Implementing Version Management of File Trees in PostgreSQL
Overview
In the previous
post, we discussed how to implement a file tree in PostgreSQL using
ltree. Now, let's talk about how to integrate version
control management for the file tree.
Version control is a process for managing changes made to a file tree over time. This allows for the tracking of its history and the ability to revert to previous versions, making it an essential tool for file management.
With version control, users have access to the most up-to-date version of a file, and changes are tracked and documented in a systematic manner. This ensures that there is a clear record of what has been done, making it much easier to manage files and their versions.
Terminologies and Context
One flawed implementation involves storing all file
metadata for every commit, including files that have not changed but are
recorded as NO_CHANGE. However, this approach has a
significant problem.
The problem with the simple and naive implementation of storing all
file metadata for every commit is that it leads to significant write
amplification, as even files that have not changed are recorded as
NO_CHANGE. One way to address this is to avoid storing
NO_CHANGE transformations when creating new versions, which
can significantly reduce the write amplification.
This is good for querying, but bad for writing. When we need to fetch
a specific version, the PostgreSQL engine only needs to scan the index
with the condition file.version = ?. This is a very cheap
cost in modern database systems. However, when a new version needs to be
created, the engine must write \(N\)
rows of records into the log table (where \(N\) is the number of current files). This
will cause a write peak in the database and is unacceptable.
In theory, all we need to do is write the changed file. If we can find a way to fetch an arbitrary version of the file tree in \(O(log(n))\) time, we can reduce unnecessary write amplification.
Non Functional Requirements
Scalability
Consider the worst-case scenario: a file tree with more than 1,000 files that is committed to more than 10,000 times. The scariest possibility is that every commit changes all files, causing a decrease in write performance compared to the efficient implementation. Storing more than 10 million rows in a single table can make it difficult to separate them into partitioned tables.
Suppose \(N\) is the number of files, and \(M\) is the number of commits. We need to ensure that the time complexity of fetching a snapshot of an arbitrary version is less than \(O(N\cdot log(M))\). This is theoretically possible.
Latency
In the worst case, the query can still respond in less than 100ms.
Architecture
Database Design
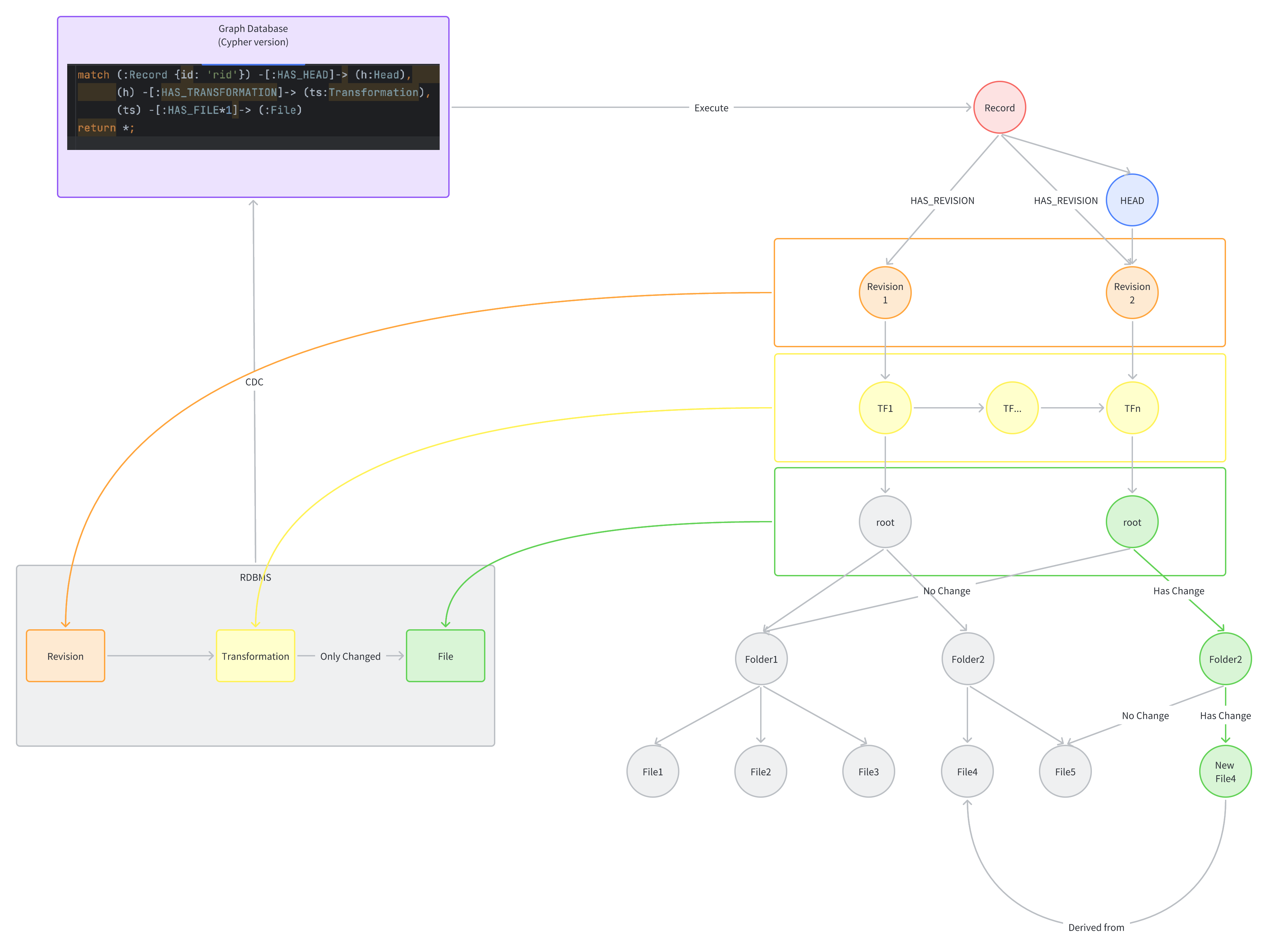
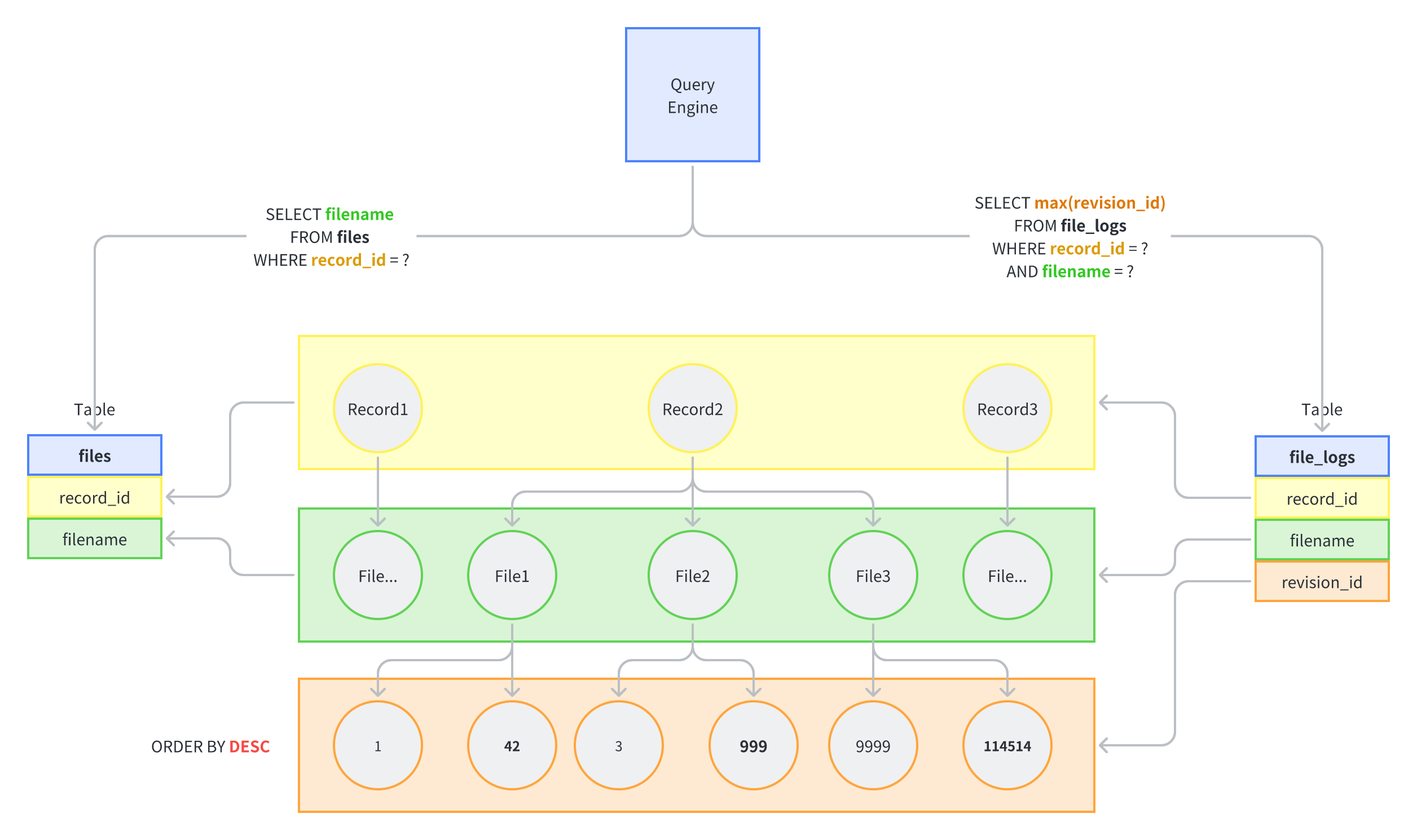
Illustration of data structures.
Tech Details
Subqueries appearing in
FROMcan be preceded by the key wordLATERAL. This allows them to reference columns provided by precedingFROMitems. (WithoutLATERAL, each subquery is evaluated independently and so cannot cross-reference any otherFROMitem.) — https://www.postgresql.org/docs/current/queries-table-expressions.html#QUERIES-LATERAL
PostgreSQL has a keyword called LATERAL. This keyword
can be used in a join table to enable the use of an outside table in a
WHERE condition. By doing so, we can directly tell the
query optimizer how to use the index. Since data in a combined index is
stored in an ordered tree, finding the maximum value or any arbitrarily
value has a time complexity of \(O(log(n))\).
Finally, we obtain a time complexity of \(O(N \cdot log(M))\).
Performance
Result: Fetching an arbitrary version will be done in tens of milliseconds.
1 | explain analyse |
1 | Nested Loop (cost=0.86..979.71 rows=1445 width=50) (actual time=0.040..18.297 rows=1445 loops=1) |
Test Datasets
This dataset simulates the worst-case scenario of a table with 14.6 million rows. Specifically, it contains 14.45 million rows representing a situation in which 1,400 files are changed 10,000 times.
1 | -- cnt: 14605858 |
Schema
1 | create table public.file_logs |
Further Improvements
We can implement this using an intuitive approach in a graph database.