所以更精确的表述是:AI
放大的上限不是你此刻的鉴别力,而是你鉴别力的成长速度。用的过程中学得越快,AI
能带你走得越远。但触发器永远是你自己的成长,不是 AI 的主动突破。
反过来,这也意味着输入和输出的上限都需要提高。你的输出能力决定了你能给
AI
多高质量的素材——更精准的提问,更扎实的种子内容,更清晰的框架。高质量的输入才能唤醒
AI 更高质量的输出。而你能否接住 AI
的高质量输出、消化它并转化为自己的成长,取决于你的输入接受能力。你的输出喂给
AI,AI 的输出喂给你的输入,两端的上限共同决定了 AI
对你的放大倍数——左脚踩右脚,螺旋升天。
所以 AI
在编程领域的"成功"并不能证明它已经接近人类智能——是编程领域的封闭性、短反馈和模块化恰好落在了
AI
的能力舒适区内。而一旦进入需要长程记忆、物理直觉和因果推理的领域,人类那些「像呼吸一样自然」的能力就成了
AI 难以跨越的鸿沟。你觉得 AI
已经很聪明了?那是因为你恰好在它最擅长的场地上观察它。
结语
AI 放大的上限是你的鉴别力,不是你的输出能力。「被超越」的错觉,来自
AI
的输出超过了观察者的鉴别力——你分不清好坏的时候,会误以为它什么都行。
但鉴别力本身不是静止的。用 AI
的过程中你会撞墙、会觉得不对劲、会追问,然后你的鉴别力会成长。AI
真正放大的,是这个成长的速度。你学得越快,它能带你走得越远。但触发器永远是你自己——AI
不会主动告诉你「你不知道什么」,它甚至会积极地用谄媚掩盖你的盲区。
This is a cultural adaptation — not a literal translation — of
the original
Chinese article. Some Chinese cultural references have been swapped
for Western equivalents that hit the same emotional note.
Foreword
Over the past year I've burned through more than $10,000 in API
tokens across Google, Anthropic, and OpenAI. So everything in this
article is based on hands-on experience with the strongest models
available — Opus 4.6, Codex-5.3-xhigh, Gemini 3 Pro — used without
budget constraints.
Those tokens were spread across four categories of projects: embedded
kernel drivers, backend architecture, DevOps, and frontend UI. The
performance gap between domains is absurd — $20 worth of tokens can
vibe-code a passable React dashboard with minimal human guidance, but
$2k or even $20k worth of tokens still can't get an agent to produce a
working kernel driver on real hardware. The conclusions below are drawn
from this cross-domain comparison.
The Phenomenon: Agent's
Crisis of Trust
It's like a late-night infomercial host waving his Quantum AI
Bio-Magnetic Resonance Healing Device™ at the camera, telling you
this machine — originally $200,000, but TODAY ONLY $88,000 — will cure
your chronic back pain, high blood pressure, diabetes, reverse your
arterial plaque buildup, coronary heart disease, and erectile
dysfunction.
Agent programming is currently in that exact state.
The agent showers you with emoji celebrating the fact that those
80,000 lines of slop it just generated passed all test cases, and
assures you it's ready for production. Do you believe it?
Say you're a project lead, and your most reliable teammate delivers
80% of tasks on time and at high quality. When they guarantee something
will ship next week, you can reasonably trust it'll be done by the week
after at the latest. But when an agent guarantees the code is
production-ready right now — do you believe it?
Meanwhile, at this very moment, an army of influencers, course
peddlers, and self-appointed "AI Godfathers" are separating suckers from
their money. The curriculum basically boils down to: here's how to
prompt (tools/skills, same wine in different bottles), then spin up a
bunch of agents to work in parallel.
A Real Case Study
An agent's blind confidence doesn't just mislead the user — it
misleads the agent itself.
I once gave an agent this task: integrate GCP Transcoding into the
current Kotlin project. I provided the product page and documentation as
references and told it to start planning. The agent produced the
following plan:
After reading the docs, discovered the service only provides a Java
SDK, and the current project uses a different JVM language without
native support
Per the RESTful API docs, manually integrate using ktor-client based
on documented field definitions
Write the code and run tests
Did you spot the problem in this plan?
If you've ever done this kind of work the old-fashioned way —
artisanal hand-crafted coding — you know that manually implementing a
RESTful API is never as simple as it sounds. Even covering just the
basic Transcoding capabilities involves 5–10 endpoints. Each endpoint's
request/response has dozens or even hundreds of nested field
definitions, and the agent makes frequent mistakes when dealing with
this kind of long-context task.
If instead the agent had chosen to write a thin wrapper around the
Java SDK (which Google generates from protobuf anyway), the feature
could have been stable and shipped within half a day to a day.
But if you let the agent go down the RESTful path, it'll sink into a
debugging swamp — because when AI hallucination causes it to get an
optional field name wrong (casing, camelCase, underscores), the program
won't throw an error right away. How long until you discover the
implementation is wrong? When customers complain after it hits
production?
To be fair, agents aren't making zero progress. For example, complex
cross-layer debugging — low-probability OS deadlocks, rendering
glitches, kernel panics, issues where the call chain is long and spans
multiple layers — was completely useless a year ago, but now it's
actually net-positive. It can't do full end-to-end root cause analysis,
but having the agent draft an effective short-scope investigation plan
works surprisingly well. That said, this still requires human leadership
— you give it direction, and it executes better and better; but let it
choose its own direction, and it'll drive you straight into a ditch.
Why can't we trust agents? After a year of practice,
I believe the root cause is: we lack effective means of
verification.
The Cause:
Total Failure of Verification Methods
Code Review Has Failed
Common take: "In a way, AI hasn't really replaced programmers — it's
just a new high-level tool. As the person responsible for production
code, you still need to understand what it does."
I'd argue this is nearly impossible in practice.
In our internal code reviews, most of the time we were really just
reviewing code style. The author would walk through the design,
we'd give it a once-over, and that was that. This used to work
because:
PRs with sloppy code style also had messy designs, poor performance,
and no extensibility
PRs with clean code style had clear designs, thoughtful performance
considerations, and even if there were bottlenecks, they were easy to
fix
But this correlation doesn't exist in the agent coding era —
in fact, it's inverted.
An agent can generate beautifully commented, stylistically flawless —
garbage code — in under a minute. When I eyeball it, I regularly get
lulled into a false sense of security by that first layer of polish. The
thing is, this garbage is hard to catch during review; it usually takes
a production incident and a deep investigation to discover it's
"chocolate-flavored crap."
Trust me — Opus, Codex-xhigh, those models you can't afford? I've
cranked every setting to max and mashed the gas. Same problem.
I also tried having AI review my designs. The sycophantic
tone is something else — I fed GPT-4o a design I knew was
flawed, and back came "enterprise-level," "future-proof," "scalable,"
just blowing smoke up my ass nonstop. I later changed the prompt to make
it roleplay as "that insufferable coworker" who criticizes everything,
and it got slightly better. But the end result was still underwhelming —
AI sees coherent, professional-sounding text and drops its guard, giving
high marks even when the content is dead wrong.
Testing Has Failed
Don't even get me started on testing. Test cases are now also
vibe-coded by the agent — it's both the player and the referee, whatever
it says goes. It's scammed me more than once. Thousands of lines of
getter/setter tests, all green, "ready for production, boss!"
Like the GCP Transcoding example: the agent misspelled an optional
field name, and the tests still passed — because the tests were also
written by the same agent. Consistently wrong = "correct."
Some people suggest: have different agents specialize — one writes
code, another writes tests. I've tried it. It's marginally better than
self-testing; obvious bugs do get caught. But these agents share the
same training data and systematic biases — their blind spots overlap
almost completely. Unlike two human developers — one from an embedded
systems background, one from web dev — whose knowledge structures and
cognitive blind spots actually complement each other. Two agents, no
matter how you split the roles, are fundamentally classmates from the
same bootcamp. You've solved the "same person writes and grades the
exam" problem, but not the "every exam writer graduated from the same
program" problem.
And AI reviewing itself has steeply diminishing returns. If the first
review agent missed an issue, the second and third reviews will almost
certainly miss it too — unless you can feed them additional error
information.
Comparison with
Traditional Industry
At this point someone might ask: don't other industries face this
problem after being augmented by machines and automation?
Let me use CNC machining as an analogy:
A CNC machine is more precise than I am, but after it produces a
part, we can perform objective physical measurement — grab some
calipers, check whether the tolerance is within ±0.01mm. Crystal clear.
Even if I couldn't hand-machine a part to that precision, I can still
evaluate whether the CNC machine and its output meet the
standard.
That's the state of traditional manufacturing after machine
augmentation: machines are precise, quality is consistent and stable,
and humans can still evaluate the output.
So what should the ideal state look like for software development
after the Agent revolution? The agent delivers code that genuinely
covers the requirements, includes basic security protections, and is
easier to maintain long-term (even if we only consider
agent-maintainability, not human readability), with better performance
and lower resource consumption.
But software doesn't just need to satisfy the current requirements
doc — it also needs to account for basic security. A feature-complete
project riddled with security holes is still failing.
And right now, we can't evaluate whether agents have reached that
state. For just the baseline requirement of "feature implementation,"
agents still can't operate without human guidance and test verification
— let alone security, maintainability, and performance.
The problem is: our mainstream verification methods — human review
and automated testing — can both be "contaminated" by the agent. It can
write stylistically perfect but logically toxic code, and it can write
tests that perfectly match the flawed code. What we need is a set of
calipers the agent can't tamper with — objective, deterministic
verification that doesn't rely on the agent's own judgment.
A CNC machine that achieves great precision on plastic and aluminum
parts doesn't necessarily maintain that precision on titanium or
stainless steel. The latter tests overall rigidity and the thermal
expansion compensation requirements as workpiece mass increases.
Same principle: code that passes a couple of mouse clicks in local
testing will, with high probability, blow up spectacularly in
production.
Traditional industry: machines are precise, quality is
stable, humans can evaluate. Software industry: agents are fast,
coverage is broad, but humans can't reliably evaluate. That's the
problem — where are the calipers?
The Solution:
Let the Compiler Be Your Gatekeeper
Since human evaluation (code review) and automated testing are both
unreliable, we need another evaluation method — one that is objective,
verifiable, and doesn't depend on the agent's own judgment.
My position runs counter to mainstream AI coding philosophy:
In the agent coding era, we need stronger types,
stricter verifiable languages — not letting agents run wild
with Python, JS, Java, Go, and let's not forget AnyScript.
Why?
AI piles up slop at such velocity — forget tens of thousands of
lines, I'm already too lazy to read line-by-line past 100 lines. But
reading type signatures and pre/post-conditions is dramatically faster
than reading logic code. And these things can only be provided by Rust,
Scala, Haskell, or even formal methods.
I was already writing code this way before agents existed — once your
codebase gets large enough, compiler checks are more reliable than
eyeballing it. Now that agent coding has become mainstream, I've found
that holding agents to this standard is one of the more effective ways
to control output quality — only to a degree, of course, but at least
better than nothing.
Back to the GCP Transcoding example: if the agent were using a
strongly-typed language, misspelled field names would at least get
caught by the type system at compile time. But with RESTful + weak
typing, errors are silent until it's too late.
But this is only the first line of defense. Strong typing catches
type mismatches, null pointer issues, Rust's lifetime errors — these are
"syntax-level" problems. The compiler can tell you "this code doesn't
compile," but it can't tell you "this code is logically wrong."
Second Line of
Defense: Let z3 Prove It For You
The next level is formal-methods-grade verification — using
refinement types or tools like OpenJML to encode business constraints
directly into the type system.
A concrete example: have the agent write a sort function. Traditional
strong typing ensures the input/output types are correct — takes an
array, returns an array. But it can't ensure the returned array is
actually sorted. With refinement types, you can write this directly in
the function signature:
1
ensures(forall i, j : i < j → arr[i] ≤ arr[j])
This pre/post-condition is your "quality tolerance standard." The z3
solver will mathematically prove whether the agent's
hundred-line sort implementation actually satisfies this constraint for
all possible inputs. Proof passes = passes. Proof fails = fails. There's
no room for the agent to bluff its way through by insisting "looks fine
to me."
The key insight: humans only need to review this one line of
spec to verify it expresses the intended semantics — no need to read
hundreds of lines of implementation. This is the set of
calipers the agent can't tamper with.
Practical Results
First line of defense — credit where it's due. The latest top-tier
models can usually pass compilation, unless you're even more obsessed
with type-level gymnastics than I am.
In the past, agents hitting Rust lifetime errors or functional type
puzzles would loop for dozens of rounds or spiral into infinite retries
until context blew up. Formal methods have a steep learning curve to
begin with — even the human brain has to maintain continuous abstract
symbolic reasoning. I once believed AI would never learn to solve
type-level puzzles.
But things have changed. Pure-FP Scala, tagless final — Opus 4.5 and
Codex-xhigh follow the patterns quite well, and passing compilation is
basically automatic now. Functional type gymnastics produce error
messages that are dozens or hundreds of lines of type-theoretic
hieroglyphics, and agents can now read and fix these without much
trouble.
The crucial point: agents aren't solving type puzzles by cheating
(slapping asInstanceOf or any everywhere).
They genuinely fill in the gaps through iterative attempts. This isn't
circumvention — it gives me real confidence that AI might actually be
able to write code that passes FM checks. If that happens, code
correctness gets a formal guarantee, which is far more comprehensive and
reliable than unit test coverage.
But the second line of defense is still another world entirely.
FM-grade verification errors — z3 solver failures, refinement type
constraint violations — agents still struggle badly with these. Though
the breakthrough on the first line makes me believe this path has
potential.
Limitations
Of course, this approach has its limits.
In practice, formal methods toolchains and ecosystems are still
barren — most only support a very limited subset of a single language.
Many engineering patterns and syntax that are bread-and-butter in
production code are unsound or unproven in FM land. And that's before we
get to the infinite loops and unprovable proofs — one wrong move and the
z3 solver is searching a possibility space larger than the observable
universe, still grinding away when the heat death arrives.
Strong types and FM solve some problems, but not all.
The Deeper Dilemma: Plan
vs. Execute
Even with strong types + FM as evaluation tools, there's a deeper
problem: the agent's understanding and execution of plans.
The GCP Transcoding example already exposed this: the agent chose to
manually implement RESTful instead of wrapping the Java SDK. This wasn't
a coding error — it was a strategic error. The compiler
can tell you if there's a syntax error; z3 can prove whether your
implementation meets the spec; but neither can tell you whether you
should be walking this path at all.
A more extreme example: give an agent a complex task — design a
rocket engine. The plan calls for a full-flow staged combustion cycle;
the approach specifies a coaxial design.
If the agent doesn't follow the plan: it might
wander off into a gas-generator cycle. The compiler can tell you the
code compiles, but it can't tell you whether this is the rocket engine
you asked for.
If the agent follows the plan too
faithfully: it actually builds the coaxial design, and then you
hit an even bigger problem in production — the dynamic sealing system
fails, oxidizer and fuel leak into each other through the turbine shaft,
and one of the preburners is about to have a very bad day. The compiler
can guarantee type correctness, z3 can guarantee the implementation
matches the spec, but neither can guarantee the spec itself is a sound
design.
The current plan/edit mode toggle is just a stopgap — an admission
that we don't have a better answer yet. This problem is harder than
"missing evaluation tools" because it involves understanding
requirements and design, not just code quality.
Peak on First Contact
Agent programming has a striking characteristic: it peaks on
first contact.
Hand an agent a brand-new CRUD project or a React admin panel, and
its first attempt genuinely impresses — clean, well-structured,
thoughtfully commented with error handling baked in.
But as the project matures, the unspoken, undocumented,
implicitly-understood hidden context keeps growing. Which field is
deprecated but never deleted, which API has a historical quirk, which
modules have a subtle dependency — the veterans know all this by heart,
but nobody ever wrote it down.
And agents can't handle infinite context. They can only selectively
forget through compression and summarization. What gets dropped might be
the lessons from failed attempts, or it might be critical data structure
offsets, register addresses, or enum definitions.
This isn't a feeling. In practice, when context window usage hits
~30% the agent is already noticeably dumber, and at ~50% it's performing
worse than the base model. Even when critical details are still
technically in-context, the agent will look right through them.
Every time you start a new session, you're facing an almost brand-new
"employee" — one that seems to have inherited compressed context
(claude.md / agents.md) but knows none of the details. You have to
re-explain everything: "No, I know the docs say to pass this parameter,
but in practice we never actually send it…"
For CRUD, Spring, and React — highly repetitive tasks — this barely
registers as a pain point. It's basically the same thing every time;
forgotten, so what.
But for embedded systems development, any forgotten detail gets
filled in by the agent's wildly creative hallucinations. Register
address wrong? Interrupt priority misconfigured? DMA channel conflict?
Minor case: system crash. Major case: permanently fried hardware. This
isn't a "fix the bug and redeploy" situation.
Worse still, kernels are riddled with register addresses and flag
constants, and these are critical when we're inspecting memory. Once the
AI compresses away these details from its context, its next decision
could be a completely wrong-direction red herring — not "insufficiently
good," but "fundamentally wrong." This is why in these scenarios, I'd
rather endure the cognitive degradation from long context than ever let
the agent compress. This information genuinely cannot be lost.
And debugging isn't a linear process. We're often holding multiple
hypotheses simultaneously, validating each in turn. Path A hits a wall,
so we switch to Path B — but that doesn't mean Path A was a dead end.
Maybe our understanding just wasn't sufficient at the time. After
accumulating new insights on Path B, looking back, that earlier attempt
on Path A doesn't seem hopeless after all. So I return to Path A — but
the AI? You'll probably be facing a fresh-faced newbie with zero
knowledge of everything we previously explored on Path A. Human
debugging experience accumulates in spirals; agent memory is
one-shot.
In
the Agent Era, Do You Still Need to Learn CS Fundamentals?
Since evaluating agent output is the core challenge, developer
fundamentals are obviously still essential. Without them, what are you
going to use to evaluate the code, modules, and architectural designs
that agents generate? A developer without evaluation capabilities is no
different from the retirees getting fleeced at the infomercial gadget
store.
So how should you learn?
Open LeetCode, haven't even finished reading the problem, and Copilot
has already autocompleted the solution. Hit Submit & Run — top 1%.
Is that it?
My take: since we have AI now, of course you can't stay at
yesterday's difficulty level. Crank it up. Crank it up until AI
taps out.
Don't worry — you won't miss any fundamentals. Once the difficulty is
high enough, AI hallucinations multiply, and you'll have to fill in
every gap yourself. The AI will actively mislead you along the way — but
that's precisely the learning opportunity.
Say you want to implement a red-black tree, B-tree, or AVL tree.
Crank it up: add formal verification, throw in generics support. Relax —
the current strongest models can't do it either.
Hallucinations actually help you learn — because they
contain common misconceptions. The process of verifying and correcting
hallucinations deepens your understanding of the material.
Of course, not everyone needs to jump straight to formal
verification. A more practical first step: learn to write specs instead
of implementations. Before letting the agent start, write out the
pre/post-conditions for the feature in plain English — what conditions
the input must satisfy, what constraints the output must meet, which
edge cases must be covered. Then use that spec as the agent's acceptance
criteria, instead of tossing in a one-liner wish and hoping for the
best.
From plain-English specs to property-based tests to refinement types
— you can walk this path gradually. But the core competency is the same:
accurately describing what you want. This is itself a
manifestation of CS fundamentals, and it's the single most irreplaceable
human capability in the agent era.
Conclusion
AI frameworks, models, tools, and methodologies are popping up left
and right, changing by the day. But at the end of the day, they're all
just patches and add-ons for the model.
When humans work through a complete workflow, they don't need to
decompose themselves into multiple "sub-agents" to collaborate — because
humans genuinely have memory and genuinely learn. The longer you work,
the more you grow, the more skilled you become. The hidden context in a
project, the pitfalls you've stepped on, the unwritten rules — they all
sediment into experience.
Agents are the opposite. The longer the context, the steeper the
cognitive decline. Even when details are still technically in context,
agents increasingly ignore them, hallucinating things that "look
reasonable" to fill in the gaps.
The core problem hasn't changed: we still lack reliable means to
evaluate agent output. Strong typing is a partial first-layer solution,
FM verification is a partial second-layer solution — but they're both
only partial solutions.
Skip one day of learning, you'll miss a lot. Skip a whole year, and
somehow you haven't missed much at all.
Frameworks and tools iterate and churn, flavor-of-the-month hype
cycles come and go, but their marketing far outstrips their actual
capability and value. CS fundamentals are the time-tested hard currency.
Rather than chasing the next hot framework or tool, invest your energy
in strengthening your ability to evaluate agent output — that's
the truly scarce resource in the agent era.
Addendum:
Kernel NIC Driver Development War Story
After this article was published, readers asked about AI's actual
capabilities with cross-layer complex problems. Here's a complete case
study.
I once gave a talk at Tsinghua University's open-source OS community,
sharing my experience developing a kernel NIC (network interface card)
driver with AI assistance. The models at the time were Claude 3.7
through 4.0, and the result was net-negative — 90% of the information
was hallucinated misguidance. The AI conflated behaviors from dwmac
versions 2.x through 5.x, dragged in Qualcomm and Intel chip code, and
don't even get me started on PHY chip registers and C22/C45 protocol
details.
Training data for this domain is relatively siloed — vendor
documentation is locked behind NDAs and member registrations. The total
number of people worldwide who've done end-to-end work on this specific
chip is probably under 100. AI has no clean reference material to draw
from. The kernel repository has 10–20 years of history, thousands of
commits, hundreds of thousands of lines of code, plus a mountain of
vendor-specific and architecture-specific workarounds — all of which is
noise to the AI.
At first, I was the outsider, and the collaboration model was
AI calls the shots, I do the grunt work — I'd execute
whatever approach the AI suggested and report back with error data. But
as I learned more and realized the AI was feeding me nonsense, the roles
flipped: I chart the reverse-engineering path, AI
executes — tirelessly running bit-level comparison experiments
over and over. The final conclusions and next-step decisions were
co-produced by human + AI, not by letting AI make big autonomous
leaps.
This case study actually validates several earlier points: AI
hallucination is especially severe in domains with sparse training data;
losing register-level details from long context is catastrophic; and the
spiral nature of debugging is something current agent architectures
simply cannot handle. But in reverse — once the human takes the wheel,
AI as a tireless executor doing bit-level repetitive comparison work is
genuinely a huge help.
关键是:agent 解决类型体操并不是靠作弊(比如到处 asInstanceOf 或者
any),而是通过反复尝试,真正填补了这些形式化过程的
gap。这不是绕过,反而给了我足够的信心——说不定 AI 真的能写出通过 FM
检查的代码。如此一来,代码的正确性就有了形式化保证,这远比单元测试覆盖更全面、更可靠。
但第二层目前还是另一个世界。FM 级别的验证错误——z3
求解失败、refinement type 约束不满足——agent
处理起来仍然非常吃力。不过第一层的突破让我相信,这条路是有希望的。
局限性
当然,这个方案也有局限。
实际上现在的 formal method
工具链和生态还是很贫瘠,基本上只支持一门语言很有限很小的一个子集。有些工程上常用的语法/模式在
FM 那边都是
unsound,或者尚未证明。更不用说动不动就陷入死循环/无解证明了——稍不注意,z3
求解器要在比宇宙空间还大的可能性里搜索,到宇宙毁灭那一天都证明不出来。
更要命的是,kernel 里充斥着大量寄存器地址、flag 常量,而我们 inspect
内存的时候这些都是关键信息。一旦 AI
压缩上下文时把这些细节遗忘了,它的下一个决策可能是完全反向误导你——不是「不够好」,而是「彻底错误」。这也是为什么在这类场景下,我宁愿忍受长上下文带来的降智,也绝不肯让
agent 压缩上下文。这些信息是真的不能丢。
更何况,debug
的过程本身就不是线性的。我们经常同时考虑多种可能性,分别验证。A
路线走不通,切换到 B 路线——但这不意味着 A
路线就是死路,可能只是当时的认知还不够。等在 B
路线里积累了新的理解,回头一想,A
路线当初做过的尝试似乎并非死路一条。此时我再回到 A
路线上来——我人是回来了,AI 呢?你大概率会面对一个清纯的新手 AI,对之前在
A 路线上的所有探索一无所知。人类 debug 的经验是螺旋式积累的,而 agent
的记忆是一次性的。
我曾在清华开源操作系统社区做过一次报告,分享了在 AI
辅助下开发内核网卡驱动的踩坑经验。当时使用的模型是 Claude 3.7 到
4.0,效果完全是帮倒忙——90% 的信息都是幻觉误导。AI 混合了 dwmac 从 2.x 到
5.x 各个版本的行为,甚至牵扯到高通/Intel 芯片的代码,更不用说 PHY
芯片的寄存器、C22/C45 协议这些了。
这类领域的训练数据和讨论比较封闭,厂家文档藏着掖着,要注册会员才能获取。全链路做过这款芯片的人可能全世界不到
100 人,AI 没有清晰可借鉴的经验。Kernel 仓库里的代码有 10-20
年历史,几千次提交,十几万行代码,还有一大堆不同厂商不同架构导致的
workaround——这些对 AI 来说都是噪音。
一开始我是外行,协作方式是 AI
做鞭子、我做牛马——我负责执行 AI
给出的方案并反馈错误信息。但随着我越来越懂,发现 AI
净给我胡扯,于是角色翻转:我指定逆向路径,AI
帮我执行,不厌其烦地一遍一遍做 bit
级别对比实验。最终的结论和下一轮路线决策是人 + AI 一起产出的,而不是让
AI 直接大跨度地做下一步。
这个案例其实印证了前面的几个观点:训练数据稀缺的领域 AI
幻觉尤其严重;长上下文中的寄存器级细节一旦丢失就是灾难;而 debug
的螺旋式推进过程,目前的 agent
架构根本无法胜任。但反过来说,当人类掌握了主导权之后,AI
作为一个不知疲倦的执行者,在 bit 级别的重复对比实验上确实帮了大忙。
Many data systems use polling refresh to display lists, which can
cause a delay in updating content status and cannot immediately provide
feedback to users on the page. Shortening the refresh time interval on
the client side can lead to an excessive load on the server, which
should be avoided.
To solve this problem, this article proposes an event subscription
mechanism. This mechanism provides real-time updates to the client,
eliminating the need for polling refresh and improving the user
experience.
Terminologies and Context
This article introduces the following concepts:
Hub: An event aggregation center that receives
events from producers and sends them to subscribers.
Buffer: An event buffer that caches events from
producers and waits for the Hub to dispatch them to subscribers.
Filter: An event filter that only sends events
meeting specified conditions to subscribers.
Broadcast: An event broadcaster that broadcasts the
producer's events to all subscribers.
Observer: An event observer that allows subscribers
to receive events through observers.
The document discusses some common concepts such as:
Pub-Sub pattern: It is a messaging pattern where the sender
(publisher) does not send messages directly to specific recipients
(subscribers). Instead, published messages are divided into different
categories without needing to know which subscribers (if any) exist.
Similarly, subscribers can express interest in one or more categories
and receive all messages related to that category, without the publisher
needing to know which subscribers (if any) exist.
Filter:
Topic-based content filtering mode is based on topic filtering
events. Producers publish events to one or more topics, and subscribers
can subscribe to one or more topics. Only events that match the
subscribed topics will be sent to subscribers. However, when a terminal
client subscribes directly, this method has too broad a subscription
range and is not suitable for a common hierarchical structure.
Content-based content filtering mode is based on message content
filtering events. Producers publish events to one or more topics, and
subscribers can use filters to subscribe to one or more topics. Only
events that match the subscribed topics will be sent to subscribers.
This method is suitable for a common hierarchical structure.
Functional Requirements
Client users can subscribe to events through gRPC Stream, WebSocket,
or ServerSentEvent.
Whenever a record's status changes (e.g. when the record is updated
by an automation task) or when other collaborators operate on the same
record simultaneously, an event will be triggered and pushed to the
message center.
Events will be filtered using content filtering mode, ensuring that
only events that meet the specified conditions are sent to
subscribers.
Architecture
flowchart TD
Hub([Hub])
Buffer0[\"Buffer drop oldest"/]
Buffer1[\"Buffer1 drop oldest"/]
Buffer2[\"Buffer2 drop oldest"/]
Buffer3[\"Buffer3 drop oldest"/]
Filter1[\"File(Record = 111)"/]
Filter2[\"Workflow(Project = 222)"/]
Filter3[\"File(Project = 333)"/]
Broadcast((Broadcast))
Client1(Client1)
Client2(Client2)
Client3(Client3)
Hub --> Buffer0
subgraph Server
Buffer0 --> Broadcast
Broadcast --> Filter1 --> Buffer1 --> Observer1
Broadcast --> Filter2 --> Buffer2 --> Observer2
Broadcast --> Filter3 --> Buffer3 --> Observer3
end
subgraph Clients
Observer1 -.-> Client1
Observer2 -.-> Client2
Observer3 -.-> Client3
end
After listening to the change event, debounce and re-request the
list interface, and then render it.
When leaving the page, cancel the subscription.
Servers should follow these steps:
Subscribe to push events based on the client's filter.
When the client's backlog message becomes too heavy, delete the
oldest message from the buffer.
When the client cancels the subscription, the server should also
cancel the broadcast to the client.
Application /
Component Level Design (LLD)
flowchart LR
Server([Server])
Client([Client: Web...])
MQ[Kafka or other]
Broadcast((Broadcast))
subgraph ExternalHub
direction LR
Receiver --> MQ --> Sender
end
subgraph InMemoryHub
direction LR
Emit -.-> OnEach
end
Server -.-> Emit
Sender --> Broadcast
OnEach -.-> Broadcast
Broadcast -.-> gRPC
Broadcast -.-> gRPC
Broadcast -.-> gRPC
Server -- "if horizon scale is needed" --> Receiver
gRPC --Stream--> Client
For a single-node server, a simple Hub can be implemented using an
in-memory queue.
For multi-node servers, an external Hub implementation such as Kafka,
MQ, or Knative eventing should be considered. The broadcasting logic is
no different from that of a single machine.
Failure Modes
Fast Producer-Slow Consumer
This is a common scenario that requires special attention. The
publish-subscribe mechanism for terminal clients cannot always expect
clients to consume messages in real time. However, message continuity
must be maximally guaranteed. Clients may access our products in an
uncontrollable network environment, such as over 4G or poor Wi-Fi. Thus,
the server message queue cannot become too backlogged. When a client's
consumption rate cannot keep up with the server's production speed, this
article recommends using a bounded Buffer with the
OverflowStrategy.DropOldest strategy. This ensures that
subscriptions between consumers are isolated, avoiding too many unpushed
messages on the server (which could lead to potential memory leak
risks).
This document proposes an event subscription mechanism to address the
delay in updating content status caused by polling refresh. Clients can
subscribe to events through any long connection protocol, and events
will be filtered based on specified conditions. To avoid having too many
unpushed messages on the server, a bounded buffer with the
OverflowStrategy.DropOldest strategy is used.
Implementing this in Reactive Streams is straightforward, but you can
choose your preferred technology to do so.
In the previous
post, we discussed how to implement a file tree in PostgreSQL using
ltree. Now, let's talk about how to integrate version
control management for the file tree.
Version control is a process for managing changes made to a file tree
over time. This allows for the tracking of its history and the ability
to revert to previous versions, making it an essential tool for file
management.
With version control, users have access to the most up-to-date
version of a file, and changes are tracked and documented in a
systematic manner. This ensures that there is a clear record of what has
been done, making it much easier to manage files and their versions.
Terminologies and Context
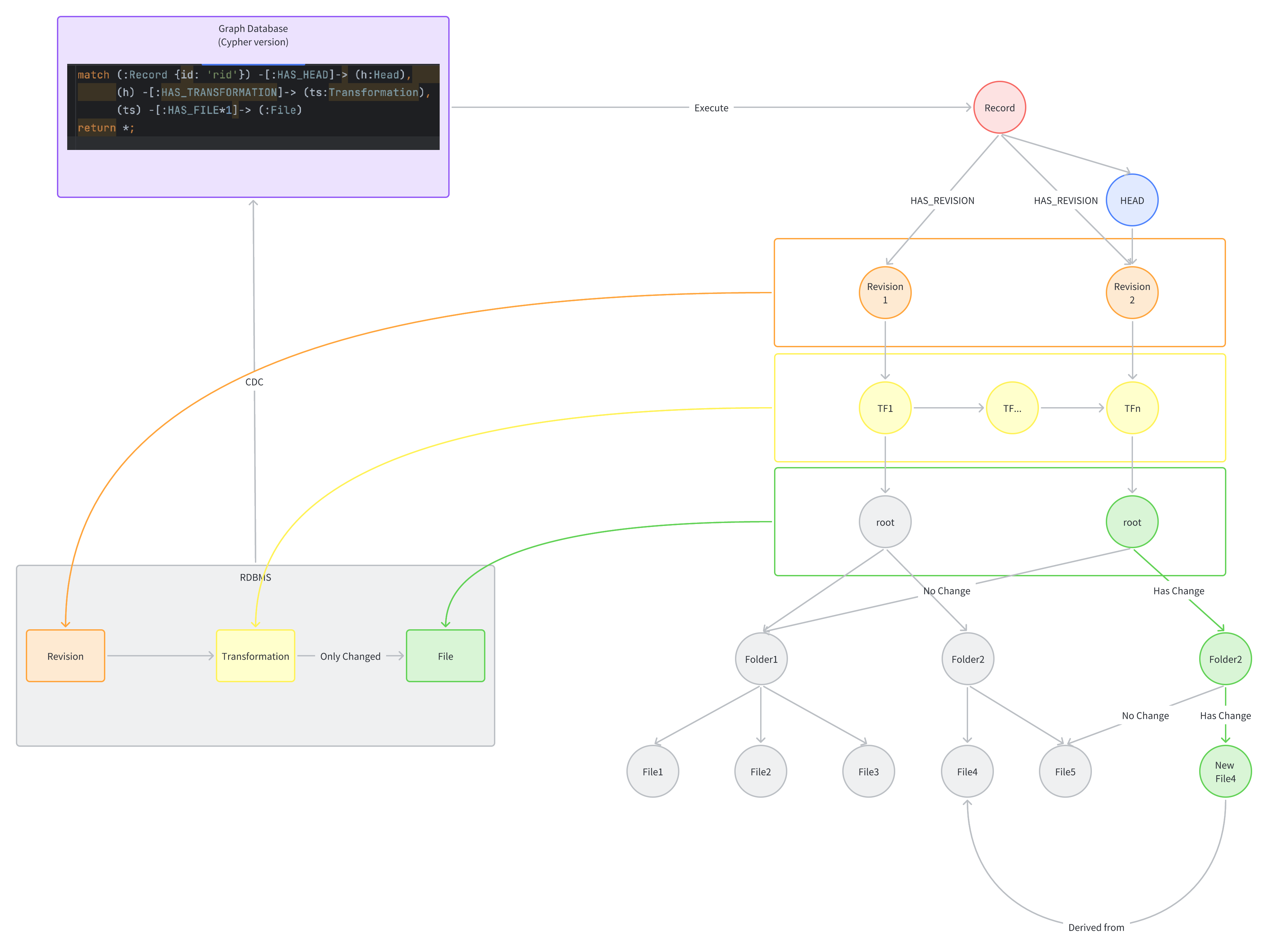
One flawed implementation involves storing all file
metadata for every commit, including files that have not changed but are
recorded as NO_CHANGE. However, this approach has a
significant problem.
The problem with the simple and naive implementation of storing all
file metadata for every commit is that it leads to significant write
amplification, as even files that have not changed are recorded as
NO_CHANGE. One way to address this is to avoid storing
NO_CHANGE transformations when creating new versions, which
can significantly reduce the write amplification.
This is good for querying, but bad for writing. When we need to fetch
a specific version, the PostgreSQL engine only needs to scan the index
with the condition file.version = ?. This is a very cheap
cost in modern database systems. However, when a new version needs to be
created, the engine must write \(N\)
rows of records into the log table (where \(N\) is the number of current files). This
will cause a write peak in the database and is unacceptable.
In theory, all we need to do is write the changed file. If we can
find a way to fetch an arbitrary version of the file tree in \(O(log(n))\) time, we can reduce unnecessary
write amplification.
Non Functional Requirements
Scalability
Consider the worst-case scenario: a file tree with more than 1,000
files that is committed to more than 10,000 times. The scariest
possibility is that every commit changes all files, causing a decrease
in write performance compared to the efficient implementation. Storing
more than 10 million rows in a single table can make it difficult to
separate them into partitioned tables.
Suppose \(N\) is the number of
files, and \(M\) is the number of
commits. We need to ensure that the time complexity of fetching a
snapshot of an arbitrary version is less than \(O(N\cdot log(M))\). This is theoretically
possible.
Latency
In the worst case, the query can still respond in less than
100ms.
PostgreSQL has a keyword called LATERAL. This keyword
can be used in a join table to enable the use of an outside table in a
WHERE condition. By doing so, we can directly tell the
query optimizer how to use the index. Since data in a combined index is
stored in an ordered tree, finding the maximum value or any arbitrarily
value has a time complexity of \(O(log(n))\).
Finally, we obtain a time complexity of \(O(N \cdot log(M))\).
Performance
Result: Fetching an arbitrary version will be done in tens of
milliseconds.
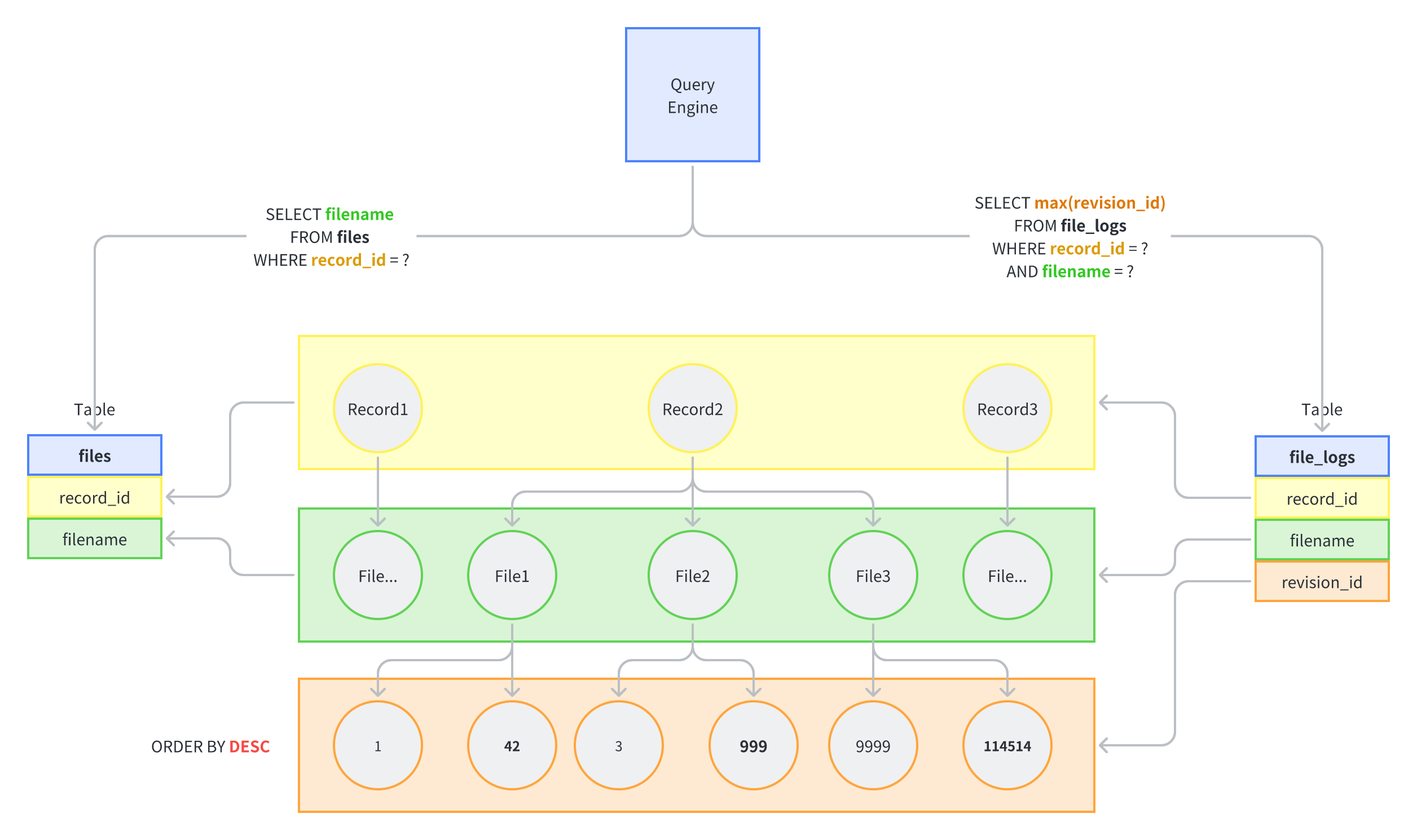
1 2 3 4 5 6 7 8 9 10 11 12 13
explain analyse select f.record_id, f.filename, latest.revision_id from files f innerjoinlateral ( select* from file_logs fl where f.filename = fl.filename and f.record_id = fl.record_id -- and revision_id < 20000 orderby revision_id desc limit 1 ) as latest on f.record_id ='f5c2049f-5a32-44f5-b0cc-b7e0531bf706';
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Nested Loop (cost=0.86..979.71rows=1445 width=50) (actual time=0.040..18.297rows=1445 loops=1) -> Index Only Scan using files_pkey on files f (cost=0.29..89.58rows=1445 width=46) (actual time=0.019..0.174rows=1445 loops=1) Index Cond: (record_id ='f5c2049f-5a32-44f5-b0cc-b7e0531bf706'::uuid) Heap Fetches: 0 -> Memoize (cost=0.57..0.65rows=1 width=4) (actual time=0.012..0.012rows=1 loops=1445) " Cache Key: f.filename, f.record_id" Cache Mode: binary Hits: 0 Misses: 1445 Evictions: 0 Overflows: 0 Memory Usage: 221kB -> Subquery Scan on latest (cost=0.56..0.64rows=1 width=4) (actual time=0.012..0.012rows=1 loops=1445) -> Limit (cost=0.56..0.63rows=1 width=852) (actual time=0.012..0.012rows=1 loops=1445) -> Index Only Scan Backward using file_logs_pk on file_logs fl (cost=0.56..11.72rows=158 width=852) (actual time=0.011..0.011rows=1 loops=1445) Index Cond: ((record_id = f.record_id) AND (filename = (f.filename)::text)) Heap Fetches: 0 Planning Time: 0.117 ms Execution Time: 18.384 ms
Test Datasets
This dataset simulates the worst-case scenario of a table with 14.6
million rows. Specifically, it contains 14.45 million rows representing
a situation in which 1,400 files are changed 10,000 times.
1 2 3 4 5
-- cnt: 14605858 selectcount(0) from file_logs; -- cnt: 14451538 selectcount(0) from file_logs where record_id ='f5c2049f-5a32-44f5-b0cc-b7e0531bf706';
A file tree is a hierarchical structure used to organize files and
directories on a computer. It allows users to easily navigate and access
their files and folders, and is commonly used in operating systems and
file management software.
But implementing file trees in traditional RDBMS like MySQL can be a
challenge due to the lack of support for hierarchical data structures.
However, there are workarounds such as using nested sets or materialized
path approaches. Alternatively, you could consider using NoSQL databases
like MongoDB or document-oriented databases like Couchbase, which have
built-in support for hierarchical data structures.
It is possible to implement a file tree in PostgreSQL using the
ltree datatype provided by PostgreSQL. This datatype can
help us build the hierarchy within the database.
TL;DR
Pros
Excellent performance!
No migration is needed for this, as no new columns will be added.
Only a new expression index needs to be created.
Cons
Need additional mechanism to create virtual folder entities.(only if
you need to show the folder level)
There are limitations on the file/folder name length.(especially in
non-ASCII characters)
Limitation
The maximum length for a file or directory name is limited, and in
the worst case scenario where non-ASCII characters(Chinese) and
alphabets are interlaced, it can not be longer than 33
characters. Even if all the characters are Chinese, the name can not
exceed 62 characters in length.
Based on PostgreSQL documentation,
the label path can not exceed 65535 labels. However, in most cases, this
limit should be sufficient and it is unlikely that you would need to
nest directories to such a deep level.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
select escape_filename_for_ltree( '一0二0三0四0五0六0七0八0九0十0'|| '一0二0三0四0五0六0七0八0九0十0'|| '一0二0三0四0五0六0七0八0九0十0'|| '一0二0' ); -- worst case len 34 select escape_filename_for_ltree( '一二三四五六七八九十'|| '一二三四五六七八九十'|| '一二三四五六七八九十'|| '一二三四五六七八九十'|| '一二三四五六七八九十'|| '一二三四五六七八九十'|| '一二三' ); -- Chinese case len 63
1
[42622] ERROR: label string is too long Detail: Label length is 259, must be at most 255, at character 260. Where: PL/pgSQL function escape_filename_for_ltree(text) line 5 at SQL statement
How to use
Build expression index
1
CREATE INDEX idx_file_tree_filename ON files using gist (escape_filename_for_ltree(filename));
Example Query
1 2 3 4 5
explain analyse select filename from files where escape_filename_for_ltree(filename) ~'ow.*{1}' and record_id ='1666bad1-202c-496e-bb0e-9664ce3febcb';
Bitmap Heap Scan on files (cost=32.12..36.38rows=1 width=28) (actual time=0.341..0.355rows=8 loops=1) Recheck Cond: ((record_id ='1666bad1-202c-496e-bb0e-9664ce3febcb'::uuid) AND (escape_filename_for_ltree((filename)::text) <@ 'ow'::ltree)) Heap Blocks: exact=3 -> BitmapAnd (cost=32.12..32.12rows=1 width=0) (actual time=0.323..0.324rows=0 loops=1) -> Bitmap Index Scan on idx_file_tree_record_id (cost=0.00..4.99rows=93 width=0) (actual time=0.051..0.051rows=100 loops=1) Index Cond: (record_id ='1666bad1-202c-496e-bb0e-9664ce3febcb'::uuid) -> Bitmap Index Scan on idx_file_tree_filename (cost=0.00..26.88rows=347 width=0) (actual time=0.253..0.253rows=52 loops=1) Index Cond: (escape_filename_for_ltree((filename)::text) <@ 'ow'::ltree) Planning Time: 0.910 ms Execution Time: 0.599 ms
Explaination
PostgreSQL's LTREE data type allows you to use a sequence of
alphanumeric characters and underscores on the label,
with a maximum length of 256 characters. So, we get a special character
underscore that can be used as a notation to
build our escape rules within the label.
Slashes(/) will be
replaced with dots(.). I
think it does not require further explanation.
Initially, I attempted to encode all non-alphabetic characters into
their Unicode hex format. However, after receiving advice from other
guys, I discovered that using base64 encoding can be
more efficient in terms of information entropy. Ultimately, I decided to
use base62 encoding instead to ensure that no illegal
characters are produced and to achieve the maximum possible information
entropy.
This is the final representation of the physical data that will be
stored in the index of PostgreSQL.
If you want to store an isolated file tree in the same table, one
thing you need to do is prepend the isolation key as the first label of
the ltree. For example:
By doing this, you will get the best query performance.
Summary
This document explains how to implement a file tree in PostgreSQL
using the ltree datatype. The ltree datatype
can help build the hierarchy within the database, and an expression
index needs to be created. There are some limitations on the file/folder
name length, but the performance is excellent. The document also
provides PostgreSQL functions for escaping and encoding file/folder
names.
Appendix: PostgreSQL
Functions
Entry function (immutable
is required)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
CREATEOR REPLACE FUNCTION escape_filename_for_ltree(filename TEXT) RETURNS ltree AS $$ DECLARE escaped_path ltree; BEGIN select string_agg(escape_part(part), '.') into escaped_path from (select regexp_split_to_table as part from regexp_split_to_table(filename, '/')) as parts;
return escaped_path;
END; $$ LANGUAGE plpgsql IMMUTABLE;
Util: Escape every part
(folder or file)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
createor replace function escape_part(part text) returns text as $$ declare escaped_part text; begin select string_agg(escaped, '') into escaped_part from (selectcasesubstring(sep, 1, 1) ~'[0-9a-zA-Z]' whentruethen sep else'_'|| base62_encode(sep) ||'_' endas escaped from (select split_string_by_alpha as sep from split_string_by_alpha(part)) as split) asescape; RETURN escaped_part; end; $$ language plpgsql immutable
Util: Split a string into
groups
Each group contains only alphabetic characters or non-alphabetic
characters.
CREATEOR REPLACE FUNCTION split_string_by_alpha(input_str TEXT) RETURNS SETOF TEXT AS $$ DECLARE split_str TEXT; BEGIN IF input_str ISNULLOR input_str =''THEN RETURN; END IF;
WHILE input_str !='' LOOP split_str :=substring(input_str from'[^0-9a-zA-Z]+|[0-9a-zA-Z]+'); IF split_str !=''THEN RETURN NEXT split_str; END IF; input_str :=substring(input_str from length(split_str) +1); END LOOP;
RETURN; END; $$ LANGUAGE plpgsql
Util: base62 encode function
By using the base62_encode function, we can create a string that
meets the requirements of LTREE and achieves maximum information
entropy.
CREATEOR REPLACE FUNCTION base62_encode(data TEXT) RETURNS TEXT AS $$ DECLARE ALPHABET CHAR(62)[] :=ARRAY[ '0','1','2','3','4','5','6','7','8','9', 'A','B','C','D','E','F','G','H','I','J', 'K','L','M','N','O','P','Q','R','S','T', 'U','V','W','X','Y','Z','a','b','c','d', 'e','f','g','h','i','j','k','l','m','n', 'o','p','q','r','s','t','u','v','w','x', 'y','z' ]; BASE BIGINT :=62; result TEXT :=''; val numeric :=0; bytes bytea := data::bytea; len INT := length(data::bytea); BEGIN FOR i IN0..(len -1) LOOP val := (val *256) + get_byte(bytes, i); END LOOP;
WHILE val >0 LOOP result := ALPHABET[val % BASE +1] ||result; val :=floor(val / BASE); END LOOP;
Move semantics make it possible to safely transfer resource ownership
between objects, across scopes, and in and out of threads, while
maintaining resource safety. — (since C++11)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
void f() { vector<string> vs(100); // not std::vector: valid() added if (!vs.valid()) { // handle error or exit }
ifstream fs("foo"); // not std::ifstream: valid() added if (!fs.valid()) { // handle error or exit }
// ... } // destructors clean up as usual
C++ 提出了 RAII 这一先进概念,几乎解决了资源安全问题。但是受限于 C++
诞生年代,早期 C++ 为了保证资源安全,只支持左值引用(LValue Reference) +
Clone(Deep Copy)
语义,使得赋值操作会频繁深拷贝整个对象与频繁构造/析构资源,浪费了很多操作。C++11
开始支持右值引用,但是仍然需要实现右值引用(RValue Reference)的
Move(Shallow Copy)。同时,C++ 无法检查多次 move 的问题和 move
后原始变量仍然可用的问题。
Welcome to Hexo! This is your very
first post. Check documentation for
more info. If you get any problems when using Hexo, you can find the
answer in troubleshooting or
you can ask me on GitHub.