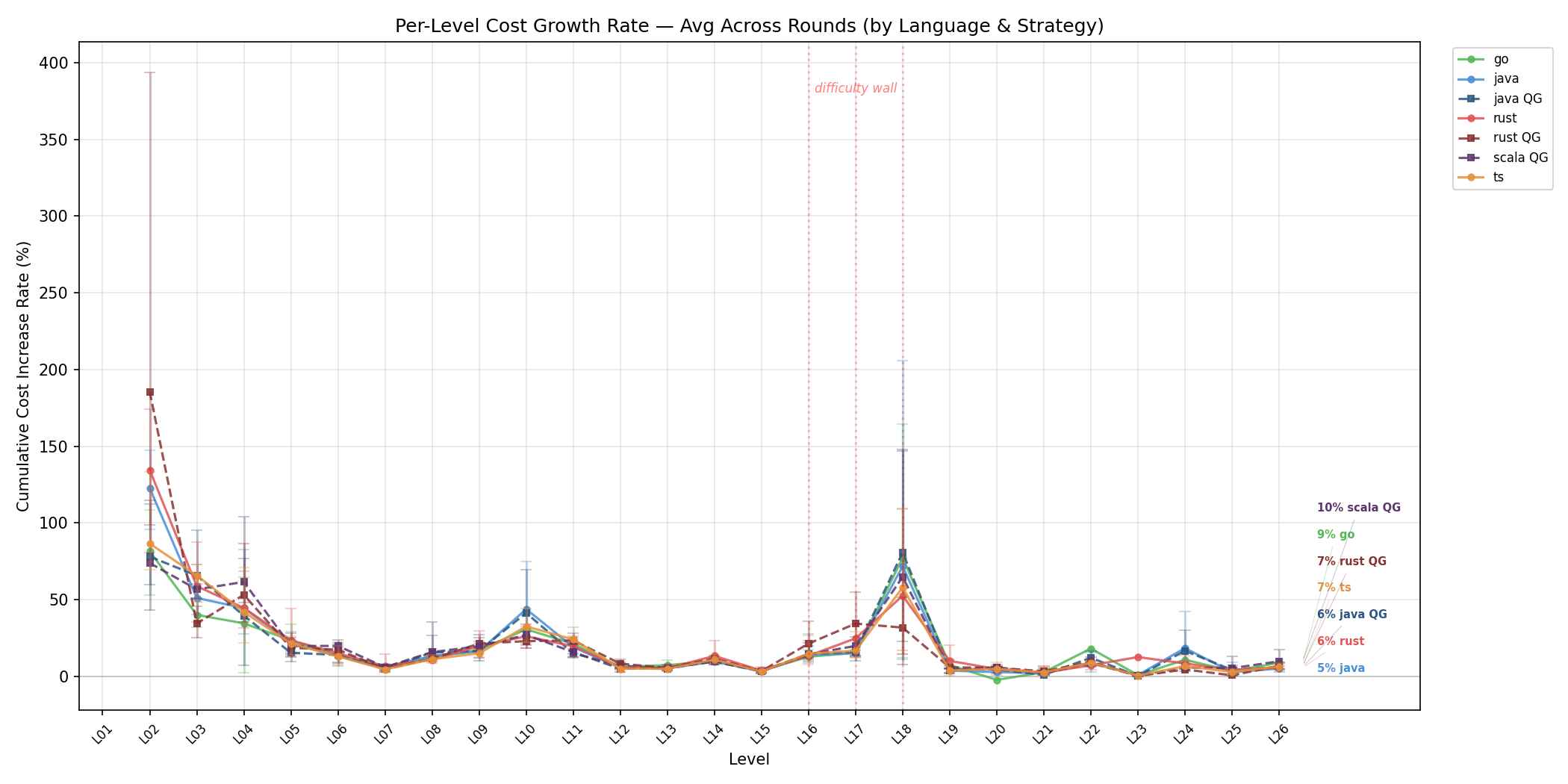
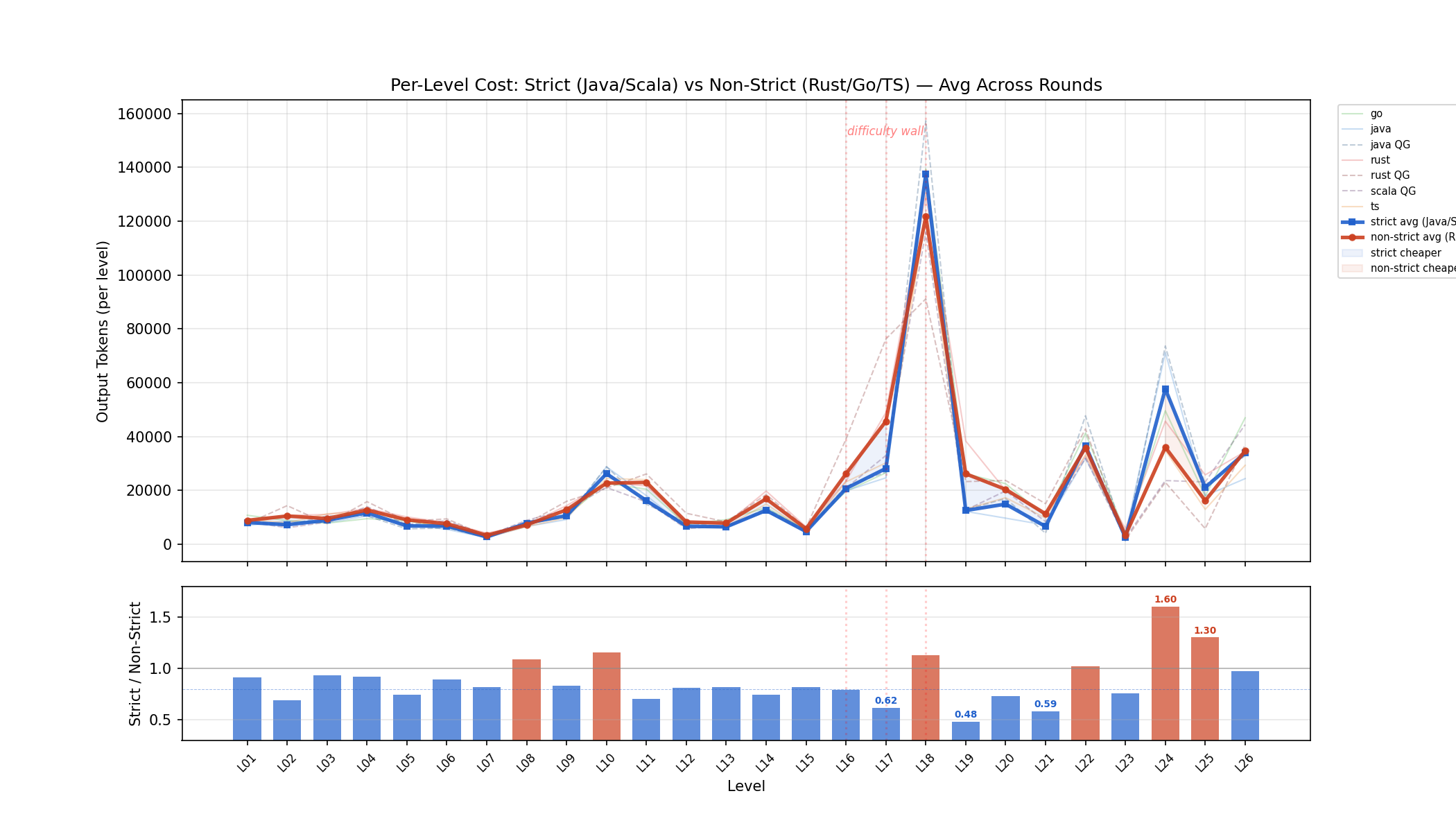
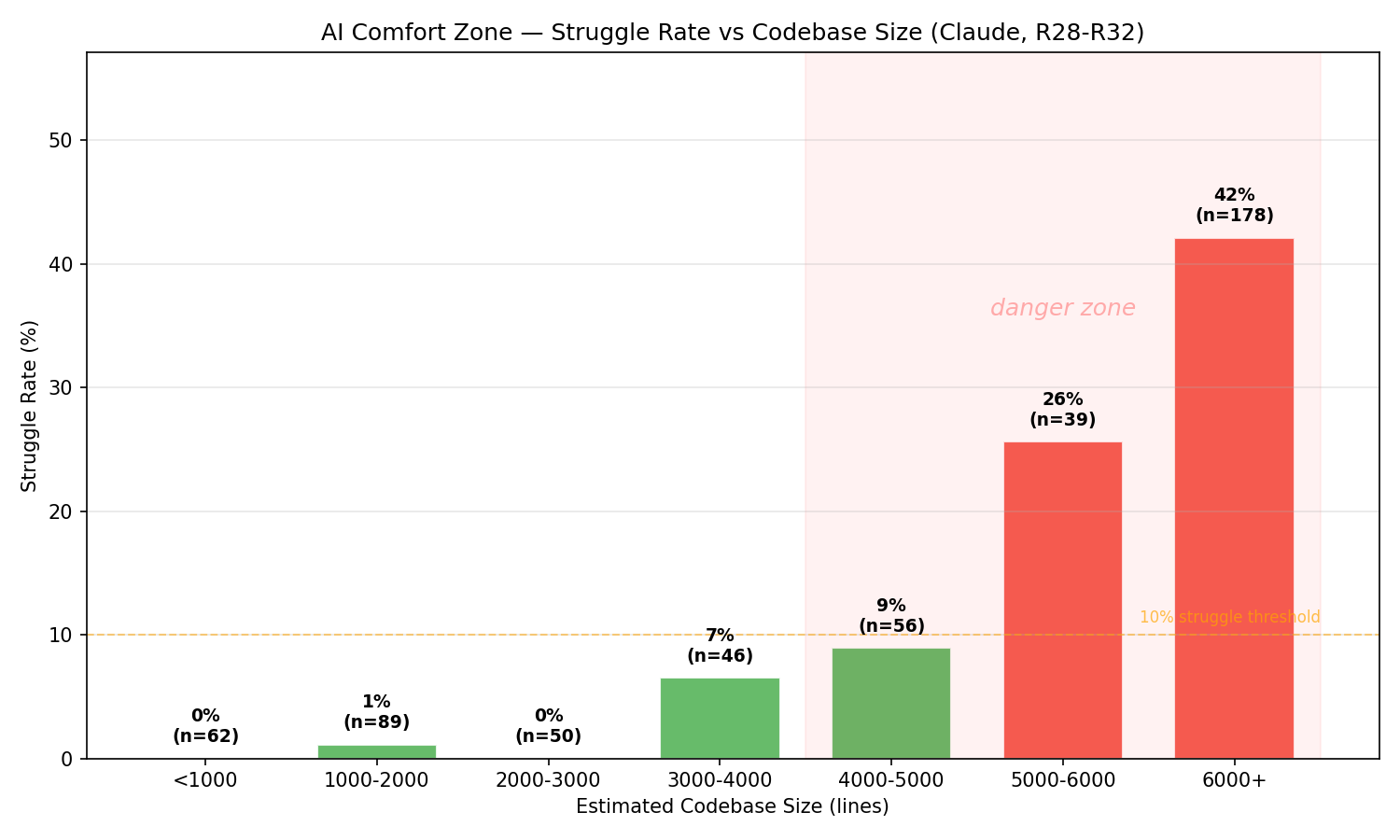


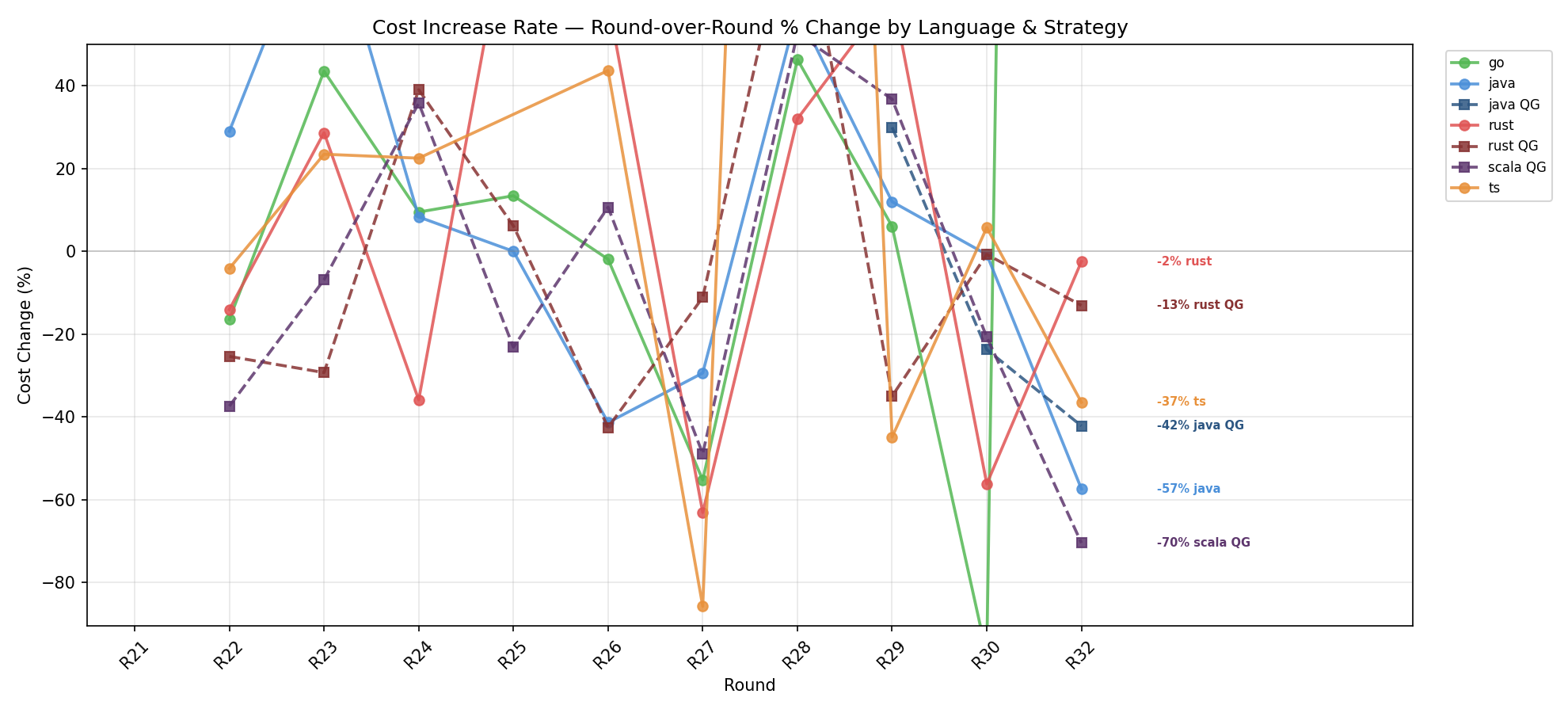
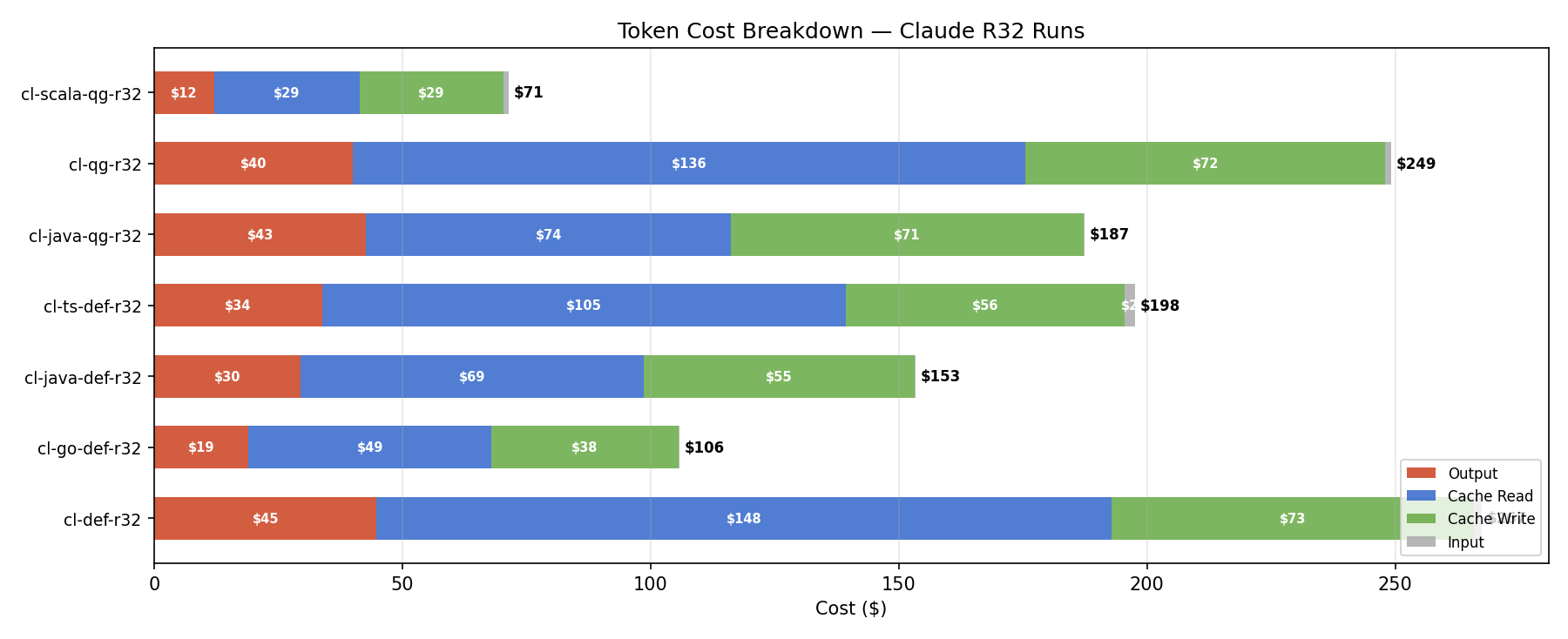

 --- # CLAUDE.md
--- # CLAUDE.md