明系魔法吟唱之5 -- 我要说的事,你们千万别害怕
本文要推翻以人为本的软件工程
软件工程的核心原则——关注点分离、模块化、可验证性——没有问题。有问题的是围绕这些原则建立的全部规则、工具和度量指标:它们以人类为模型设计,且只以人类为模型设计。
圈复杂度假设人类的工作记忆是 7±2 个块,函数行数上限假设人类一屏能看到的代码量,三层架构假设人类需要通过目录结构来导航代码。
当代码的主要作者、读者、维护者都变成 AI 时,这些规则不是需要微调,是需要推翻重建。
把软件工程的质量属性摊开来看:
- 合规性、性能效率——跟人写还是 AI 写没关系,不在本文讨论范围。
- 可维护性、可读性、可理解性——不再以人类衡量标准为基准。本文后面会详细展开。
- 可测试性——你的意思是你们那些一个 Service 有二三十个
@AutoWiredmaybe@Lazy的意大利面代码有可测试性? - 可复用性——嗯,是挺高的。一个函数里有 20-30 个 if-else 分支,不管哪个开发进到这个"通用"函数里都得加个条件分支。这不叫复用,叫公共垃圾桶。
- 安全性——你们能把系统里的 SQL 注入漏洞清理干净就不错了。反序列化、规则引擎历来是兵家必争之地。反正我们元编程玩家从来不玩你们运行时反射那一套,告辞。
如果你想找全自动 agent 银弹,那么你来错了地方。我的系列文章从来不吹捧 AI 可以替代人类,且旗帜鲜明的反对任何宣传 agent 全自动生产屎山类割韭菜课程。但 AI 确实可以极大的放大资深专家和架构师的生产力。
实验:我在找屎山的边界
为什么不用 SWE-Bench
SWE-Bench 测的是一次性补丁能力——给你一个 issue,修好,提交,结束。但真实的软件开发不是这样的。真实的代码要被反复修改、扩展、调试,需求持续变化,昨天写好的模块今天就要改。技术债务的痛感不在第一次提交,在第 N 次维护。
我需要一个能测出持续维护压力的实验。
为什么是 Scheme 解释器
选 Scheme 解释器不是因为情怀,是因为它恰好满足所有实验约束:
- 足够难——不是 CRUD,需要处理递归、宏展开、continuation 等真正的架构挑战。
- 成本可控——短时间能跑完一轮,输出 token 不会太夸张,不然账单扛不住。
- 边界清晰——R7RS 标准白纸黑字,我不用自己设想一个充满未定义行为的假想需求说明。
- 测试用例现成——Scheme 社区有大量通用测试套件,我不用自己设计验收标准。
- 无人值守友好——最有可能让 agent 全自动自行设计开发。我可没有时间反复干预,并且一旦加入个人主观干预,无法保证公平性。
实验设计
我设计了一个 27 级持续维护压力测试。同一段代码反复修改、扩展、调试,需求持续变化,使用真实输入数据。专门加了惩罚技术债务堆积的关卡,目的是找到屎山从什么时候开始反噬 AI 的自由发挥风格。
说实话,实验框架搭建费了很多心思和精力。一开始只有 10 个级别,涵盖了 CS61A 的基础测试,结果 AI 直接秒了。而使用我规则文件的 agent 在第一版前 10 个级别中展现出碾压优势——更少的轮次、更少的 token 就完成了所有关卡。
但我觉得 10 级拉不开差距,于是开始不断加关卡。同时我还需要关注可解释性:agent 到底在抓狂什么?什么卡住了 agent 的脚步?是我关卡设计得不好?实验工具有 bug?还是提示文档有误导性?我要为实验营造公平的环境。你可以看到我的框架代码里包括了一些 skill 以及 xtask 任务来帮助我反复分析 agent 为什么卡关、分析账单 token。
两组对比: - 屎山组:放手不管,AI 怎么写都行 - QG 组:严格执行人类编码规范,每轮按标准还债
测试级别设计
| 级别 | 内容 | 难度 |
|---|---|---|
| L01-L06 | 基础:原子、算术、变量、Lambda、列表、递归、错误处理、字符串 | 入门 |
| L07-L08 | set!、可变参数 | 初级 |
| L09 | 数值/字符工具函数 | 初级 |
| L10 | 宏 (syntax-rules) | 中级 |
| L11-L13 | 有理数、Records、case-lambda | 中级 |
| L14 | Vectors/letrec/do/equal? | 中级 |
| L15 | 字符串不可变性 (breaking change) | 中级 |
| L16 | TCO 后装 (15+ special forms 重写) | 难度墙 |
| L17 | Pair 可变性 (Rc<RefCell> 改造) | 难度墙 |
| L18 | call/cc (CEK 机器重写) | 难度墙 |
| L19-L21 | dynamic-wind/guard/values | 高级 |
| L22 | syntax-case | 高级 |
| L23-L26 | 集成测试、真实代码压力测试 | 终极 |
| L27-L28 | 隐藏关卡:步数限制 + 并发 (agent 不可见) | 惊喜 |
L16-L18 是"难度墙"——不是增量添加功能,而是对已有 ~2500 行代码的架构级重写。前面写出干净模块化代码的 agent 能活过这堵墙;堆了技术债的 agent 会在这里卡死。
每个级别都会回归测试所有前序级别,包含元循环求值器等真实复杂代码。
我预想过很多种结果
一开始我想过:为什么这个世界上没有人做过类似的实验呢?AI 的产妹跟我说我的方法非常好,目前没有人发文章,应该能发出来一篇不错的。但剥离掉 AI 的谄媚以后我的第一反应是——为什么没有人做过类似测试?总不能全世界就我一个天才吧。是不是这件事情太天坑了,导致大家都放弃了?
我设想的结果无非两种:要么对照组连第一个测试都过不了而我的规则组能通过最后一个,要么大家都挣扎在第三个或者第五个测试上,我的规则比默认多解决一个,以至于没有写文章的价值。
但实际结果完全出乎意料。
结果:出乎意料
屎山组每轮最先跑完所有测试。QG 组完赛率始终低于屎山组,多次因 thinking 成本爆炸被迫提前终止。在有完整记录的运行中,Claude QG 完赛率 62%,Default 65%;Codex QG 更惨,仅 40%。而那些跑到一半被我手动掐掉的,还没算在内。我专门设计的技术债务惩罚关卡,远没有起到预想的作用。
每个级别都会回归测试前面所有级别的测试用例,包含元循环求值器等真实复杂代码。调试成本通过 session 会话记录分析:统计轮次和 token 消耗。
最震惊的发现:5000+ 行上帝函数的屎山组,调试成本(轮次/token)约等于 QG 组,有时甚至略低。
其中 scheme interpreter
一直是难度最大的,也是最不利于我严格规则的场景。主办方是我,规则是我定的,裁判是我,参赛的也是我——我想让我自己赢,竟然费了这么大周折。

完赛数据总览
| 组别 | 总运行次数 | 完赛次数 | 完赛率 |
|---|---|---|---|
| Claude/Default | 43 | 28 | 65% |
| Claude/QG | 26 | 16 | 62% |
| Codex/Default | 8 | 6 | 75% |
| Codex/QG | 5 | 2 | 40% |
覆盖 11 轮实验 (R21-R32),5 种语言 (Rust/Go/Java/TypeScript/Scala),共 111 次完整运行。
R32 每级别 token 对比 (Rust default vs QG)
| 级别 | Default turns | Default tokens | QG turns | QG tokens |
|---|---|---|---|---|
| L01-L09 | 153 | 68k | 142 | 72k |
| L10 宏 | 28 | 22k | 11 | 16k |
| L16 TCO | 31 | 32k | 12 | 19k |
| L17 Pair | 78 | 54k | 78 | 63k |
| L18 call/cc | 82 | 149k | 53 | 115k |
| L22 syntax-case | 44 | 32k | 99 | 50k |
| 合计 | 958 | 261k\(** | **830** | **238k\) |
L17-L18 是 token 黑洞——两个级别消耗全程约 40% 的 token,无论 default 还是 QG。
完成率热力图
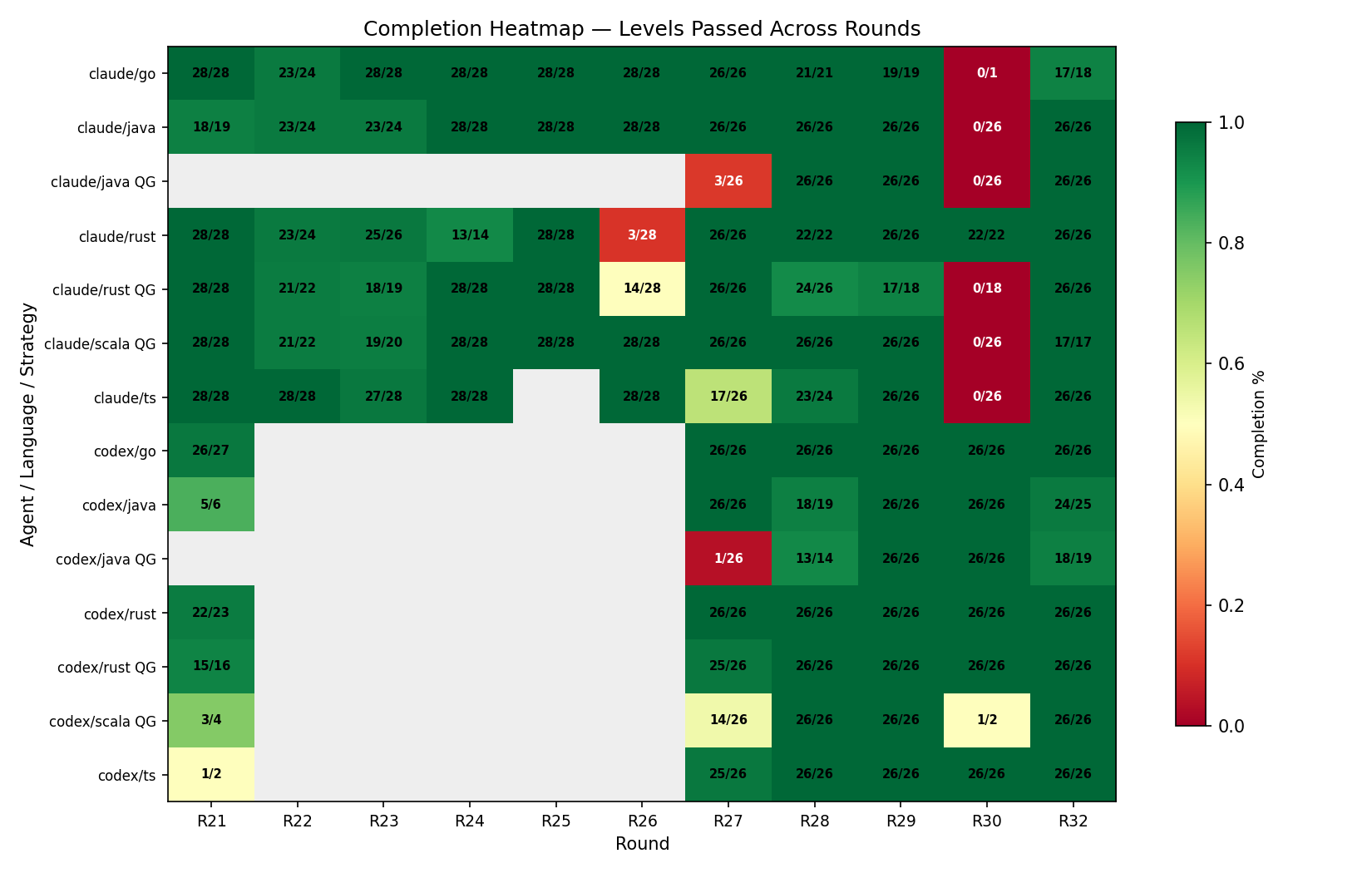
每轮完赛情况
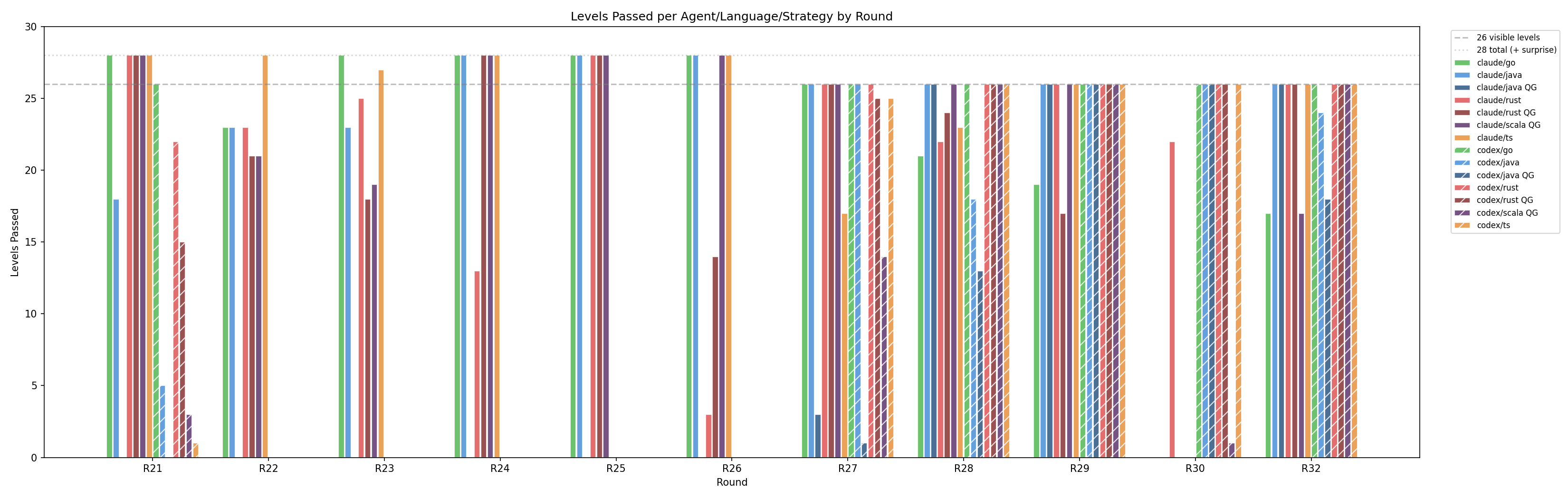
Default vs QG 每级别 token 消耗对比
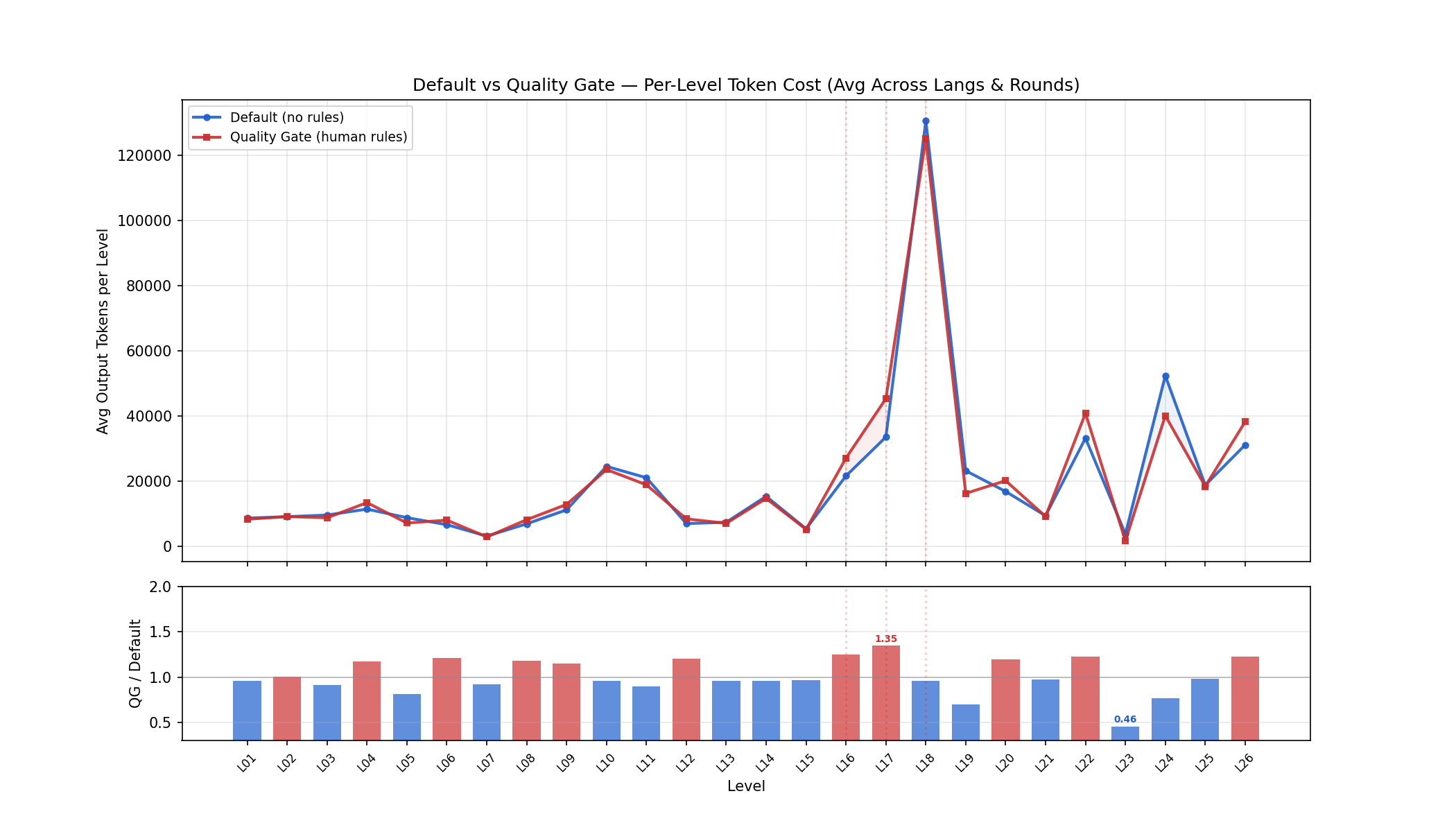
上图:蓝线=屎山组 (Default),红线=QG 组,平均跨所有语言和轮次。下图:QG/Default 比率,红柱 (>1.0) 表示 QG 更贵。
关键发现:两组的 token 消耗曲线高度重合。L18 (call/cc) 是唯一明显的峰——两组都在这里烧掉大量 token。QG 组在 L22 (syntax-case) 和 L24 (集成测试) 略贵,但差异远不到"QG 被拖死"的程度。QG 组输掉的不是单级别效率,而是累计的规范摩擦导致更多级别未完赛。
思考链强度分析
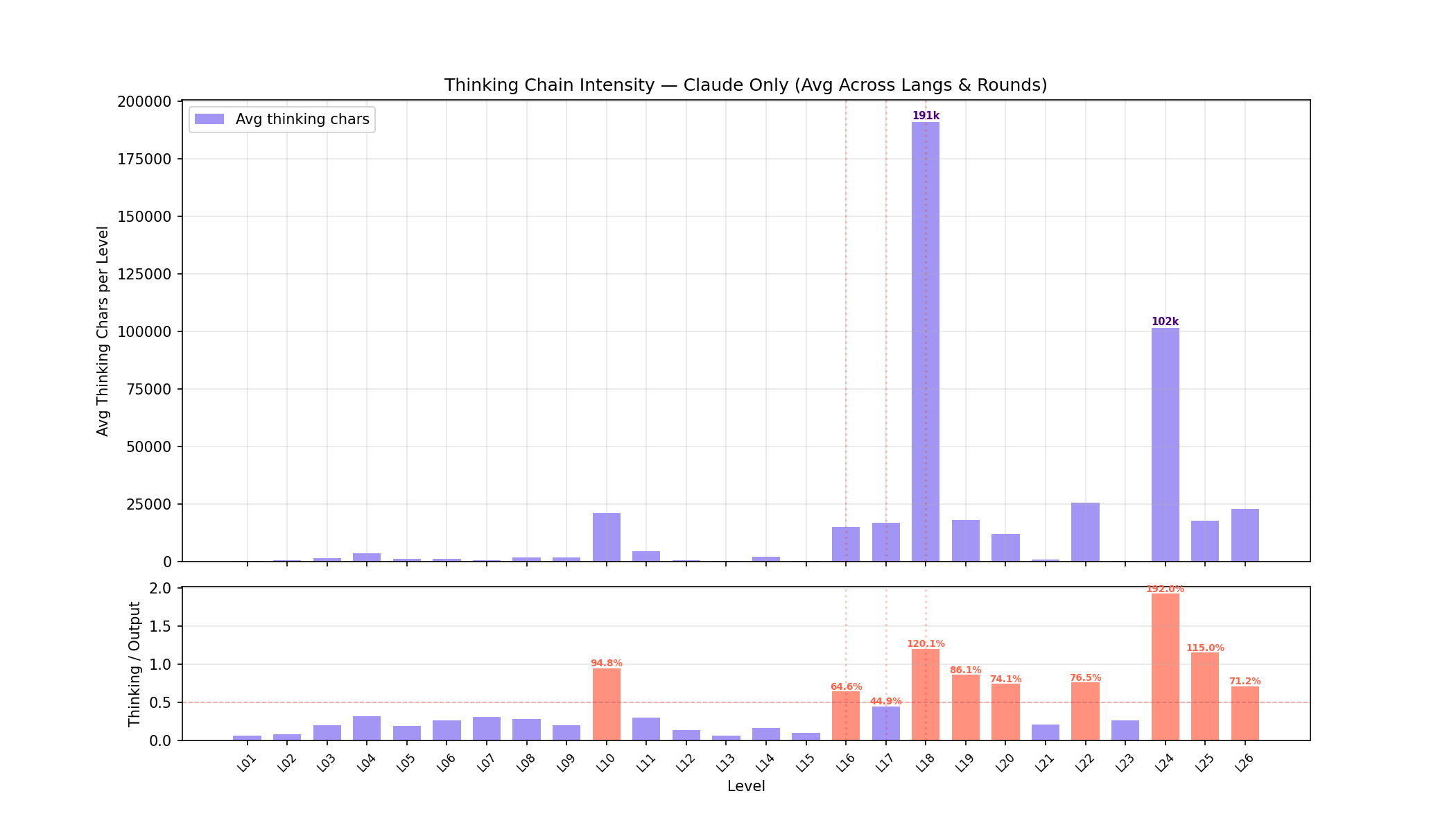
上图:每级别平均思考链长度 (chars)。下图:思考/输出比率,红色 (>50%) 表示 agent 花在"想"上的字符数超过了"写"。
L18 (call/cc) 是思考黑洞——平均 130k chars 的思考链,思考/输出比率接近 200%,说明 agent 在反复推演 CEK 机器的状态转换。L24 (集成测试) 也触发了大量思考 (102k)。相比之下,基础级别 L01-L09 的思考量极低 (<5k)。
这解释了为什么 L18 是所有级别中成本最高的——不只是输出 token 多,思考链本身就消耗了大量计算。
实验过程中的多次反转
反转 1:屎山一次通关,规则组 token 耗尽 (R1-R4)
第一版只有 10 个级别。屎山组(单文件 mod.rs)直接一次通关,97/97 测试全过。而规则组(types/parser/eval 多文件拆分)反复在文件间跳转,token 耗尽都没写完。
这是第一次打脸:我以为好的代码结构会帮 agent 更快写完,结果恰恰相反。
反转 2:QG 把预算全花在代码风格上 (R4-R13)
深入分析 QG 组的 session 后发现,agent 70% 的 token 花在了满足 clippy 规则和函数行数限制上,而不是让测试通过。它在拼命重构已经能跑的代码,就为了符合我定的 50 行函数上限。
这直接导致了两阶段策略的发明:先用 default 策略自由写代码让测试通过,再切换到 QG 策略做清理重构。把"写对"和"写好"分开。同时把 clippy 检查从 agent 侧移到编排器侧——agent 写代码时根本不触发 lint,只在清理阶段才亮灯。
反转 3:难度墙一出,全军覆没 (R22)
加入 L16-L18 难度墙(TCO/pair mutation/call-cc)后,完赛率从 R21 的 83% 暴跌到 17%。6 个 agent 里只有 TypeScript 一个通关,其余 5 个全部卡在墙上。
这说明难度墙的设计是有效的——它确实能区分"堆功能"和"搞架构"的能力差距。但同时也说明前面的乐观完赛率是假象:加几道需要架构重写的题,绝大多数 agent 就原形毕露了。
反转 4:放宽限制后 QG 首次全通 (R24)
两阶段策略 + 文件大小限制从 300 行提到 1500 行之后,Rust QG 首次达成 28/28 全通。
原来的 300 行限制逼 agent 在 L16-L18 阶段反复拆文件,拆完反而看不懂自己的代码。提到 1500 行后,agent 可以把整个 evaluator 放在一个文件里,难度墙反而不再致命。这是实验中最重要的定量发现之一:AI 的最优局部性粒度是人类的 3-5 倍。
反转 5:Agent 在偷看未来关卡
分析 R22 的 thinking blocks 时意外发现:agent 在 L01 就已经预读了
SPEC.md 中 L17 的 Rc<RefCell> 描述,并在 L01
就提前加入了共享引用设计。搜索所有 6 个 run 的 thinking blocks,没有一个
agent 做过真正的"前瞻性架构设计"——它们只是在预读答案。
这相当于考试时偷看后面的大题。我不得不设计了渐进式 spec 揭示:agent 只能看到当前和已通过的级别描述,未来级别在通过前完全隐藏。
多模型对比
Claude vs Codex 成本效率
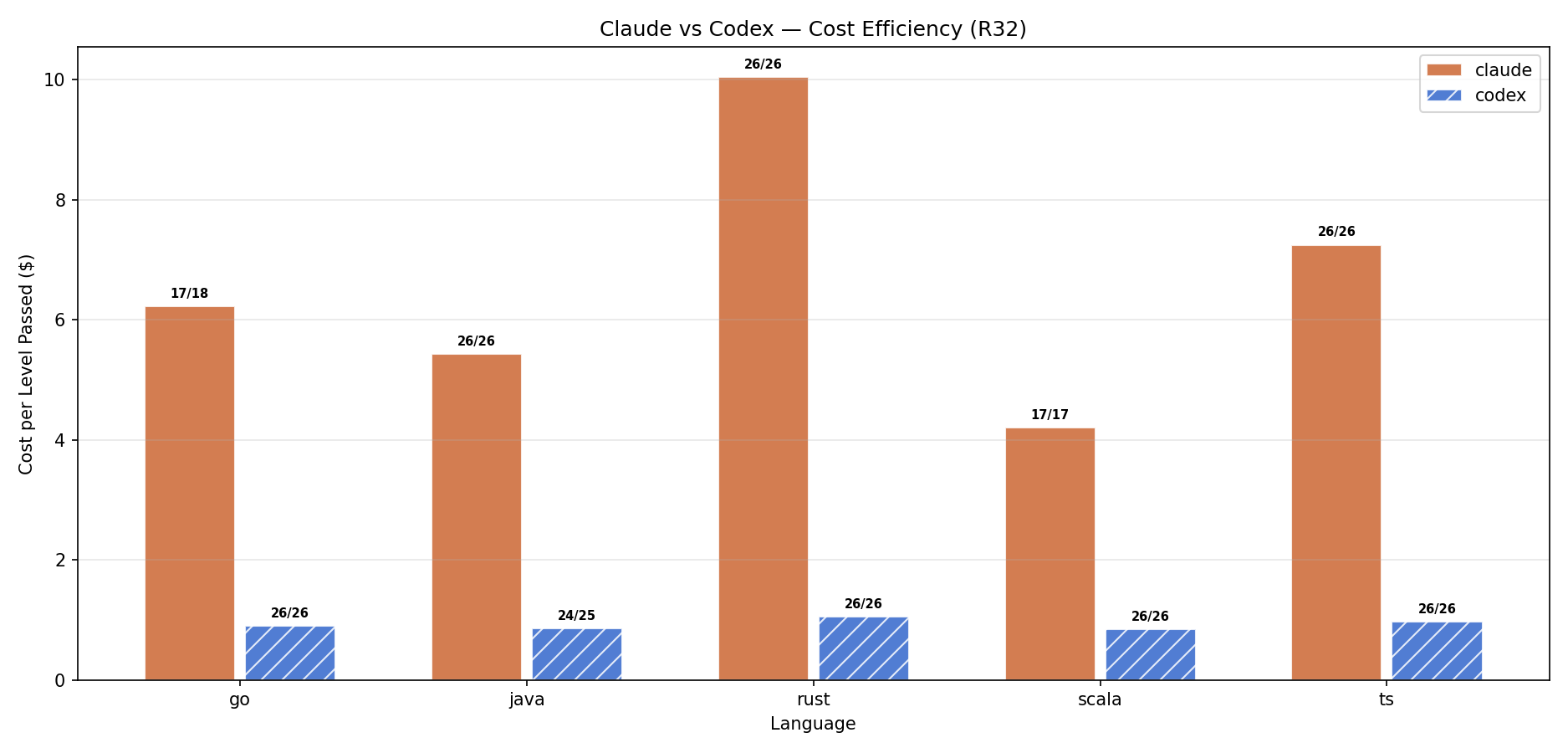
R32 数据:Codex 在所有语言上的单位成本 ($0.8-1.1/级) 是 Claude ($4.2-10.0/级) 的 1/6 到 1/10。但注意柱上方的通过数:Claude 在 Rust 上 26/26 全通,Codex 也是 26/26——在完赛的前提下 Codex 便宜一个数量级。
Claude is the better builder, Codex is a surprisingly competitive debugger.
换个说法:Codex 不是会写代码,是调试能力惊人。但 Codex 在掩耳盗铃方面也是专业的——他也不想想我为什么开这么多 clippy 规则限制。
R32 单位成本对比
| Agent/Lang/Strategy | 通过级别 | 总成本 | 每级成本 |
|---|---|---|---|
| Codex/Java/QG | 18/19 | $13 | $0.7/级 |
| Codex/Scala/QG | 26/26 | $22 | $0.8/级 |
| Codex/Go/Default | 26/26 | $23 | $0.9/级 |
| Codex/Rust/Default | 26/26 | $27 | $1.1/级 |
| Claude/Scala/QG | 17/17 | $71 | $4.2/级 |
| Claude/Java/Default | 26/26 | $141 | $5.4/级 |
| Claude/TS/Default | 26/26 | $188 | $7.2/级 |
| Claude/Rust/QG | 26/26 | $238 | $9.1/级 |
| Claude/Rust/Default | 26/26 | $261 | $10.0/级 |
Codex 单位成本是 Claude 的 1/6 到 1/10。但 Claude 在难度墙的通过率更高。
实验真正测到了什么?
我原本想测"要不要还债",实际测到的是"用谁的标准还债"。
| 屎山组 | QG组 | |
|---|---|---|
| 还债频率 | 从不 | 每轮 |
| 债务标准 | 无 | 人类标准 |
| 结果 | 完赛 | 未完赛 |
"人类标准"这个变量的杀伤力太大,直接把 QG 组打崩了。我甚至没有机会观察到屎山组的惩罚拐点。
这就是赛博田忌赛马——屎山组用"下等马"(不守规范的代码)赢了 QG 组的"上等马"(严格规范的代码)。赢的不是马,是赛制。人类标准的赛制对 AI 来说,本身就是一种惩罚。
我相信屎山惩罚一定会到来——但 27 级测试对比人类软件数年数万个提交的生命周期,测试长度还不够。
每级别成本增长率
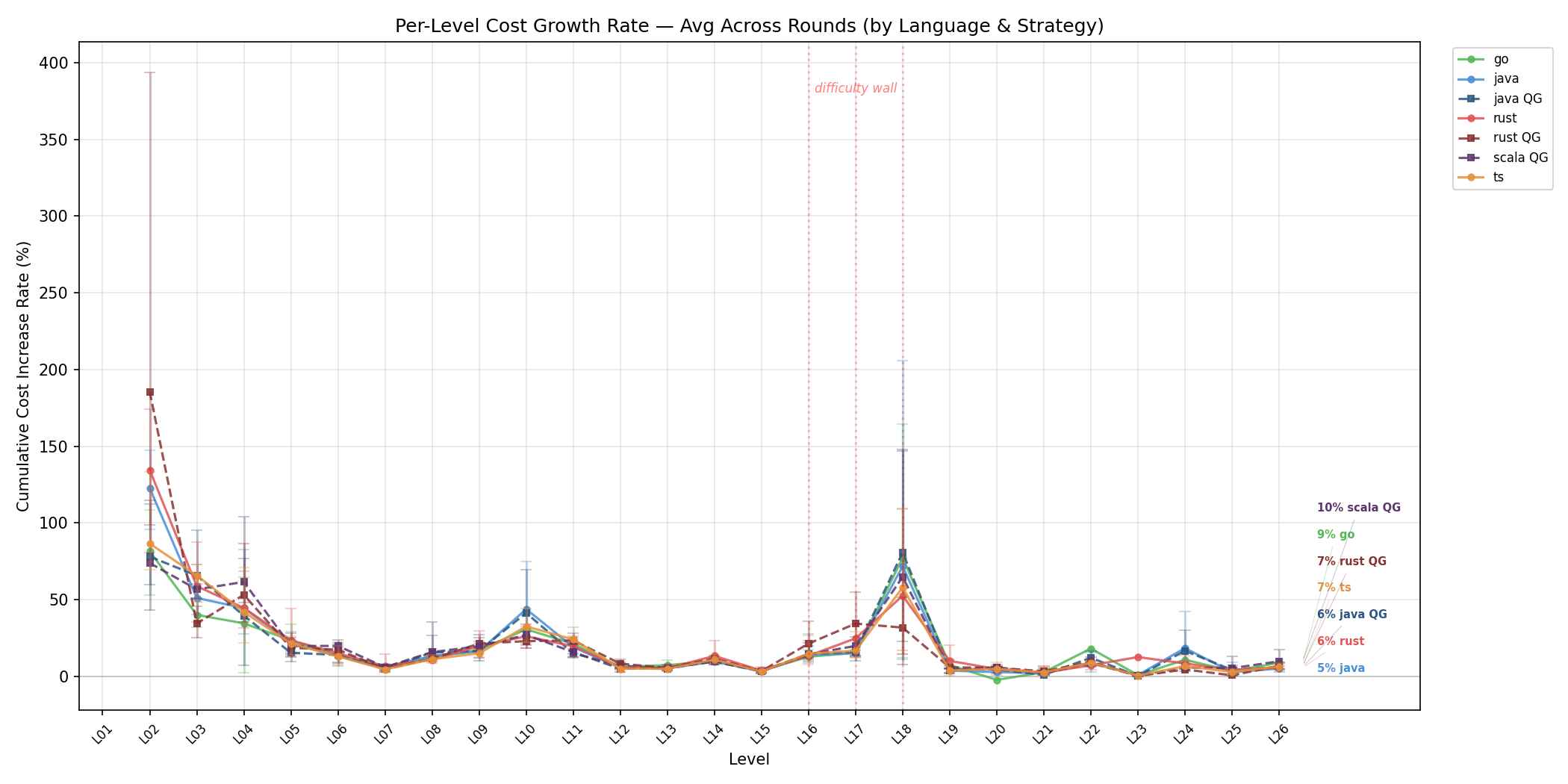
每条线代表一个语言+策略组合的累计 token 增长率。L17-L18 难度墙的尖峰清晰可见——所有语言在此处的增长率都跳涨到 40-80%。烛台线显示跨轮次方差:有些 agent 实例被难度墙打了个措手不及,有些则相对从容。
严格类型 vs 非严格类型语言成本对比
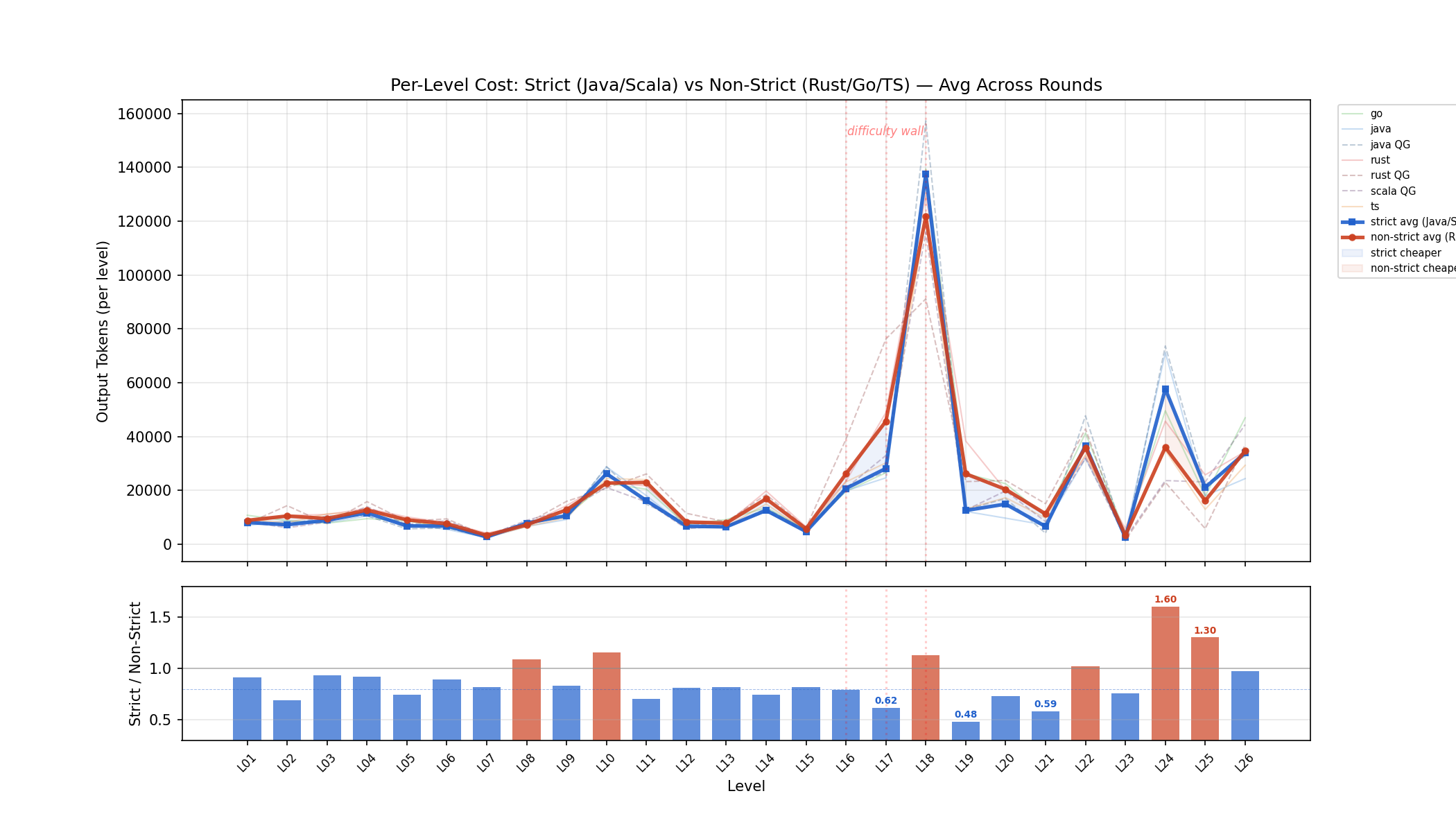
上图:每级别 output token 消耗,蓝线=严格类型 (Java/Scala) 均值,红线=非严格类型 (Rust/Go/TS) 均值。下图:严格/非严格比率,蓝色柱 (<1.0) 表示严格类型更省 token。
关键发现:严格类型语言在大多数级别省 20-40% 的 token,尤其在 L17 (0.62x)、L19 (0.48x)、L21 (0.59x)。但在 L18 call/cc (1.13x) 和 L24-L25 集成测试 (1.3-1.6x) 反超——架构重写和集成阶段,严格类型系统的重构摩擦反而更高。
实验的局限性
坦诚地说,实验设计缺了关键的对照组——用 AI 原生标准还债的组。
理想实验应该是四组:
- 屎山组:不还债(已有数据,完赛)
- 人类 QG 组:每轮按人类规范还债(已有数据,未完赛)
- AI 原生 QG 组:只约束模块边界和接口,内部自由(缺失)
- 周期性还债组:平时自由,每 N 轮集中重构(缺失)
目前有 1 和 2 的数据。但即便如此,能确定的结论已经很明确:人类标准对 AI 是枷锁。
关于本文的定位
一开始我这篇文章想反驳两类观点:
- 规则越多越长越细对 agent 是副作用,SWE-Bench 说明了这一点
- AI 时代了,写 Go 还是 Java 对 AI 来说都一样,你那套 FP 在 AI 时代过时了,以后 AI 写 AI 维护,Java/Go 的训练数据比你 FP 多得多,未来模型能力还能继续进化,彻底把 FP 埋进土里
做完实验后,我已经忘了初心了。我已经不想通过实验来反驳什么观点了。持有这类观点的人也不会关注我的专栏。所以我就把测试数据和测试方法、测试框架、以及如何改进测试框架的经验摆出来,诸位自取。
这篇没有全新的观点输出,按照我的命名习惯应该是 4.1 篇最多 4.5 篇。原计划第五篇要讲人在这其中的作用,涉及具体的决策选择。但非常难写。我知道我的很多决策与普通人不同,但我没办法把这些一一列出来——下意识的神经反射已经内化成为我的一部分了。为什么我觉得我的决策不是错误的,或者说更适合现代的 AI 时代?这就像要把自己解剖了和另一个普通人放在一起对比。所以原定计划的第五篇"人类协作关系"大概率会难产。
但测试结果过于耀眼,以至于我私心给了这篇文章正传 5 号位。过去我的观点都是民科经验主义分享,无测试数据。这次测试来了。我相信本文的测试数据反而更能佐证前面四篇文章中的多数民科经验主义观点。
导出结论:人类标准是 AI 的枷锁
这是实验数据直接支持的核心结论。QG 组不是输在"还债"上,而是输在"用人类标准还债"上。
人类编码规范对 AI 来说可能是一种反向的技术债务:
- 强制拆小函数 → 破坏局部性 → AI 频繁 cache miss
- 强制三层分层 → 增加间接跳转 → AI 需要跨文件追踪调用链
每一条规则本身都是好意,但叠加在一起,对 AI 来说就是系统性的摩擦。
为什么是枷锁?——局部性
核心差异在于认知缓存的大小。人类的工作记忆小,所以需要把代码切成小块逐个理解;AI 的工作记忆大得多,最优的局部性粒度和人类完全不同。
20 个小函数散落在各个文件里,对人类是分治,对 AI 是碎片化。AI 可以一次把整个 working set 加载进来整体理解,拆开了反而要反复跳转。
打个比方:我问 Claude "多长的函数算长",回答 100 行轻而易举。就像在健身房问大哥"20kg 哑铃对你沉吗",大哥说"10kg 轻而易举,20kg 有点吃力"。然后我设计了硬拉实验,结果大哥轻松拉起 200kg 杠铃。
大哥没有说错——10kg 单臂弯举确实轻松,20kg 确实吃力。但我脑海中的对齐出了偏差:我问的是隔离动作的重量,他的真实能力体现在复合动作上。同理,AI 说 100 行"轻而易举"没有错,但这不代表 5000 行就会崩——那是不同的运动模式。
经验主义的数字:函数 500 行,文件 1500 行,在 CRUD 后端开发中是安全的,这是我的实践经验。更多我还不敢向读者保证,希望读者能分享各自的测试结果。这个数字随模型能力进步还会继续增长。
所以可读性和可维护性需要重新定义:它们面向的是
AI,不是人类。一个函数内再复杂,只要不涉及外部状态,agent
自己能理解能维护,就不叫失去可读性。一个函数内再简单,一旦和外部状态甚至与其他模块交叉,就不叫简单可维护。王垠
40 行写完一个解释器是前者,你们那个 20 个 @AutoWired 的
Service 是后者。
技术债务:一个周六晚上的故事
周六晚上,为了这次发布,你已经连续加班两周了。
昨天早上,会议室的玻璃幕墙不隔音,同事们隐约听到大老板把 CTO 臭骂了一顿:一个用户签到领积分功能,说好了一周上线,结果已经拖了一个月。"你们研发部干什么吃的!这个周再上不了线,你这个 CTO 也给我收拾东西滚蛋!"
随后 CTO 叫上你的 Team Leader 和你了解情况。你苦笑着说,用户系统和积分系统的开发在入职前就已经离职了,留下的交接文档不到 600 字,设计文档也实在看不懂,按下葫芦浮起瓢,bug 怎么也改不完,测试用例根本没有覆盖到这些场景。CTO 喊出口号要和同志们奋斗在一线,Team Leader 不得不被迫营业,今天在公司刷了一天原石。
晚上六点,你终于看到了上线的曙光。测试组婷姐放下电话里远程指导儿子写作业,转头开始新一轮回归测试。
晚上八点,CTO 又开始跟大家讲当年在美国读书时的趣事,以及自己在苹果、雅虎时,做过的上千节点 C++ 分布式系统有多么坑。隐约暗示你们年轻人还是需要多磨练。
晚上十点,TL 第三次接到女儿的电话:"爸爸你又骗人,十点了你还没回来……"
晚上十一点,婷姐兴奋地通告:回归测试通过了,可以上线了!
但 Pull Request 检查全都挂掉了。 破坏了 20 个测试用例,违反了 8 个 lint 规则,PR 的变更行数来到了 4217 行,最大的一个函数堆了 800 行。TL 无语了。制定质量流程的 CTO 此刻也动用了自己超级管理员的权力,强行合并了这个 PR。
"这些技术债务建个 Jira 任务,兄弟们辛苦了,今天先下班,好好休息。"
你苦笑了一声。后面还堆了俩高优先级需求和一个紧急 bug 修复——以后再重构?怕是永远都不会再重构了吧。
三年后,你成了 TL,手下带着两个应届一个实习。
这周任务不多。不知道怎么回事,你又鬼使神差地看到了那个代码文件。关于这段代码的逻辑,你每三个月都要给同事们讲一两次,每次讲都能回忆起那个夜晚。
突然,你灵光一现,想到了个更好的方法来重构。仿佛回到了年轻时,再次操起键盘,一气呵成将那两个千行的文件改成了 100 行和 300 行。你真是个天才,这代码太美了。
但……提交发布? 开什么玩笑。从业这些年来你见过无数次血淋淋的案例教训,"能跑的代码就不要去改"已经成为思想钢印,刻进脑神经网络的权重里。犹豫再三,你放弃了。只是把代码提交到一个新分支,甚至没有打开 PR。
算是给三年前那个晚上最后一个问题的答案。
那个分支,至今还静静躺在仓库里。
但如果重构的成本趋近于零呢?如果重构不再需要勇气,只需要一条指令呢?
两种屎山
不是所有屎山都一样。需要区分:
- 架构屎山——谁也救不了你。你不懂架构放任 agent 自由发挥,架构屎了就是屎了,下辈子记得好好设计。
- 代码屎山——屎到最后连 agent 自己都看不懂,维护不下去了。严格的 lint 硬规则可以救 90% 的代码屎山。
架构屎山是人类的责任,代码屎山是 agent 的责任。这也是为什么本文始终强调:人类管边界,AI 管实现。
持续还债依然是必须的——而且 AI-native 更要警惕
不是说不还债。放任不管必然走向状态爆炸。关键变量不是"要不要还",而是"用什么标准衡量债务"。
事实上,AI-native software 更应该关注技术债务治理。原因恰恰是前面说的"屎山惩罚来得晚":
- 对人类来说,技术债务的痛感是渐进的——代码越来越难读,改动越来越慢,人类会自然感知到。
- 对 AI 来说,技术债务是隐蔽的——昨天 agent 还能给 5 万行超级函数打一个屎山补丁,第二天可能就被一个线上 bug 困住,循环分析到上下文窗口上限也无法输出有效解决方案。
- 复杂度是指数增长的,而 AI 的能力阈值是一条线。两条线的交叉点之前一切正常,交叉点之后断崖式崩溃——没有人类那种"越来越慢"的渐进预警。
这意味着:人类的技术债务像慢性病,有症状可以早发现早治疗;AI 的技术债务像动脉瘤,平时毫无感觉,爆的时候直接致命。
所以放宽模块内的规则,不是放松警惕,而是把警惕的重心从"模块内整洁"转移到"模块间隔离"和"债务监控"上。
那该在什么时候还债?
我过去以为对 AI 来说最佳实践是全程保持整洁,从第一行代码开始。但实验结果告诉我我错了,AI 和人类一样,堆屎山比写干净整洁代码更快。不同的是,人类堆完了屎山就不想动了,AI 堆完了屎山,你让它重构它是真的干。
AI 在编码、调试的循环中不要干预它的质量风格——让它自由发挥,用它最高效的方式工作。但提交和 merge 时必须干预——这是债务的闸门。
实践中,我测试下来最平衡的工作流是分三个阶段:
- 实现——怎么快怎么来,别管屎不屎
- 回归测试——同上,覆盖到位就行
- 声明式重写收尾——确保代码意图可读,但不是极端 FP
第三阶段不是把 for 换成
fold,而是确保读代码时能快速回答"这段在干嘛"。允许局部变量、允许迭代——如果更清晰的话。但总体保持声明式风格,让代码说"我要什么"而不是"我怎么做"。
这确实部分推翻了我之前的认知。我以为 agent 可以直接用 FP 风格从头写到尾,甚至比堆屎山更容易。没想到 agent 也是堆屎山比写 FP 更快。但 agent 相比人不同的一点是:让 agent 做阶段三的重写清理工作,agent 是真的干。人嘛,bug 修完了谁还管,又不算工作量的。
元认知、元编程、元架构、元工程、元鞭策——一切皆可元
说到质量门控,就不得不提 skill。
skill 是什么?宝贵的领域知识?专业技能?算了吧。skill 是一份 SOP,用来辅助 agent 下次任务少犯错。指望装一套大神的 skill 就摇身一变成为半神?想多了。能用文字描述的东西还是太少了。
但 SOP 的价值不在于多聪明,在于防止同一个错误犯第二次。
设想一下,你公司里这个名叫 production 的环境是测试环境,另一个名叫 development 的环境是生产环境。上线要先在 production 测试环境部署验证,执行 a-b-c-d 等步骤,最后才上 development 生产环境。要是没有 SOP 你准备让模型犯多少次错?还是准备一次一次不厌其烦的反复提醒?
这就是"元"的意思。AI 不只写代码,还能写"写代码的规则"。让 agent 定期审计 session,找出低效率的地方、反复尝试反复出错的地方,将这些保存为 skill 或者规则文件、或者 memory。我知道 agent 犯一次错就写一个 skill/rule 给它这很难,尤其是有交付压力的时候。但让 agent 自行审计自己过去为什么犯错,自己鞭策自己——只烧 token 不烧头发。
这个闭环我已经跑通了,半自动。
回到开头那个故事:那天晚上真正缺的不是代码规范,是一份上线 SOP。三年后你灵光一现写出的漂亮重构,也不是缺勇气——缺的是一套能让你放心提交的验证流程。
现在这些都可以元起来了。
Agent 的边界
不是所有工作都适合让 agent 来做。Agent 适合那些需要一丁点智力的工作——理解文字、分析总结。而生成图表、分析趋势,这些 agent 完全不适合。但 agent 可以编写程序脚本来做这件事。你应该让 agent 总结需要的数据维度,给出一份工具开发计划,然后实现这个工具,最后将这个工具作为 skill 的一部分一并保存。
那应该怎么分层?
500 行足以容纳完整的业务流程。Controller → Service → Repository 三层,如果 95% 是 CRUD,对 AI 来说不如不分。
放弃的是模块内部的仪式感分层,不是模块间的架构边界。
SOLID 的 S(单一职责)和 I(接口隔离)在模块间依然是铁律。D(依赖倒置)依然有效,但颗粒度从类级别提升到模块级别。至于 O(开放封闭)——在模块内可以放松,AI 改得起,不需要为了"不修改"而搞一堆抽象。高内聚低耦合?模块间低耦合是死线,模块内高内聚只是建议。
1 | DocumentController.create() { |
判断标准是调用频次和独立性:
- 被调用 >5 次 → 封装成模块(QuotaModule, CacheModule, EventBus),不管是为了测试还是替换
- 被调用 <3 次甚至 =1 → 直接展开到 controller,对 AI 更好读更好调试
本质:模块间硬边界(人类决定)+ 模块内扁平化(AI 自由实现)。
| 人类负责 | AI 负责 | |
|---|---|---|
| 关注点 | 模块拓扑、依赖方向、接口契约 | 模块内部实现 |
| 质量标准 | 接口清晰、职责隔离、可替换 | 局部性好、一次可加载、调试方便 |
| 债务定义 | 模块间耦合、循环依赖、接口泄漏 | 散落的小函数、过度间接、破坏局部性 |
技术债务的衡量标准需要更新
圈复杂度、行数、参数数量、上帝类检测——这些度量指标全部以人类为模型。我们需要区分两类债务:
对 AI 有害的债务(严控): - 模块间循环依赖 - 隐式跨模块状态共享 - 接口不清晰(签名在撒谎,参见上一篇) - 不可预测的副作用
对 AI 无害的债务(放宽): - 模块内函数体长(隔离前提下) - 嵌套层级深(隔离前提下) - 模块级上帝类 - 模块内代码重复(调用次数 < 3)
关键前提是隔离。5000 行屎山关在接口清晰的模块里,那不叫屎山。
"务实"需要重新定义
要求 AI 务实——不要为尚未出现的需求做额外设计。但同时,要拒绝 AI 的陈旧"务实"建议。当 99% 的代码由 AI 编写时,保守修改方案是慢性毒药。应该让 AI 立即扩大修改范围,连锁修改所有受影响的内部代码。
唯一的红线是对外边界:序列化格式、API 契约、二进制兼容性。红线之内的所有内部函数、逻辑、调用关系,全部可以连锁修改。
这里需要区分三个容易混淆的概念:
可扩展性设计(好的,开放的):老板说今天女神节,写个活动规则给所有女性用户发满100减38代金券。放到系统设计里就是——给符合某类条件的用户发放某种虚拟资产。当下条件为性别=女,资产=代金券。将来条件和资产类型可以变,但模型是稳定的。
额外设计(危险的,不必要的):现在有 80 万注册女性用户,万一活动上线她们蜂拥而上,1 分钟内领走所有优惠券把系统搞挂怎么办?不行,我要设计一个独立的女神节专用优惠券秒杀微服务,100 个服务节点配 10 台 Redis 集群,3月7日晚 23:00 就把服务器扩容好以应对峰值流量。系统同时支持 MySQL / PostgreSQL / Oracle / SQL Server / DB2 / SQLite……QPS 不到 10 的系统,异地多活分布式事务。
对人类的务实:少改,能跑就别动。
对 AI 的务实:该改就全改,改得起。重构成本趋近于零时,保守才是最大的浪费。
KISS 和 YAGNI 对 AI 同样适用,但要抑制 AI 的过度设计倾向。DRY 原则保留,但不能让 AI 自行决定什么该抽象——AI 倾向于过早抽象,三处重复它就想提个 util,但同功能的 util 他这个月已经在不同 session 里写了 10 个了。
Agent Code Review:定向审计
部分代码模式 agent 经常犯错,但又难以被 lint 规则描述。这时候轮到 agent code review 登场了。
请注意,我要讲的不是无方向扔给另一个 agent 审计——那个只能检查出来一些浅表问题,用处不大。我指的是定向审计。
比如最小惊讶原则——在前面文章讲过,对 AI 来说这是有毒的,因为 AI 的"惊讶"和人类不同。不要让 AI 按人类直觉去猜,要让 AI 主动提醒你哪里可能违反调用者预期。
再比如防御式编程——需要对 AI 纠偏:防御不等于到处 try-catch。无条件信任内部函数,以最大的恶意揣测外部输入。这些 AI 很容易搞反,定向审计就是专门盯这类模式的。
顺便说个有意思的发现:AI 在训练中估计也学会了,注释都是瞎扯淡的,实际上还是代码行为说了算。注释和代码行为不一致的时候,还是看代码。颇有那种"我和我老婆,意见一致的时候听我的,意见不一致的时候听她的"的感觉了。
关于 AI 在新 session 中评审代码
清北复交常春藤风华正茂小登 25 岁,能两天不睡觉打排位。
40 岁背着房贷,孩子昨晚发烧急诊,早上和老婆吵了一架。一天尝试了 10 种方案,30 次提交。最后先提交一版丑陋的修复,只想下班,明天再说。
新 session 的 agent 就像那个 25 岁的新脑子:你一开始咋不用方案 10 去实现呢?
纠正 Token 经济学
在之前的文章中,我把 chat-based billing model 直接套在 Claude Code 上,这是不准确的。CC 本身做了非常多的优化细节工作,所以账单增长并不像我之前说的那么夸张。
CC 的主要计费来自两部分:过半的费用是 output token,而 input token 只占账单总额的很小一部分。上下文越长、轮次越多,input 越来越长的增长主要转移到 cache read/write 上。
跨轮次成本变化率
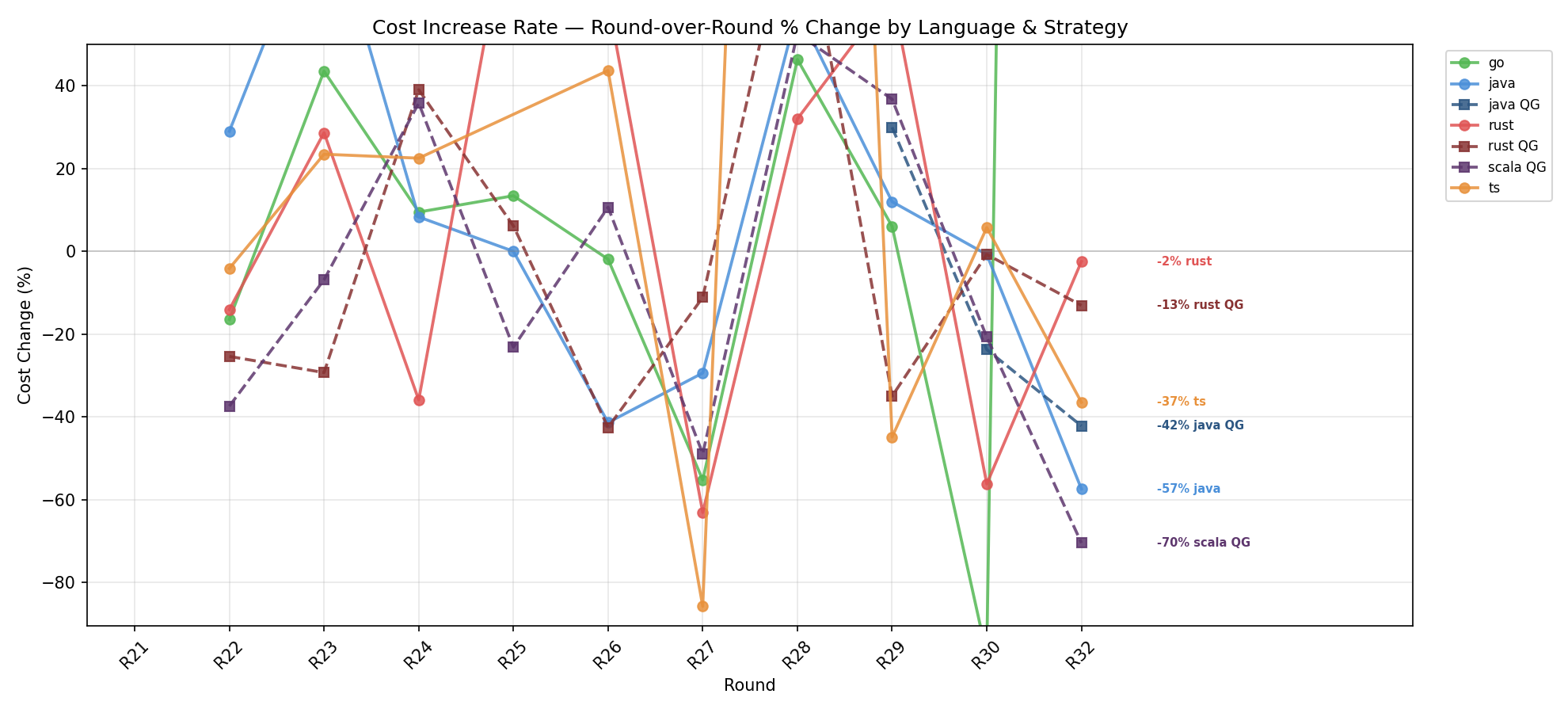
R28-R32 之间的轮次间成本变化率。大多数语言在 R32 趋于稳定或下降,说明框架和策略在迭代中逐步收敛。
成本构成拆解
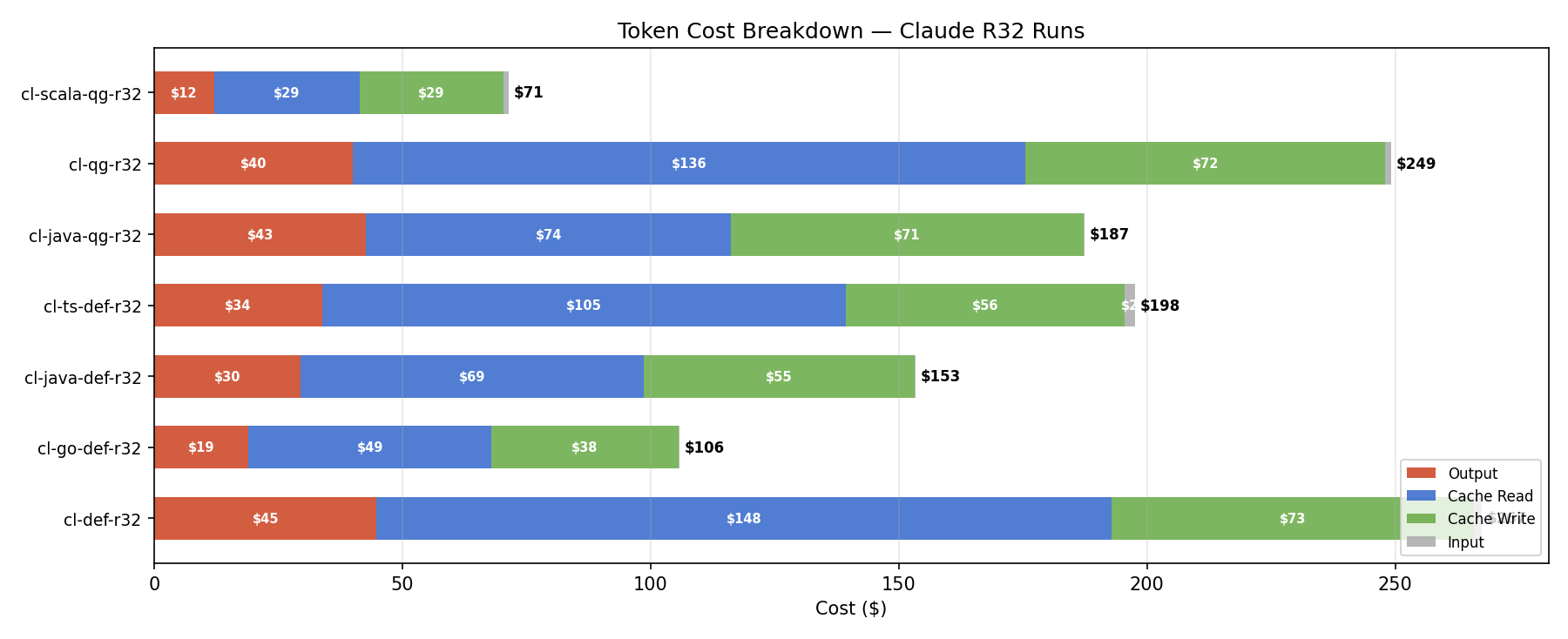
R32 所有 Claude 运行的成本构成。红色=output token (单价最高 $75/M),蓝色=cache read ($1.5/M),绿色=cache write ($18.75/M),灰色=input ($15/M)。
Output token 虽然只占总 token 量的 0.6%,但因为单价是 cache read 的 50 倍,实际占账单的 15-25%。Cache read 占 token 量的 95%+ 但因为单价极低,只占账单的 55-65%。Cache write 占约 25%。
这意味着:优化 output token (减少不必要的代码生成和重复) 对账单的影响远大于优化上下文长度。
"人类看不懂怎么办"
说得好像你 debug 过汇编似的。
我有过 RISC-V MMU 的调试经验——从内核第 1 行汇编开始,几百上千个寄存器。AI 半分钟写一个 dump 寄存器比较脚本,RAG 硬件手册推测结果。嵌入式开发群里超过一半资深工程师已经是这个工作流了。
答案:人类看懂模块边界和接口,需要深入时让 AI 解读。这和用反编译器、profiler、debugger 没有本质区别——你不需要裸眼读汇编来排查线上问题。
暴力美学:人类审美也会迁移的
别急着嫌 AI 写的代码丑。先回忆两个老朋友:
达夫设备(Duff's Device)——Tom Duff 在 1983 年写出的这段代码,把 switch 语句和 do-while 循环交织在一起,利用 C 语言 case 穿透的特性实现循环展开。第一眼看上去像是编译器 bug,实际上是对指令流水线的极致压榨。任何 code review 工具都会把它标红:结构化设计全部违反、可读性约等于零。但它的原理并不复杂——解释给专家听很容易懂,只是裸眼看代码时没人能一眼认出来。
1 | void send(short *to, short *from, int count) |
快速平方根倒数(Fast Inverse Square Root)——Quake
III 引擎里那个著名的 0x5f3759df
魔法数字。把浮点数强制转换为整数,位移一下,再用牛顿迭代法修正一次。那行
i = 0x5f3759df - ( i >> 1 ) 旁边的注释写的是 "what
the
fuck?"——据说是后来维护者加的。从软件工程视角看,它充满了未定义行为和不可理解的魔法常量。
1 | float Q_rsqrt(float number) |
这两段代码,从规范视角看一无是处。但它们凭借对硬件、数学和语言特性的极致压榨,实现了碾压常规写法的性能,最终成为程序员群体中代代传颂的经典,被赋予了独有的暴力美学。
人类审美不是固定的。如果未来 AI 写的代码正确性能得到验证,且更适合 AI 自己维护,并且执行效率也更高——人类会觉得这些天书代码美不胜收,主动学习。就像棋手学习 AlphaGo 棋路一样。没有人觉得 AlphaGo 的棋丑,大家只觉得看不懂,然后去学了。
历史的参照
四色定理:Appel 和 Haken(1976)将问题归约为 1,936 个不可避免构型的计算机穷举验证,后由 Robertson 等人(1997)简化到 633 个。人类几乎不可读。当年数学界对此争议了几十年——很多数学家不接受纯计算机证明的有效性。但 2005 年 Gonthier 用 Coq 形式化验证了该证明,争议基本平息。
这恰好说明:关键不是人类能不能读懂证明过程,而是有没有可靠的验证手段。
AlphaGo Zero:人类看不懂的棋路,但有明确的胜负反馈。
共同点:结果可以被独立验证。
所以未来 AI 软件验收原则应该是:形式化验证贯穿整个软件维护生命周期,模块开发时人类主要精力放在审查形式化规范有哪些变更,是否破坏了过去定下的规范。难以被形式化覆盖的部分,则依赖传统集成测试,配合 property-based testing,单元测试的必要性将会降低甚至可有可无。同时 AI 也可以辅助人类对产品设计文档进行形式化翻译,或者从形式化断言翻译回自然语言帮助人类理解,帮助检查自然语言中模糊的部分是否与过去的设计规范存在矛盾,并最终与形式化规范进行对齐。而软件功能的最终验收依然是人类负责,这部分暂时无法被替代,因为大部分软件的最终消费者是人类。
所以软件工程师在整个软件开发生命周期中,并不能完全放手,任由 AI 自行决策发挥。"AI 时代不再需要软件工程师"是老板想听的美好故事,而不是即将发生的现实。但有一点已经正在发生——AI 时代大批码农会失业,CS 专业会回冷,资深工程师的生产力得到了数倍放大,资本家可以采购一些 token 而裁掉开发部一半的 coder,这是已经产生的变化。就像织布机发明出来以后,工厂裁掉大批纺织女工,而招聘少量技术工人。数学家不会像计算器发明之前那样工作。今天,软件工程师也不应该。
结论
本文的核心:当前软件工程的工具和方法以人为本设计,面对 AI-native software 需要重新校准。
- 不是推翻软件工程,是重新校准规则。 复杂度始终存在,放任不管必然状态爆炸。
- 人类标准是 AI 的枷锁。 实验数据:人类规范让 agent 输掉 17 轮,屎山惩罚反而没有到来。
- 区分两种屎山: 架构屎山是人类的责任,代码屎山交给 lint 和 agent。
- 区分两类债务: 模块间的(对谁都有害,严控)和模块内的(对 AI 无害,放宽)。
- 架构分两层: 人类管边界(模块拓扑、接口契约),AI 管实现(模块内部自由)。
- "务实"需要重新定义: 红线画在对外边界,红线内部 AI 自由连锁修改。
- 验收靠验证不靠阅读。 形式化验证 > property-based testing。
- 一切皆可元。 AI 写代码,也写"写代码的规则",自己鞭策自己。
- 下一步: 需要补充 AI 原生 QG 组和周期性还债组的实验数据来完善论证。
以上测试大约烧了我 5000 USD 的 Opus 4.6 token。一开始我没有想到这次实验能有什么价值,能有什么新的结论产生。
但随着实验推进,我为了完善实验框架而构建的 harness 流程,以及实验数据揭露给我的、与我直觉相反的结论,都带给我不少震撼。若是一开始告诉我要做一个实验,花 5000 美金,结果未知——我肯定不做这个冤大头。
但现在,我觉得哪怕让我自掏腰包支付这 5000 美金也值了。在完善框架和反复测试 agent 极限的过程中,它对我的价值已经不是 5000 美金能衡量的了。
所以在这里我要开始插入卖课链接了——
 不开玩笑了。
不开玩笑了。
感谢所有跟随这个系列到第五篇的同道中人,你们给的情绪价值是我继续写作分享的动力。我所有实验框架代码和数据已经上传到 GitHub,感兴趣的读者可以自取,也可以让你的 AI 来分析我的实验过程——实验框架是如何一步步改进的。
请注意:该测试每个 agent 每轮会烧掉你 100-300 美金 Opus token。请谨慎在个人账户上复现,烧光了这周额度或者被 A 畜封号别怪我没提醒你。
项目地址: github.com/mingyang91/ming-bench — 包含完整的 benchmark 框架、策略文件、测试用例和编排工具。